






简介
决策树类似于下图这种if-then 结构的判断算法。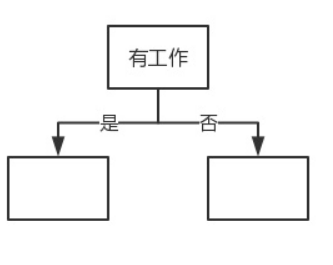
必要的数学概念:
1.信息熵:度量信息混乱程度的一个概念,越混乱熵就越大,在概率论中用数学期望表示,在机器学习中按一下公式定义 ,所以信息熵是0-log2|y|之间的值
,所以信息熵是0-log2|y|之间的值
2.信息增益:用来度量某个特征对整个分类结果影响大小的量,实质是熵与特征条件熵的差,某个特征的信息增益越大,就说明这个特征越重要。*选取信息增益最大的特征可以作为划分特征的依据(ID3算法,不具备泛化能力,不能对新数据进行分类)。计算公式书本这么写的
3.增益率:信息增益偏向于特征取值多的那个特征,取值多会使得复杂、熵变大,因此求比值可以抵消这种复杂度。特点是偏向选择特征数目少的特征,因此划分特征的时候选择信息增益高于平均水平特征中的增益比最大那个特征,而不是选择增益比最大的(C4.5算法),公式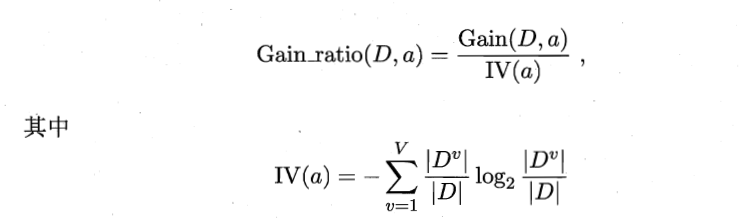
4.基尼指数:类似于信息熵的一种计算方法,在CART算法中使用,公式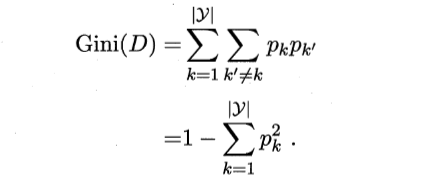
ID3算法书本实例计算信息熵和信息增益:我们拥有这样一个判断西瓜好不好的数据集
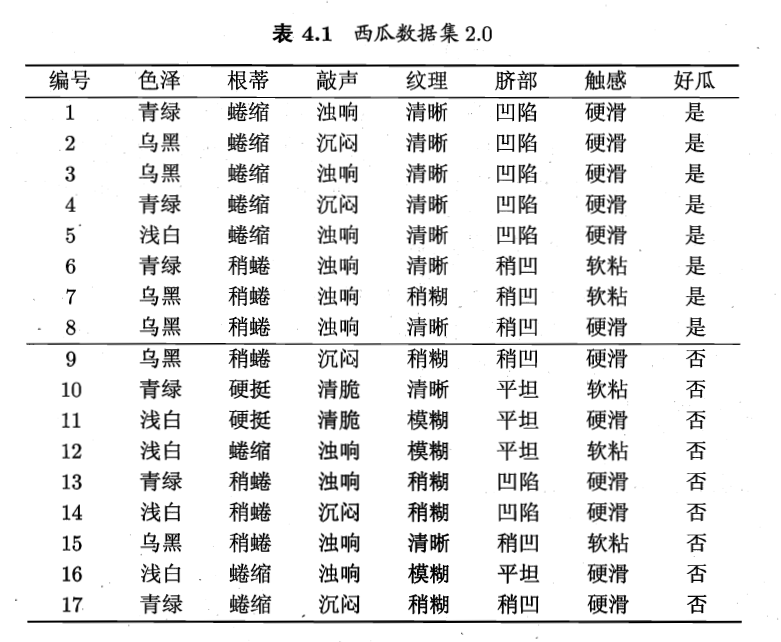
计算整体的信息熵, Pk 的取值是根据正负样本来取值的,也就是整体的信息熵计算中Pk看的是标签(最终结果),正样本为8/17,负样本是9/17.
