







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
读取数据
data = np.genfromtxt(“data.csv”, delimiter=“,”)
x_data = data[:, :-1]
y_data = data[:, -1]
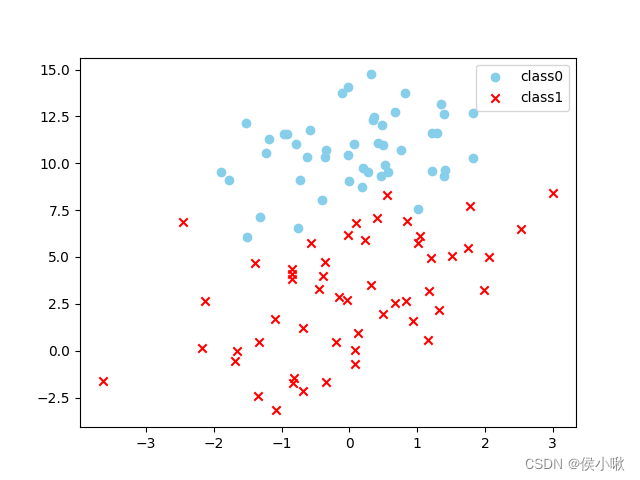
然后定义绘制散点图的函数,为将数据分布更直观地展示:
def plot_logi():
# 初始化列表
x_0 = []
y_0 = []
x_1 = []
y_1 = []
# 分割不同类别的数据
for i in range(len(x_data)):
# 取类别为0的数据
if y_data[i] == 0:
# 将特征1添加到x_0中
x_0.append(x_data[i, 0])
# 将特征2添加到y_0中
y_0.append(x_data[i, 1])
else:
# 将特征1添加到x_1中
x_1.append(x_data[i, 0])
# 将特征2添加到y_1中
y_1.append(x_data[i, 1])
# 画图
plt.scatter(x_0, y_0, c="skyblue", marker="o", label="class0")
plt.scatter(x_1, y_1, c="red", marker="x", label="class1")
plt.legend()
输出数据分布散点图:
plot_logi()
plt.show()
---
第三步,训练模型
logistic = LogisticRegression()
logistic.fit(x_data, y_data)
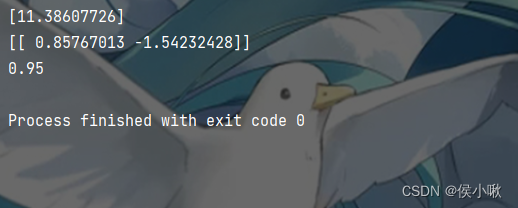
截距
print(logistic.intercept_)
系数:theta1 theta2
print(logistic.coef_)
预测
pred = logistic.predict(x_data)
输出评分
score = logistic.score(x_data, y_data)
print(score)
输出结果如下图所示:
---
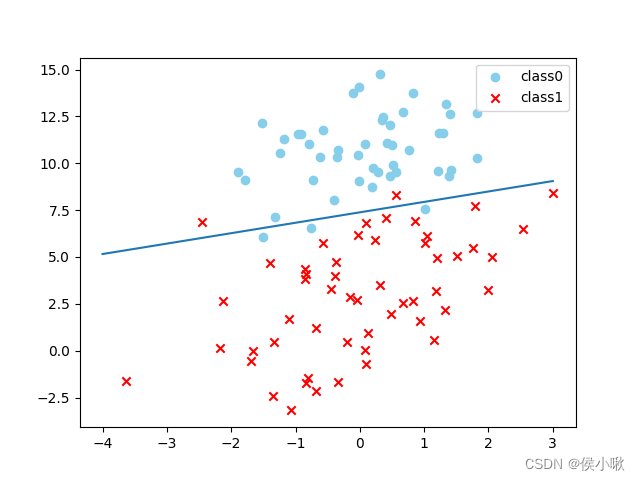
绘制出带有决策边界的散点图:
绘制散点
plot_logi()
绘制决策边界
x_test = np.array([[-4], [3]])
y_test = -(x_test*logistic.coef_[0, 0]+logistic.intercept_)/logistic.coef_[0, 1]
plt.plot(x_test, y_test)
plt.show()
---
## 2.非线性逻辑回归
python实现非线性逻辑回归,首先使用make\_gaussian\_quantiles获取一组高斯分布的数据集,代码及数据分布如下:
import matplotlib.pyplot as plt
from sklearn import linear_model
from sklearn.preprocessing import PolynomialFeatures
from sklearn.datasets import make_gaussian_quantiles
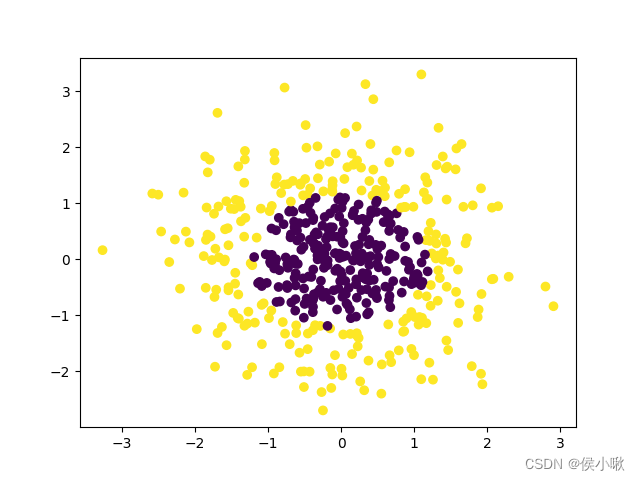
获取高斯分布的数据集,500个样本,2个特征,2分类
x_data, y_data = make_gaussian_quantiles(n_samples=500, n_features=2, n_classes=2)
绘制散点图
plt.scatter(x_data[:, 0], x_data[:, 1],c=y_data)
plt.show()
描述数据分布的散点图如图所示:
---
然后转换数据并训练模型以实现非线性逻辑回归:
数据转换,最高次项为五次项
poly_reg = PolynomialFeatures(degree=5)
x_poly = poly_reg.fit_transform(x_data)
定义逻辑回归模型
logistic = linear_model.LogisticRegression()
logistic.fit(x_poly, y_data)
score = logistic.score(x_poly, y_data)
print(score)
评分结果如图所示,达0.996:

---
## 3.乳腺癌数据集案例
以乳腺癌数据集为例,建立线性逻辑回归模型,并输出准确率,精确率,召回率三大指标,代码如下所示:
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings(“ignore”)
获取数据
cancer = load_breast_cancer()
分割数据
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2)
创建估计器


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
291)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









