






常用模块学习
一、time & datetime
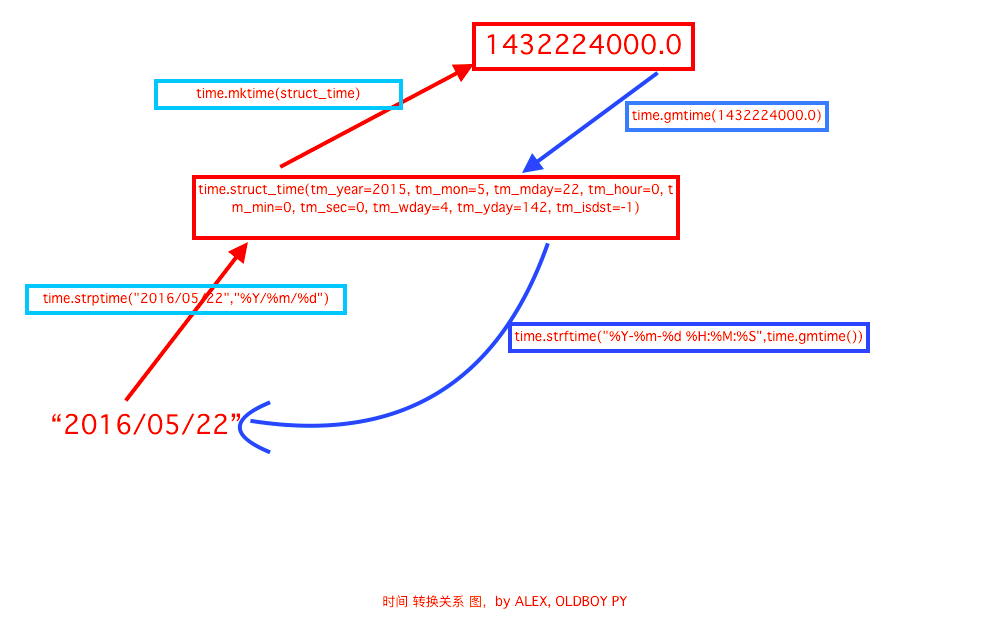
import time
now = time.time()
print(now)
now_gm = time.gmtime(now)
print(now_gm)
now_strf = time.strftime("%Y-%m-%d %H:%M:%S", now_gm)
print(now_strf)
now_gm2 = time.strptime(now_strf, "%Y-%m-%d %H:%M:%S")
print(now_gm2)
now2 = time.mktime(now_gm2)
print(now2)
"""
输出结果:
1537259285.146801
time.struct_time(tm_year=2018, tm_mon=9, tm_mday=18, tm_hour=8, tm_min=28, tm_sec=5, tm_wday=1, tm_yday=261, tm_isdst=0)
2018-09-18 08:28:05
time.struct_time(tm_year=2018, tm_mon=9, tm_mday=18, tm_hour=8, tm_min=28, tm_sec=5, tm_wday=1, tm_yday=261, tm_isdst=-1)
1537230485.0
"""
import datetime
import time
print(datetime.datetime.now())
now = datetime.datetime.fromtimestamp(time.time())
print(now)
tomorrow = datetime.datetime.now() + datetime.timedelta(days=-2, hours=-1, minutes=-3)
print(tomorrow)
a = datetime.datetime.now()
c = a - tomorrow
c_time = tomorrow + c
print(type(c))
print(c)
print(c_time)
二、random 模块
import random
"""
for i in range(10):
print(random.randint(1, 3)) # 随机数包含1和3
print(random.random()) # 0-1之前的随机小数
print(random.randrange(1, 3)) # 随机1,2 不包括3
"""
check_code = ''
for i in range(4):
current = random.randrange(4)
if current != i:
temp = chr(random.randrange(65, 90))
else:
temp = str(random.randint(0, 9))
check_code += temp
print(check_code)
