






Why it’s time to move on from OOP


OOP is considered by many to be the crown jewel of computer science. The ultimate solution to code organization. The end to all our problems. The only true way to write our programs. Bestowed upon us by the one true God of programming himself…
Until…it’s not, and people start succumbing under the weight of abstractions, and the complex graph of promiscuously shared mutable objects. Precious time and brainpower are being spent thinking about “abstractions” and “design patterns” instead of solving real-world problems.
Many people have criticized Object-Oriented Programming, including very prominent software engineers. Heck, even the inventor of OOP himself is a well-known critic of modern OOP!
The ultimate goal of every software developer should be to write reliable code. Nothing else matters if the code is buggy and unreliable. And what is the best way to write code that is reliable? Simplicity. Simplicity is the opposite of complexity. Therefore our first and foremost responsibility as software developers should be to reduce code complexity.


Disclaimer
I’ll be honest, I’m not a raving fan of object-orientation. Of course, this article is going to be biased. However, I have good reasons to dislike OOP.
I also understand that criticism of OOP is a very sensitive topic — I will probably offend many readers. However, I’m doing what I think is right. My goal is not to offend, but to raise awareness of the issues that OOP introduces.
I’m not criticizing Alan Kay’s OOP — he is a genius. I wish OOP was implemented the way he designed it. I’m criticizing the modern Java/C# approach to OOP.
I think that it is not right that OOP is considered the de-facto standard for code organization by many people, including those in very senior technical positions. It is also unacceptable that many mainstream languages don’t offer any other alternatives to code organization other than OOP.
Hell, I used to struggle a lot myself while working on OOP projects. And I had no single clue why I was struggling this much. Maybe I wasn’t good enough? I had to learn a couple more design patterns (I thought)! Eventually, I got completely burned out.
This post sums up my first-hand decade-long journey from Object-Oriented to Functional programming. Unfortunately, no matter how hard I try, I can no longer find use cases for OOP. I have personally seen OOP projects fail because they become too complex to maintain.
TLDR
Object oriented programs are offered as alternatives to correct ones…
— Edsger W. Dijkstra, pioneer of computer science


Object-Oriented Programming has been created with one goal in mind — to manage the complexity of procedural codebases. In other words, it was supposed to improve code organization. There’s no objective and open evidence that OOP is better than plain procedural programming.
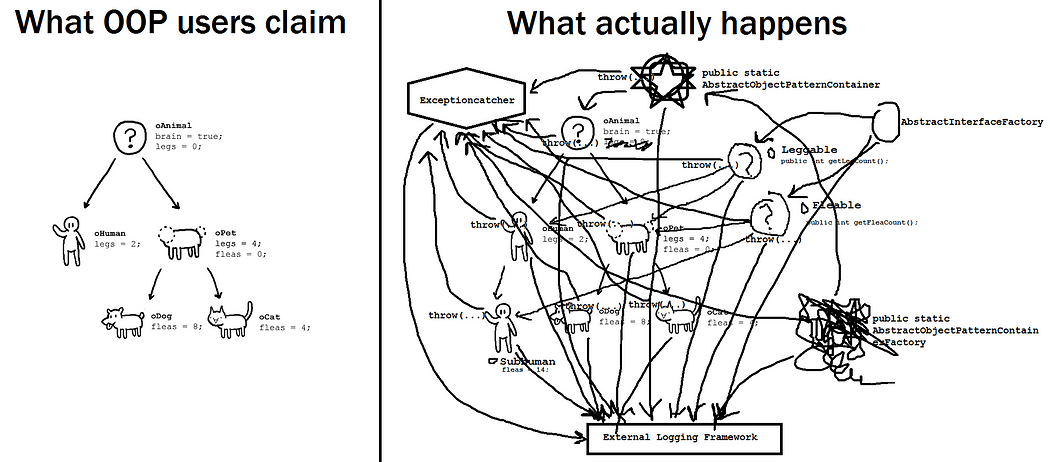
The bitter truth is that OOP fails at the only task it was intended to address. It looks good on paper — we have clean hierarchies of animals, dogs, humans, etc. However, it falls flat once the complexity of the application starts increasing. Instead of reducing complexity, it encourages promiscuous sharing of mutable state and introduces additional complexity with its numerous design patterns. OOP makes common development practices, like refactoring and testing, needlessly hard.
Some might disagree with me, but the truth is that modern Java/C# OOP has never been properly designed. It never came out of a proper research institution (in contrast with Haskell/FP). Lambda calculus offers a complete theoretical foundation for Functional Programming. OOP has nothing to match that.
Using OOP is seemingly innocent in the short-term, especially on greenfield projects. But what are the long-term consequences of using OOP? OOP is a time bomb, set to explode sometime in the future when the codebase gets big enough.
Projects get delayed, deadlines get missed, developers get burned-out, adding in new features becomes next to impossible. The organization labels the codebase as the “legacy codebase”, and the development team plans a rewrite.
OOP is not natural for the human brain, our thought process is centered around “doing” things — go for a walk, talk to a friend, eat pizza. Our brains have evolved to do things, not to organize the world into complex hierarchies of abstract objects.
OOP code is non-deterministic — unlike with functional programming, we’re not guaranteed to get the same output given the same inputs. This makes reasoning about the program very hard. As an oversimplified example, the output of 2+2 or calculator.Add(2, 2) mostly is equal to four, but sometimes it might become equal to three, five, and maybe even 1004. The dependencies of the Calculator object might change the result of the computation in subtle, but profound ways. OOPs…
The Need for a Resilient Framework
Good programmers write good code, bad programmers write bad code, no matter the programming paradigm. However, the programming paradigm should constrain bad programmers from doing too much damage. Of course, this is not you, since you already are reading this article and putting in the effort to learn. Bad programmers never have the time to learn, they only press random buttons on the keyboard like crazy. Whether you like it or not, you will be working with bad programmers, some of them will be really really bad. And, unfortunately, OOP does not have enough constraints in place that would prevent bad programmers from doing too much damage. OOPs…
I don’t consider myself a bad programmer, but even I am unable to write good code without a strong framework to base my work on. Yes, there are frameworks that concern themselves with some very particular problems (e.g. Angular or ASP.Net).
I’m not talking about the software frameworks. I’m talking about the more abstract dictionary definition of a framework: “an essential supporting structure” — frameworks that concern themselves with the more abstract things like code organization and tackling code complexity. Even though Object-Oriented and Functional Programming are both programming paradigms, they’re also both very high-level frameworks.
Limiting our choices
C++ is a horrible [object-oriented] language… And limiting your project to C means that people don’t screw things up with any idiotic “object model” c&@p.
— Linus Torvalds, the creator of Linux
Linus Torvalds is widely known for his open criticism of C++ and OOP. One thing he was 100% right about is limiting programmers in the choices they can make. In fact, the fewer choices programmers have, the more resilienttheir code becomes. In the quote above, Linus Torvalds highly recommends having a good framework to base our code upon.


