






终于受不了有道云笔记了...然而印象+马克飞象的组合是要收费的呵呵哒,那就干脆来cnblog写笔记好了。
Problem
问题还是那个问题,推荐系统万变不离其宗:
给定一个用户的历史check-in行为数据,以及该用户当前的时空坐标$(l,\tau)$,然后推荐用户最可能感兴趣的$Top-k$的POIs. 其中用户的位置$l$被映射到了某一region,时间$\tau$被映射到了某一time slot,以便于找到它们的embedding表示。
后文会解释时间片和区域时如何做embedding的。
Challenges
- 数据稀疏性:这里的稀疏,是相对于传统的电影、音乐、商品等推荐系统而言的。其一,相较于前者,POI的访问需要物理世界中的移动、消费,时间和物质成本都要更高;其二,即使用户访问了某POI,也有可能因为隐私、安全的考虑而不产生签到(评价)行为,甚至我认为当用户对POI的体验比较中庸——既不喜欢也不讨厌——的时候,他们也有可能懒得签到(评价)。
- Context Awareness:翻译成“对环境的感知性”比较合适,就是说做POI推荐时,用户的时空位置对推荐的影响更大一些。
- 冷启动:传统推荐系统中的cold start分为用户和商品两种,这里的冷启动对应后者,即POI的冷启动问题。每天都会有新的POIs被添加到数据库中,他们没有被用户访问过。
- 用户偏好的动态性:文章给的例子是,当一个用户有孩子之前和之后,他对POI的喜好会发生重大变化。这个观点的intuition来自于和电影、音乐推荐系统的比较,因为这类更加反映用户精神偏高、高层次需求的商品,受到生活节奏变化的影响会比较小。但POI这类明显更“接地气”的商品,更会随着用户在物理世界中的活动而变化。
Factors/Features exploited
做POI推荐时利用到的特征也是近几年常用的几种。
- 签到顺序:用户在POIs之间的迁移,往往表现出一定的顺序规律。
- 地理位置:用户当然更倾向于访问位置更近的POI。
- 时间周期性:也好理解,一个人在一天中,早晨吃早饭赶公交,中午吃午饭,晚上购物娱乐回家,访问的POI具有按天的周期性;周中家、公司、餐厅三点一线,周末去公园、健身房,又具有周的周期性。
- POI语义:作者从别人的研究中发现, 用户访问的POIs之间,存在语义(功能、性质等)上的相似性,这是废话,但可能很有用。
Important Notations
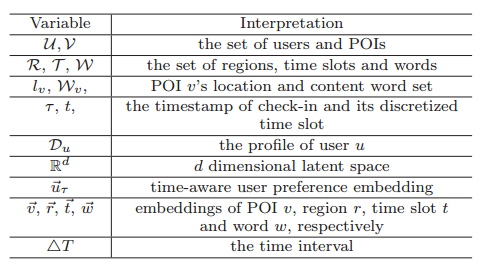 这里面需要解释一下的是$W_v$,每个POI都会有分类、标签,这些词就构成了该POI的word set. 其余的notations均可通过表格理解。
这里面需要解释一下的是$W_v$,每个POI都会有分类、标签,这些词就构成了该POI的word set. 其余的notations均可通过表格理解。
Concepts of the 4 Graphs
作者用一个有向图、三个二部图描述了POI-POI、POI-Region、POI-Time、POI-Word之间的关系,其中POI-POI的有向图也可以构造成一个二部图。 
- POI-POI Graph:有向图,用来描述用户访问POIs的顺序规律。图中,一个节点代表一个POI,如果用户依次连续访问了$POI_1,POI_2$,并且两次访问的时间间隔没有超过阈值$\Delta T$,那么在节点$v_1,v_2$之间添加一条指向后者的边,边的权重是这个pattern出现的次数。可以理解,时间间隔阈值$\Delta T$是一个时效性限制,如果两次访问间隔太久,那么没有什么规律性可言。
- POI-Region Graph:二部图,直接描述的是POI是否归属于某个区域;结合embedding,它最终描述的是,当用户处于区域$r_j$时,访问POI $v_i$的可能性。二部图左侧节点是regions,右侧节点是POIs,如果POI归属于某region,那么它们的节点之间添加一条连线,并且权重值就是1.
- POI-Time Graph:二部图,直接描述的是用户在时间片$t_j$内访问POI $v_i$的频率。二部图左侧节点是time slots,右侧节点是POIs,如果在时间片$t_j$内有POI $v_i$的访问记录,就连一条边,权重就是访问的次数。
- POI-Word Grapg:二部图,描述的是POI的词汇集$W_$与所有词汇的关系。二部图左侧是词汇全集,右侧是POIs,如果某词汇出现在$W_$当中,那么它和$v_j$间添加一条边。边的权重要靠tf.idf方法来计算,有时间再写。注意,文章中的标号可能有问题,应该把$D_$替换为$W_$,才能对应到表格中定义的notation.