三、os 模块
# os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
# os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
# os.curdir 返回当前目录: ('.')
# os.pardir 获取当前目录的父目录字符串名:('..')
# os.makedirs('dirname1/dirname2') 可生成多层递归目录
# os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
# os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
# os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
# os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
# os.remove() 删除一个文件
# os.rename("oldname","newname") 重命名文件/目录
# os.stat('path/filename') 获取文件/目录信息
# os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
# os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
# os.pathsep 输出用于分割文件路径的字符串
# os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
# os.system("bash command") 运行shell命令,直接显示
# os.environ 获取系统环境变量
# os.path.abspath(path) 返回path规范化的绝对路径
# os.path.split(path) 将path分割成目录和文件名二元组返回
# os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
# os.path.basename(path) 返回path最后的文件名。如果path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
# os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
# os.path.isabs(path) 如果path是绝对路径,返回True
# os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
# os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
# os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
# os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
# os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
四、sys 模块
import sys
print(sys.argv) # 输出参数list, list[0]是文件名
for i in range(len(sys.argv)):
print(sys.argv[i])
print(sys.version)
print(sys.path)
print(sys.platform)
sys.stdout.write('hello\n')
五、shutil 模块
import os
import shutil
"""
os.removedirs('a/b')
os.makedirs('a/b')
shutil.copyfile('datetime_model.py', 'a/b/1.txt') # 拷贝文件
shutil.copyfileobj() # 将文件内容拷贝到另一个文件中,可以部分内容 copyfileobj 是IO流
shutil.copymode('src', 'dst') # 仅拷贝权限。内容、组、用户均不变
shutil.copystat('src', 'dst') # 拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copy('src', 'dst') # copy文件和权限
shutil.copy2('src,', 'dst') # copy文件和状态
shutil.copytree('a', 'b', ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) # 递归的去拷贝文件 ignore copy时忽略某些文件
shutil.rmtree('b', ignore_errors=True) # 递归的去删除文件
shutil.move('src', 'dst') # 递归地移动文件,目录
shutil.make_archive('c', 'gztar', root_dir='c') # 创建压缩包并返回文件路径,例如:zip、tar
# 创建压缩包并返回文件路径,例如:zip、tar
# base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
# 如:www =>保存至当前路径
# 如:/Users/wupeiqi/www =>保存至/Users/wupeiqi/
# format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
# root_dir: 要压缩的文件夹路径(默认当前目录)
# owner: 用户,默认当前用户
# group: 组,默认当前组
# logger: 用于记录日志,通常是logging.Logger对象
shutil.unpack_archive('c.tar.gz', 'd', 'gztar') # 解压,unpack_archive(filename, extract_dir=None, format=None):
print(shutil.get_unpack_formats()) # 获取支持的格式
"""
六、json & pickle 模块
import json
data = {
'name': 'glen',
'age': 22,
'hobby': 'sleep'
}
data_str = json.dumps(data)
print(data_str)
with open('user', 'w') as f:
f.write(data_str)
with open('user', 'r') as f:
data2 = json.loads(f.read())
print(type(data2))
import pickle
data1 = [1, 3, 4, '5', 'aa']
data2 = {
'name': 'glen',
'age': 23
}
with open('fun', 'wb') as f: # 需要以wb模式
f.write(pickle.dumps(data2))
with open('fun', 'rb') as f:
print(pickle.loads(f.read()))
七、shelve 模块
import shelve
d = shelve.open('shelve_test')
class Animal(object):
def __init__(self, n):
self.n = n
# a = Animal(123)
# a2 = Animal(456)
#
# name = ['glen', 'jack', 'alis']
#
# d['name'] = name
# d['a'] = a
# d['a2'] = a2
print(d['name'])
print(d['a'].n)
八、xml 模块
import xml.etree.ElementTree as ET
