







本文介绍一个基于pytorch的电影推荐系统。
代码移植自https://github.com/chengstone/movie_recommender。
原作者用了tf1.0实现了这个基于movielens的推荐系统,我这里用pytorch0.4做了个移植。
本文实现的模型Github仓库:https://github.com/Holy-Shine/movie_recommend_system
1. 总体框架
先来看下整个文件包下面的文件构成:
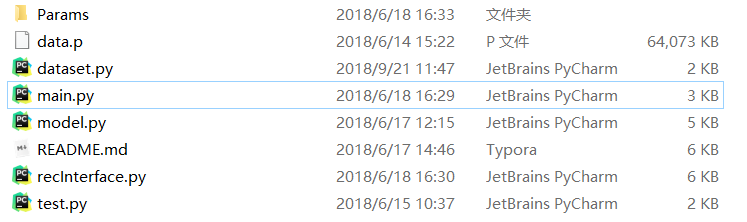
其中:
Params: 保存模型的参数文件以及模型训练后得到的用户和电影特征向量
data.p:保存了训练和测试数据
dataset.py:继承于pytorch的Dataset类,是一个数据batch的generator
model.py:推荐系统的pytorch模型实现
main.py:主要的训练过程
recInterface.py: 推荐系统训练完毕后,根据模型的中间输出结果作为电影和用户的特征向量,这个推荐接口根据这些向量的空间关系提供一些定向推荐结果
test.py: 无用,纯用来测试输入维度是否和模型match
2. 数据集接口dataset.py
dataset.py 加载 data.p 到内存,用生成器的方式不断形成指定batch_size大小的批数据,输入到模型进行训练。我们先来看看这个data.p 长什么样。
data.p 实际上是保存了输入数据的pickle文件,加载完毕后是一个pandas(>=0.22.0)的DataFrame对象(如下图所示)

用下面代码可以加载和观察数据集(建议使用 jupyternotebook )
import pickle as pkl
data = pkl.load(open('data.p','rb'))
data下面来看看数据加载类怎么实现:
class MovieRankDataset(Dataset):
def __init__(self, pkl_file):
self.dataFrame = pkl.load(open(pkl_file,'rb'))
def __len__(self):
return len(self.dataFrame)
def __getitem__(self, idx):
# user data
uid = self.dataFrame.ix[idx]['user_id']
gender = self.dataFrame.ix[idx]['user_gender']
age = self.dataFrame.ix[idx]['user_age']
job = self.dataFrame.ix[idx]['user_job']
# movie data
mid = self.dataFrame.ix[idx]['movie_id']
mtype=self.dataFrame.ix[idx]['movie_type']
mtext=self.dataFrame.ix[idx]['movie_title']
# target
rank = torch.FloatTensor([self.dataFrame.ix[idx]['rank']])
user_inputs = {
'uid': torch.LongTensor([uid]).view(1,-1),
'gender': torch.LongTensor([gender]).view(1,-1),
'age': torch.LongTensor([age]).view(1,-1),
'job': torch.LongTensor([job]).view(1,-1)
}
movie_inputs = {
'mid': torch.LongTensor([mid]).view(1,-1),
'mtype': torch.LongTensor(mtype),
'mtext': torch.LongTensor(mtext)
}
sample = {
'user_inputs': user_inputs,
'movie_inputs':movie_inputs,
'target':rank
}
return samplepytorch要求自定义类实现三个函数:
__init__()用来初始化一些东西__len__()用来获取整个数据集的样本个数__getitem(idx)__根据索引idx获取相应的样本
重点看下__getiem(idx)__,主要使用dataframe的dataFrame.ix[idx]['user_id']来获取相应的属性。由于整个模型是用户+电影双通道输入,所以最后将提取的属性组装成两个dict,最后再组成一个sample返回。拆解过程在训练时进行。(组装时提前用torch.tensor()将向量转为pytorch支持的tensor张量)
3. 推荐模型model.py
先看一下我们要实现的模型图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 693
693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