然后计算某个特征信息熵的时候,它是建立在正负样本的基础上的,于是就比如色泽有三种,就拿青绿来举例子,正样本中为3个,负样本也是三个,所以他的正负样本均是3/6。所以整体这个数据集中信息增益的计算过程如下显示。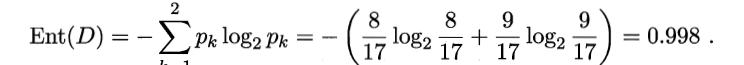

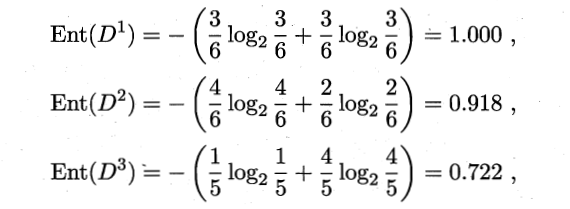
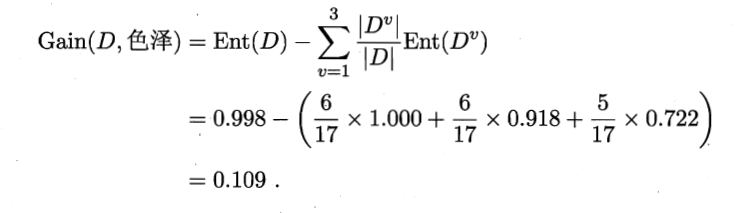
其他特征的信息增益计算同理可得
于是得出纹理的信息增益最大,于是纹理这个特征就可以被选择为划分特征的属性。于是就可以画出下图所示的决策树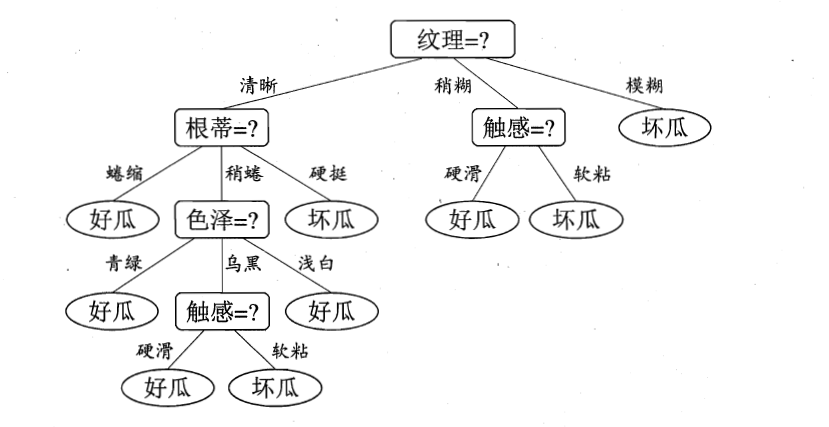
ID3算法的代码实现
1、创建数据集
def createDataSet(): #创建的数据集是列表套列表构成的二维数组
dataSet = [[0, 0, 0, 0, 'no'],
[0, 0, 0, 1, 'no'],
[2, 0, 0, 0, 'no']]
labels = ['年龄', '房子', '工作', '车子'] #labels存放的是特征的中文对应名称
return dataSet, labels #返回数据集和特征名称2、计算信息熵
from math import log
def calcShannonEnt(dataSet):
numEntires = len(dataSet) #因为是列表套列表,所以可以使用len返回行数
labelCounts = {} #声明标签字典,存放每个标签及其数值
for featVec in dataSet: #对每一项训练集遍历,获取他们的标签并计数,然后加入字典
currentLabel = featVec[-1] #提取标签(Label)信息
if currentLabel not in labelCounts.keys(): #如果标签(Label)没有放入统计次数的字典,添加进去
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #Label计数
shannonEnt = 0.0 #经验熵(香农熵)
for key in labelCounts: #计算香农熵
prob = float(labelCounts[key]) / numEntires #选择该标签(Label)的概率
shannonEnt -= prob * log(prob, 2) #利用公式计算,用循环完成求和运算
return shannonEnt 3、划分数据集(每个特征都作为一次划分依据,而一个特征是有多种value的(比如色泽的乌黑、青绿、浅白),划分数据集最重要的作用一是在计算信息增益的时候,统计某个特征某个值得数量,作用二是在构建决策树的时候,递归时删除已经使用的特征)
def splitDataSet(dataSet, axis, value):
"""
dataSet:数据集
axis:划分数据集的特征
value:axis特征的几种值
"""
retDataSet = [] #创建返回的数据集列表
for featVec in dataSet: #遍历数据集
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:]) #这两个语句,最终结果就是去掉了列表中的axis特征,把要选取的那个特征单独拎出来
retDataSet.append(reducedFeatVec) #注意append与extend方法有所区别,均是添加上去,但是append是整个添加,extend是去列表框然后添加
return retDataSet 4、分别计算信息增益,选取最优的划分方法
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #特征数量(去掉最后的标签)
baseEntropy = calcShannonEnt(dataSet) #计算数据集的香农熵
bestInfoGain = 0.0 #信息增益基本值(作用是后面比较选出最大的增益值)
bestFeature = -1 #最优特征的索引值
for i in range(numFeatures): #遍历所有特征
featList = [example[i] for example in dataSet] #提取出整个二维矩阵中的一列特征,用for遍历所有特征,分别计算
uniqueVals = set(featList) #创建set集合{},元素不可重复
newEntropy = 0.0 #经验条件熵
for value in uniqueVals: #计算信息增益
subDataSet = splitDataSet(dataSet, i, value) #划分集合
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet) #这两句计算特征条件熵,然后for遍历完就求完和了
infoGain = baseEntropy - newEntropy #信息增益=信息熵-信息条件熵
print("第%d个特征的增益为%.3f" % (i, infoGain)) #打印每个特征的信息增益
if (infoGain > bestInfoGain): #比较信息增益,选出最大