# tree = ET.parse('xml_test')
# root = tree.getroot()
# print(root.tag)
# for child in root:
# print(child.tag, child.attrib)
# for i in child:
# print(i.tag, i.text)
# for node in root.iter('year'):
# print(node.tag, node.text)
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml, "name", attrib={"enrolled": "yes"})
age = ET.SubElement(name, "age", attrib={"checked": "no"})
sex = ET.SubElement(name, "sex")
sex.text = '33'
name2 = ET.SubElement(new_xml, "name", attrib={"enrolled": "no"})
age = ET.SubElement(name2, "age")
age.text = '19'
et = ET.ElementTree(new_xml) # 生成文档对象
et.write("test.xml", encoding="utf-8", xml_declaration=True)
ET.dump(new_xml) # 打印生成的格式
九、configparser 模块
# [dept]
# a = c
# b = light
# aa = 4
"""
import configparser
config = configparser.ConfigParser()
config.read('my_config.conf')
res = config.sections() # 得到所有的项
dept = config.items('dept') # 得到kv元祖对列表
val1 = config.get('dept', 'aa') # 得到值,默认类型为str
val = config.getint('dept', 'aa') # 得到值并转换为数字,如果转换失败就报错
sec = config.remove_section('emp') # 在当前内存中移除section ,成功返回true
config.write(open('my_config.conf', 'w')) # 将内存中的值写入文件
if not config.has_section('my'): # 判断是否存在section
config.add_section('my') # 不存在则添加 section
config.set('my', 'age', '25') # 给section设置kv对
config.remove_option('dept', 'a') # 删除section中的k
config.write(open('my_config.conf', 'w'))
"""
十、hashlib 模块
import hashlib
m = hashlib.md5()
m.update(b'hello') # 必须是byte
m.update(b'glen') # 现在相当于b'helloglen'
print(m.digest()) # 二进制格式
print(m.hexdigest()) # 16进制格式
sha1 = hashlib.sha1()
sha1.update(b'hello')
sha1.update(b'glen')
print(sha1.hexdigest())
sha256 = hashlib.sha256() # 一下和sha1类似,只是算法不同,长度不同
sha384 = hashlib.sha384()
sha512 = hashlib.sha512()
十一、subprocess 模块
import subprocess
p = subprocess.run("find / -name *.log -exec ls -sh {} \;", shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
p_out = p.stdout.decode(encoding='utf8')
p_code = p.returncode
# 需要使用交互命令示例
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
obj.stdin.write(b'print(1) \n')
obj.stdin.write(b'print(2) \n')
obj.stdin.write(b'print(3) \n')
obj.stdin.write(b'print(4) \n')
out_error_list = obj.communicate(timeout=10)
print(out_error_list)
十二、logging 模块
import logging
"""
DEBUG: 详细信息,通常仅在诊断问题时才受到关注。整数level=10
INFO: 确认程序按预期工作。整数level=20
WARNING:出现了异常,但是不影响正常工作.整数level=30
ERROR:由于某些原因,程序 不能执行某些功能。整数level=40
CRITICAL:严重的错误,导致程序不能运行。整数level=50
默认的级别是WARNING,也就意味着只有级别大于等于的才会被看到,跟踪日志的方式可以是写入到文件中,也可以直接输出到控制台。
日志格式
%(name)s
Logger的名字
%(levelno)s
数字形式的日志级别
%(levelname)s
文本形式的日志级别
%(pathname)s
调用日志输出函数的模块的完整路径名,可能没有
%(filename)s
调用日志输出函数的模块的文件名
%(module)s
调用日志输出函数的模块名
%(funcName)s
调用日志输出函数的函数名
%(lineno)d
调用日志输出函数的语句所在的代码行
%(created)f
当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d
输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d
线程ID。可能没有
%(threadName)s
线程名。可能没有
%(process)d
进程ID。可能没有
%(message)s
用户输出的消息
"""
logging.basicConfig(
filename='day5.log',
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
level=10 # 输出日志的等级
)
logging.debug('debug')
logging.info('info')
logging.warning('warning')
logging.critical('critical')
logging.error('error')
logging.log(10, 'log') # 可以手动设置等级
十三、re 正则表达式模块
常用正则表达式符号:
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^'
匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r
"^a"
,
"\nabc\neee"
,flags
=
re.MULTILINE)
'$'
匹配字符结尾,或e.search(
"foo$"
,
"bfoo\nsdfsf"
,flags
=
re.MULTILINE).group()也可以
'*'
匹配
*
号前的字符
0
次或多次,re.findall(
"ab*"
,
"cabb3abcbbac"
) 结果为[
'abb'
,
'ab'
,
'a'
]
'+'
匹配前一个字符
1
次或多次,re.findall(
"ab+"
,
"ab+cd+abb+bba"
) 结果[
'ab'
,
'abb'
]
'?'