Graph Embedding Model
- Bipartite Graph Embedding 如上文所言,将POI-POI的有向图也转换为二部图之后,我们手里面就有了四张二部图,因此它们做embedding的形式就可以统一。对于二部图中左、右侧的节点,我们分别用embedding vector $v_i,v_j$来表示。 接下来,我们构造两种分布,来描述二部图左侧节点$v_i\in V_A$、右侧节点$v_j\in V_B$的关系,首先是:
最小化目标 总体思路就是,令上面构造的两种分布的$KL-Divergence$尽可能小,公式如下:
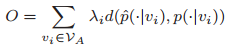 其中$d(\cdot | \cdot)\(代表KL-Divergence,\)\lambda_i$表示节点$v_i$的重要程度,在此我们以$deg_i=\sum_j w_$表示,即节点$v_i$处所有边的权重之和。上式可整理为
其中$d(\cdot | \cdot)\(代表KL-Divergence,\)\lambda_i$表示节点$v_i$的重要程度,在此我们以$deg_i=\sum_j w_$表示,即节点$v_i$处所有边的权重之和。上式可整理为  通过优化目标函数,我们可以学习到最优的$v_i$,得到POIs、regions、time slots、words的最佳embedding vector表示,这些嵌入向量,就是该模型的最终产出。
通过优化目标函数,我们可以学习到最优的$v_i$,得到POIs、regions、time slots、words的最佳embedding vector表示,这些嵌入向量,就是该模型的最终产出。优化策略 **优化的过程,就是所谓的“嵌入”的过程。**事实上,我们有四张二部图的embedding模型需要优化,最符合直觉的学习策略,就是将四张图的向量嵌入过程合并,即构造一个新的目标函数:
 其中
其中 
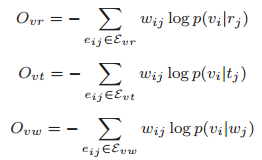 优化的过程涉及到了negative sampling,有时间可以整理一下。 最终,我们得到的是${v_i}, i=1,2,...,|V|\(,\){r_i},i=1,2,...,|R|\(,\){t_i},i=1,2,...,|T|\(,以及\){w_i},i=1,2,...,|W|$. 至此,我们就得到了各POI、各区域、各时间片、各个描述POI的词汇的“嵌入向量”,在同一个embedding空间中来表征这些不同的要素。
优化的过程涉及到了negative sampling,有时间可以整理一下。 最终,我们得到的是${v_i}, i=1,2,...,|V|\(,\){r_i},i=1,2,...,|R|\(,\){t_i},i=1,2,...,|T|\(,以及\){w_i},i=1,2,...,|W|$. 至此,我们就得到了各POI、各区域、各时间片、各个描述POI的词汇的“嵌入向量”,在同一个embedding空间中来表征这些不同的要素。用户偏好的表征 系统的数据库中,记录着用某户访问过的POI,及其时间戳信息。这里,作者将这些用户访问过POI的嵌入向量求加权和,用加权和来表示用户对POIs的偏好:
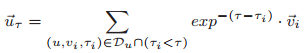 其中的权重,是一个时间衰减因子,可以看出用户访问POI时间越早,则该POI的嵌入向量权重越小,反之访问时刻离现在越近,那么该POI权重越大。
其中的权重,是一个时间衰减因子,可以看出用户访问POI时间越早,则该POI的嵌入向量权重越小,反之访问时刻离现在越近,那么该POI权重越大。用Graph Embedding Model推荐POI 终于,我们来到了收获的时刻。用之前构造的四类嵌入向量,以及用户偏好描述,我们可以对单个用户对每个POI的感兴趣程度打分:
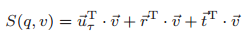 之后,按分数降序排序,得到分数最高的$k$个点,作为推荐的POIs.
之后,按分数降序排序,得到分数最高的$k$个点,作为推荐的POIs.
Experiment and Conclusion
关于测试结果,比较有价值的是作者通过实验,定量地给出了各个Feature对POI推荐准确率的影响(贡献),文章给出的结果是:\(Sequential\gt Temporal\gt Content\gt Geographical\). 这一点对于该领域后续的工作有很强的指导意义。 读完文章再回顾,在我看来它的Contributions主要就是:用四个二部图模型,将POI check-in sequential patterns、check-in frequency in different time slots、distributions of in different regions、semantic contents of POIs这些用来做推荐的feature,embed到同一个低维空间中,分别得到向量表示。这样一来,不仅方便了表示用户的偏好,也方便了对“用户-POI”的关联度打分,从而便捷地得到推荐结果。
###Todo List
- tf.idf
- negative sampling
Reference
Xie M, Yin H, Wang H, et al. Learning graph-based poi embedding for location-based recommendation[C]//Proceedings of the 25th ACM International on Conference on Information and Knowledge Management. ACM, 2016: 15-24.
欢迎转载交流,请注明出处。















 781
781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









