







 本文详细介绍了C++11中的新特性,包括`auto`关键字简化类型推断,`nullptr`替代NULL,新增STL容器如`std::array`和`std::unordered_map`,多线程支持如`std::thread`和`std::atomic`,以及右值引用和`std::move`提升效率。此外,还讨论了`std::forward`在参数传递中的完美转发作用。
本文详细介绍了C++11中的新特性,包括`auto`关键字简化类型推断,`nullptr`替代NULL,新增STL容器如`std::array`和`std::unordered_map`,多线程支持如`std::thread`和`std::atomic`,以及右值引用和`std::move`提升效率。此外,还讨论了`std::forward`在参数传递中的完美转发作用。
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取:
https://www.cnblogs.com/bclshuai/p/11380657.html
目录
1 C++11新特性
1.1 关键字和新语法
1.1.1 auto关键字
1.1.2 空指针关键字nullptr
1.2 新增STL容器
1.2.1 std::array数组
1.2.2 std::forward_list
1.2.3 std::unordered_map无序哈希map
1.2.4 std::unordered_set无序容器
1.3 多线程
1.3.1 std::thread类
1.3.2 自带锁的原子性变量std::atomic
1.3.3 条件等待std::condition_variable
1.4 智能指针std::shared_ptr
1.4.1 std::shared_ptr
1.4.2 std::weak_ptr
1.4.3 std::function、std::bind
1.5 右值引用和move
1.5.1 定义
1.5.2 右值引用的作用
1.5.3 深拷贝代码实例
1.5.4 右值引用实现转移构造函数和转移赋值操作符重载
1.5.5 std::move将不在使用的变量转换为右值引用
1.5.6 提高交换函数的性能
1.5.7 总结
1.6 std::forward参数传递的完美转发
1.6.1 std::forward作用
1.6.2 实例说明
1.6.3 std::forward原理剖析
1.6.4 总结
1 C++11新特性
1.1 关键字和新语法
1.1.1 auto关键字
自动变量推导,用auto去定义变量,会根据赋值去自动推导变量类型。不用在去根据数据类型去定义变量。
例如
auto AddTest(int a, int b)
{
return a + b;
}
int main()
{
auto index = 10;
auto str = "abc";
auto ret = AddTest(1,2);
std::cout << "index:" << index << std::endl;
std::cout << "str:" << str << std::endl;
std::cout << "res:" << ret << std::endl;
}
输出

但是auto不能在类定义中声明函数
class Test
{
public:
auto TestWork(int a ,int b);
};
auto变量也可以作为STL容器的迭代器,放入for循环中去使用。
int main()
{
int numbers[] = { 1,2,3,4,5 };
std::cout << "numbers:" << std::endl;
for (auto number : numbers)
{
std::cout << number << std::endl;
}
}
1.1.2 空指针关键字nullptr
NULL的宏定义是0,但是0是一个整数,如果重载函数形参为int* n和int n,如果传入NULL不知道是调用哪个重载函数。nullptr就是空指针的,这样就会调用int* n。
class Test
{
public:
void TestWork(int index)
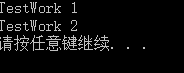
{
std::cout << "TestWork 1" << std::endl;
}
void TestWork(int * index)
{
std::cout << "TestWork 2" << std::endl;
}
};
int main()
{
Test test;
test.TestWork(NULL);
test.TestWork(nullptr);
}
输出
1.2 新增STL容器
1.2.1 std::array数组
std::array和数组一样是存储在栈上,封装了一些函数,size(),Empty(),front,back(), at(),访问可以避免越界。而vector是存储在堆上,所以array的访问速度更快。std::array定义时固定长度,和数组一样,vector是变动长度。
实例代码
#include <array>
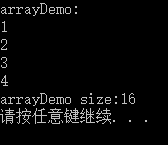
int main()
{
std::array<int, 4> arrayDemo = { 1,2,3,4 };
std::cout << "arrayDemo:" << std::endl;
for (auto itor : arrayDemo)
{
std::cout << itor << std::endl;
}
int arrayDemoSize = sizeof(arrayDemo);
std::cout << "arrayDemo size:" << arrayDemoSize << std::endl;
return 0;
}
输出结果
1.2.2 std::forward_list
内部实现是单向链表, list是双向链表,单向链表只有一个方向的指针,所以反向操作不支持,在尾部插入和删除的操作不支持,例如push_back(),back(),因为是单向,所以从头部插入和删除元素效率更高,且节省保存反向指针的空间。也不支持size()函数,这也是为了增加效率,可以通过distance(c.begin(),c.end())来得到forward_list的大小,这将消耗一个线性时间。链表相对于vector内部实现为数组,插入和删除效率更高。
示例代码:
#include <forward_list>
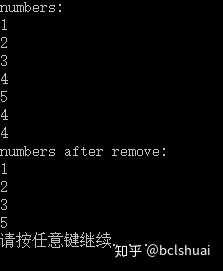
int main()
{
std::forward_list<int> numbers = {1,2,3,4,5,4,4};
std::cout << "numbers:" << std::endl;
for (auto number : numbers)
{
std::cout << number << std::endl;
}
numbers.remove(4);
std::cout << "numbers after remove:" << std::endl;
for (auto number : numbers)
{
std::cout << number << std::endl;
}
return 0;
}
输出结果
1.2.3 std::unordered_map无序哈希map
std::unordered_map与std::map用法基本差不多,但STL在内部实现上有很大不同,std::map使用的数据结构为二叉树,而std::unordered_map内部是哈希表的实现方式,哈希map理论上查找效率为O(1)。但在存储效率上,哈希map需要增加哈希表的内存开销。哈希内部实现是数组,hash算法得出键在数组中的索引值,然后直接存入数组的对应位置,取数据时也是计算索引值,然后根据索引值直接访问数组的元素。但是存在hash冲突的问题,可以通过四种方法:开发地址法:线性探测、再平方探测、伪随机探测,链式地址法,建立公共溢出区,再哈希法。参考文献:https://www.cnblogs.com/higerMan/p/11907117.html
使用实例
//webset address: http://www.cplusplus.com/reference/unordered_map/unordered_map/bucket_count/
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
std::unordered_map<std::string, std::string> mymap =
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