匹配前一个字符
1
次或
0
次
'{m}'
匹配前一个字符m次
'{n,m}'
匹配前一个字符n到m次,re.findall(
"ab{1,3}"
,
"abb abc abbcbbb"
) 结果
'abb'
,
'ab'
,
'abb'
]
'|'
匹配|左或|右的字符,re.search(
"abc|ABC"
,
"ABCBabcCD"
).group() 结果
'ABC'
'(...)'
分组匹配,re.search(
"(abc){2}a(123|456)c"
,
"abcabca456c"
).group() 结果 abcabca456c
'\A'
只从字符开头匹配,re.search(
"\Aabc"
,
"alexabc"
) 是匹配不到的
'\Z'
匹配字符结尾,同$
'\d'
匹配数字
0
-
9
'\D'
匹配非数字
'\w'
匹配[A
-
Za
-
z0
-
9
]
'\W'
匹配非[A
-
Za
-
z0
-
9
]
'\s'
匹配空白字符、\t、\n、\r , re.search(
"\s+"
,
"ab\tc1\n3"
).group() 结果
'\t'
'\b' 匹配单词边界,表示字母数字与非字母数字的边界, 非字母数字与字母数字的边界。
'\B' 表示字母数字与(非非)字母数字的边界,非字母数字与非字母数字的边界。
'[^()]' 不包含"("和")"
'[^abc]' 不包含字符abc
示例:
re.search(r'\([^()]+\)',s).group(‘1+(60-30 +(-40/5))’)
结果:'(-40/5)'
常用语法:
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.splitall 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
import re
# res = re.search(r'[a-z]+', '123glen..alis%')
# print(res)
# res2 = re.findall(r'[a-z]+', '123glen..alis%')
# res5 = re.findall(r'[(](.)[\+\-\*\/](.)[)]', '(c-1)*(a+b)')
# print(res5)
# print(res2)
# res3 = re.split(r'%+', 'a%b%%c%%%')
# print(res3)
# res4 = re.sub(r'[(](.*?)[)]', 'aa', '(2+3)*(5-1)')
# print(res4)
# res5 = re.search(r"(?P<t1>\D+)(?P<t2>[0-9]+)(?P<t3>\D+)(?P<t4>\d+)", 'glen664age9923').groupdict('aaaa') # 分组匹配
# print(res5)
# {'t1': 'glen', 't2': '664', 't3': 'age', 't4': '9923'}
"""
匹配括号里面内容示例
string = 'abe(ac)ad)'
p1 = re.compile(r'[(](.*?)[)]', re.S) #最小匹配 r'[(]' = r'\(' 不然()表示一个分组
p2 = re.compile(r'[(](.*)[)]', re.S) #贪婪匹配
print(re.findall(p1, string))
print(re.findall(p2, string))
输出:
['ac']
['ac)ad']
解释一下:
1.正则匹配串前加了r就是为了使得里面的特殊符号不用写反斜杠了。
2.[ ]具有去特殊符号的作用,也就是说[(]里的(只是平凡的括号
3.正则匹配串里的()是为了提取整个正则串中符合括号里的正则的内容
4. .是为了表示除了换行符的任一字符。*克林闭包,出现0次或无限次。
5. 加了?是最小匹配,不加是贪婪匹配。
6. re.S是为了让.表示除了换行符的任一字符。
"""
"""
匹配反斜杠说明
# pat1 = re.compile(r'([0-9]+)\\')
# r'\\'的过程:
# 由于原始字符串中所有字符直接按照字面意思来使用,不转义特殊字符,故不做
# “字符串转义”,直接进入第二步“正则转义”,在正则转义中“\\”被转义为
# 了“\”,表示该正则式需要匹配一个反斜杠。
# pat2 = re.compile('([0-9]+)\\\\')
# '\\\\'的过程:
# 先进行“字符串转义”,前两个反斜杠和后两个反斜杠分别被转义成了一个反斜杠;
# 即“\\|\\”被转成了“\|\”(“|”为方便看清,请自动忽略)。“字符串转义”
# 后马上进行“正则转义”,“\\”被转义为了“\”,表示该正则式需要匹配一个反斜杠。
# res = pat1.findall(r'677\2345')
# r'667\2345' 这里是为了避免被转义,转移后肯定匹配不到
"""
作业
开发一个简单的python计算器
- 实现加减乘除及拓号优先级解析
- 用户输入 1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )等类似公式后,必须自己解析里面的(),+,-,*,/符号和公式(不能调用eval等类似功能偷懒实现),运算后得出结果,结果必须与真实的计算器所得出的结果一致
hint:
re.search(r'\([^()]+\)',s).group()
'(-40/5)'
import re
# pat1 = re.compile(r'\([^()]+\)') # [^()] 表示不包含 '(' 和 j')'
# res1 = pat1.search('5*(2+5/(3-1))')
# print(res1)
"""
计算器方案
1、首先解决加减乘除按顺序运算,完成一个函数