Many dislike speed limits on the roads, but they’re essential to help prevent people from crashing to death. Similarly, a good programming framework should provide mechanisms that prevent us from doing stupid things.
A good programming framework helps us to write reliable code. First and foremost, it should help reduce complexity by providing the following things:
- Modularity and reusability
- Proper state isolation
- High signal-to-noise ratio
Unfortunately, OOP provides developers too many tools and choices, without imposing the right kinds of limitations. Even though OOP promises to address modularity and improve reusability, it fails to deliver on its promises (more on this later). OOP code encourages the use of shared mutable state, which has been proven to be unsafe time and time again. OOP typically requires a lot of boilerplate code (low signal-to-noise ratio).
Functional programming
What exactly is Functional Programming? Some people consider it to be a highly complicated programming paradigm that is only applicable in academia and is not suitable for the “real-world”. This couldn’t be further from the truth!
Yes, Functional Programming has a strong mathematical foundation and takes its roots in lambda calculus. However, most of its ideas emerged as a response to the weaknesses in the more mainstream programming languages. Functions are the core abstraction of Functional Programming. When used properly, functions provide a level of code modularity and reusability never seen in OOP. It even features design patterns that address the issues of nullability and provides a superior way of error handling.
The one thing that Functional Programming does really well is it helps us write reliable software. The need for a debugger almost disappears completely. Yep, no need to step through your code and watch variables. I personally haven’t touched a debugger in a very long time.
The best part? If you already know how to use functions, then you’re already a functional programmer. You just need to learn how to make the best use of those functions!
I’m not preaching Functional Programming, I don’t really care what programming paradigm you use writing your code. I’m simply trying to convey the mechanisms that Functional Programming provides to address the problems inherent with OOP/imperative programming.
We Got OOP All Wrong
I’m sorry that I long ago coined the term “objects” for this topic because it gets many people to focus on the lesser idea. The big idea is messaging.
- Alan Kay, the inventor of OOP
Erlang is not usually thought of as an Object-Oriented language. But probably Erlang is the only mainstream Object-Oriented language out there. Yes, of course Smalltalk is a proper OOP language — however, it is not in wide use. Both Smalltalk and Erlang make use of OOP the way it was originally intended by its inventor, Alan Kay.
Messaging
Alan Kay coined the term “Object Oriented Programming” in the 1960s. He had a background in biology and was attempting to make computer programs communicate the same way living cells do.


Alan Kay’s big idea was to have independent programs (cells) communicate by sending messages to each other. The state of the independent programs would never be shared with the outside world (encapsulation).
That’s it. OOP was never intended to have things like inheritance, polymorphism, the “new” keyword, and the myriad of design patterns.
OOP in its purest form
Erlang is OOP in its purest form. Unlike more mainstream languages, it focuses on the core idea of OOP — messaging. In Erlang, objects communicate by passing immutable messages between objects.
Is there proof that immutable messages are a superior approach compared to method calls?
Hell yes! Erlang is probably the most reliable language in the world. It powers most of the world’s telecom (and hence the internet) infrastructure. Some of the systems written in Erlang have reliability of 99.9999999% (you read that right — nine nines).
Code Complexity
With OOP-inflected programming languages, computer software becomes more verbose, less readable, less descriptive, and harder to modify and maintain.
The most important aspect of software development is keeping the code complexity down. Period. None of the fancy features matter if the codebase becomes impossible to maintain. Even 100% test coverage is worth nothing if the codebase becomes too complex and unmaintainable.
What makes the codebase complex? There are many things to consider, but in my opinion, the top offenders are: shared mutable state, erroneous abstractions, and low signal-to-noise ratio (often caused by boilerplate code). All of them are prevalent in OOP.
The Problems of State