bestInfoGain = infoGain #更新信息增益,找到最大的信息增益
bestFeature = i #记录信息增益最大的特征的索引值(返回的是索引)
return bestFeature5、构建决策树(选择完最优方案后构建决策树)
def majorityCnt(classList): #用于挑选出现次数最多的函数,当数据集就一列数据的时候需要使用到
classCount = {}
for vote in classList: #统计classList中每个元素出现的次数
if vote not in classCount.keys():classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True) #将字典变成列表,使用sorted()逆序排序,取出次数最多的元素
return sortedClassCount[0][0] #返回classList中出现次数最多的元素
def createTree(dataSet, labels, featLabels):
classList = [example[-1] for example in dataSet] #获取数据集的标签
if classList.count(classList[0]) == len(classList): #相同标签就跳出递归,因为剩下的相同结果一定是指向同一节点的
return classList[0]
if len(dataSet[0]) == 1 or len(labels) == 0: #如果数据集只有一列数据或者特征用完时候,就跳出递归
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet) #获取最优的特征划分方式的特征的索引
bestFeatLabel = labels[bestFeat] #获取最优特征的标签
featLabels.append(bestFeatLabel)
myTree = {bestFeatLabel:{}} #根据获得的最优特征标签名构建第一个节点
del(labels[bestFeat]) #删除已经使用特征标签
featValues = [example[bestFeat] for example in dataSet] #获得该最优特征的所有值
uniqueVals = set(featValues) #去掉重复的属性值
for value in uniqueVals: #遍历特征的值,创建决策树。
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), labels, featLabels) #递归调用函数本身,循环得出后续节点
return myTree
#在这个递归中,跳出递归的条件是特征用完,或者结果标签全部一致,也就是上述代码中的两个if语句
#最终返回一个字典套字典的决策树,形如:{'有房子':{0:{'有工作':{0:'no',1:'yes'}},1:'yes'}}6.使用matlib可视化决策树
过程:获取决策树的节点数->获取决策树层数->绘制注释节点->绘制方向线上的注释 -> 绘制决策树
def getNumLeafs(myTree): #获得节点数量
numLeafs = 0 #初始化叶子
firstStr = next(iter(myTree)) #迭代字典获取第一个健,也就是第一个节点
secondDict = myTree[firstStr] #获取内嵌的字典
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict': #判断该结点是否为字典,如果不是字典则此结点为最深层的最后一个节点,节点数加一,如果是字典就递归调用,并且节点数加一
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
def getTreeDepth(myTree): #获得树的深度
maxDepth = 0 #初始化决策树深度
firstStr = next(iter(myTree)) #iter迭代得到第一个字符节点
secondDict = myTree[firstStr] #获取下一个字典
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict': #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1 #(书本这边是1,个人感觉应该设个在if下设置个i++,然后这边是i+1,还没想通我再想想)
if thisDepth > maxDepth: maxDepth = thisDepth #更新层数
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType): #定义注释节点,(就是一个箭头注释图标,注释的描述内容在箭头那端)
"""
nodeTxt - 结点名(str型)
centerPt - 文本位置
parentPt - 标注的箭头位置
nodeType - 结点格式
"""
arrow_args = dict(arrowstyle="<-") #定义箭头格式的字典