2、while 循环里面 使用正则re.compile(r'\([^()]+\)') 来匹配最里面的一个括号
3、匹配到最里面的括号后使用计算函数来进行计算
4、使用值替换原括号处的内容,生成新的表达式
5、继续重复步骤2,如果没有括号了就提出循环使用计算函数进行计算
"""
def split_exp(exp):
apt_nu = re.compile('[+\-*/]')
apt_op = re.compile('[.0-9]+')
res_nu = list(filter(lambda x: x, apt_nu.split(exp)))
res_op = list(filter(lambda x: x, apt_op.split(exp)))
if exp.startswith('-'):
del res_op[0]
res_nu[0] = '-' + res_nu[0]
for i in range(len(res_op)):
if res_op[i] == '+-':
res_op[i] = '-'
elif res_op[i] == '--':
res_op[i] = '+'
elif res_op[i] == '*-':
res_op[i] = '*'
res_nu[i+1] = '-' + res_nu[i+1]
elif res_op[i] == '/-':
res_op[i] = '/'
res_nu[i+1] = '-' + res_nu[i+1]
else:
pass
print(res_nu, res_op)
return {'number': res_nu, 'operator': res_op}
def handel_exp(number2, operator2, ope):
op_index = operator2.index(ope)
if ope == '*':
val_tmp = float(number2[op_index]) * float(number2[op_index + 1])
elif ope == '/':
val_tmp = float(number2[op_index]) / float(number2[op_index + 1])
elif ope == '-':
val_tmp = float(number2[op_index]) - float(number2[op_index + 1])
else:
val_tmp = float(number2[op_index]) + float(number2[op_index + 1])
del operator2[op_index]
del number2[op_index + 1]
del number2[op_index]
number2.insert(op_index, str(val_tmp))
return {'number': number2, 'operator': operator2}
def cal_exp(exp):
print(exp)
number = split_exp(exp)['number']
operator = split_exp(exp)['operator']
while len(operator):
print(number)
print(operator)
if operator.count('*') or operator.count('/'):
for v in operator:
if v == '*':
tmp_dict = handel_exp(number, operator, '*')
number = tmp_dict['number']
operator = tmp_dict['operator']
elif v == '/':
tmp_dict = handel_exp(number, operator, '/')
number = tmp_dict['number']
operator = tmp_dict['operator']
elif operator.count('-'):
tmp_dict = handel_exp(number, operator, '-')
number = tmp_dict['number']
operator = tmp_dict['operator']
elif operator.count('+'):
tmp_dict = handel_exp(number, operator, '+')
number = tmp_dict['number']
operator = tmp_dict['operator']
else:
print('操作符错误...')
exit()
return number[0]
exp_str = '1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))'
# exp_str = input('please enter expression:')
pat = re.compile(r'\(([^()]+)\)')
res = pat.findall(exp_str)
while res:
print(res)
if res:
val_tmp = cal_exp(res[0])
a = pat.search(exp_str).group()
exp_str = exp_str.replace(a, val_tmp)
res = pat.findall(exp_str)
else:
val_final = cal_exp(exp_str)
print('结果为;', val_final)
print(eval('1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))'))















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