createPlot.ax1.annotate(nodeText,xy=parentPt,xycoords = 'axes fraction',xytext = centerPt,textcoords = 'axes fraction',va = "center",ha = "center",bbox = nodeType,arrowprops = arrow_args) #绘制带箭头的注释,node Text: 节点的名字, xy: 被注解的东西的位置, xycoords:被注解的东西依据的坐标原点位置,xytext: 注解内容的中心坐标,textcoords:注解内容依据的坐标原点位置,va与ha表示稳重的竖向与横向的对其方式, arrowprops: 标记线的类型(字典类型),bbox: 对方框的设置
def plotMidText(cntrPt, parentPt, txtString): #标注有向性属性值(就是箭头上面的字)
"""
cntrPt、parentPt - 用于计算标注位置
txtString - 标注的内容
"""
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0] #计算标注位置 (利用子父节点的坐标值,计算这个标注内容的 坐标)
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt): #上面四步完成各个部分的定义后就可以绘制决策树了
decisionNode = dict(boxstyle="sawtooth", fc="0.8") #设置结点格式
leafNode = dict(boxstyle="round4", fc="0.8") #设置叶结点格式
numLeafs = getNumLeafs(myTree) #获取决策树叶结点数目,决定了树的宽度
depth = getTreeDepth(myTree) #获取决策树层数
firstStr = next(iter(myTree)) #下个字典
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff) #中心位置,plotTree.xOff与plotTree.yOff是creattree函数中定义的一个变量
plotMidText(cntrPt, parentPt, nodeTxt) #标注有向边属性值
plotNode(firstStr, cntrPt, parentPt, decisionNode) #绘制结点
secondDict = myTree[firstStr] #下一个字典,也就是继续绘制子结点,同时也是递归条件,通过下一个字典判断是否递归
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD #y偏移?
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict': #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点
plotTree(secondDict[key],cntrPt,str(key)) #不是叶结点,递归调用继续绘制
else: #如果是叶结点,绘制叶结点,并标注有向边属性值
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
def createPlot(inTree): #创建画布,开始绘图,相当于绘图这一操作的主函数
fig = plt.figure(1, facecolor='white') #创建fig
fig.clf() #清空fig
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #去掉x、y轴 ?
plotTree.totalW = float(getNumLeafs(inTree)) #获取决策树叶结点数目
plotTree.totalD = float(getTreeDepth(inTree)) #获取决策树层数
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; #x偏移
plotTree(inTree, (0.5,1.0), ' ') #绘制决策树
plt.show() 7.决策树的存储
import pickle
def storeTree(inputTree, filename): #存储
with open(filename, 'wb') as fw:
pickle.dump(inputTree, fw)
def grabTree(filename): #加载打开
fr = open(filename, 'rb')
return pickle.load(fr)CART 算法代码
C4.5算法代码
python 语法注意点
set()方法:创建无序不重复元素集合,因此在ID3算法中可以使用这种方法,消去重复特征
append(list)与extend(list):append是直接将list添加进去(包括[ ]),而extend是添加将list中的元素添进去。
变量定义:在绘图中plotTree.xOff,存在plotTree的情况下,可以plotTree.xOff定义变量















 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