What is state? Simply put, state is any temporary data stored in memory. Think variables or fields/properties in OOP. Imperative programming (including OOP) describes computation in terms of the program state and changes to that state. Declarative (functional) programming describes the desired results instead, and don’t specify changes to the state explicitly.
Mutable State — the act of mental juggling
I think that large objected-oriented programs struggle with increasing complexity as you build this large object graph of mutable objects. You know, trying to understand and keep in your mind what will happen when you call a method and what will the side effects be.
— Rich Hickey, creator of Clojure


State by itself is quite harmless. However, mutable state is the big offender. Especially if it is shared. What exactly is mutable state? Any state that can change. Think variables or fields in OOP.
Real-world example, please!
You have a blank piece of paper, you write a note on it, and you end up with the same piece of paper in a different state (text). You, effectively, have mutated the state of that piece of paper.
That is completely fine in the real world since nobody else probably cares about that piece of paper. Unless this piece of paper is the original Mona Lisa painting.
Limitations of the Human Brain
Why is mutable state such a big problem? The human brain is the most powerful machine in the known universe. However, our brains are really bad at working with state since we can only hold about 5 items at a time in our working memory. It is much easier to reason about a piece of code if you only think about what the code does, not what variables it changes around the codebase.
Programming with mutable state is an act of mental juggling️. I don’t know about you, but I could probably juggle two balls. Give me three or more balls and I will certainly drop all of them. Why are we then trying to perform this act of mental juggling every single day at work?
Unfortunately, the mental juggling of mutable state is at the very core of OOP . The sole purpose for the existence of methods on an object is to mutate that same object.
Scattered state


OOP makes the problem of code organization even worse by scattering state all over the program. The scattered state is then shared promiscuously between various objects.
Real-world example, please!
Let’s forget for a second that we’re all grown-ups, and pretend we’re trying to assemble a cool lego truck.
However, there’s a catch — all the truck parts are randomly mixed with parts from your other lego toys. And they have been put in 50 different boxes, randomly again. And you’re not allowed to group your truck parts together — you have to keep in your head where the various truck parts are, and can only take them out one by one.
Yes, you will eventually assemble that truck, but how long will it take you?
How does this relate to programming?
In Functional Programming, state typically is being isolated. You always know where some state is coming from. State is never scattered across your different functions. In OOP, every object has its own state, and when building a program , you have to keep in mind the state of all of the objects that you currently are working with.
To make our lives easier, it is best to have only a very small portion of the codebase deal with state. Let the core parts of your application be stateless and pure. This actually is the main reason for the huge success of the flux pattern on the frontend (aka Redux).
Promiscuously shared state
As if our lives aren’t already hard enough because of having scattered mutable state, OOP goes one step further!
Real-world Example, Please!
Mutable state in the real world is almost never a problem, since things are kept private and never shared. This is “proper encapsulation” at work. Imagine a painter who is working on the next Mona Lisa painting. He is working on the painting alone, finishes up, and then sells his masterpiece for millions.
Now, he’s bored with all that money and decides to do things a little bit differently. He thinks that it would be a good idea to have a painting party. He invites his friends elf, Gandalf, policeman, and a zombie to help him out. Teamwork! They all start painting on the same canvas at the same time. Of course, nothing good comes out of it — the painting is a complete disaster!
Shared mutable state makes no sense in the real world. Yet this is exactly what happens in OOP programs — state is promiscuously shared between various objects, and they mutate it in any way they see fit. This, in turn, makes reasoning about the program harder and harder as the codebase keeps growing.
Concurrency issues
The promiscuous sharing of mutable state in OOP code makes parallelizing such code almost impossible. Complex mechanisms have been invented in order to address this problem. Thread locking, mutex, and many other mechanisms have been invented. Of course, such complex approaches have their own drawbacks — deadlocks, lack of composability, debugging multi-threaded code is very hard and time-consuming. I’m not even talking about the increased complexity caused by making use of such concurrency mechanisms.
Not all state is evil
Is all state evil? No, Alan Kay state probably is not evil! State mutation probably is fine if it is truly isolated (not the “OOP-way” isolated).
It is also completely fine to have immutable data-transfer-objects. The key here is “immutable”. Such objects are then used to pass data between functions.
However, such objects would also make OOP methods and properties completely redundant. What’s the use in having methods and properties on an object if it cannot be mutated?
Mutability is Inherent to OOP
Some might argue that mutable state is a design choice in OOP, not an obligation. There is a problem with that statement. It is not a design choice, but pretty much the only option. Yes, one can pass immutable objects to methods in Java/C#, but this is rarely done since most of the developers default to data mutation. Even if developers attempt to make proper use of immutability in their OOP programs, the languages provide no built-in mechanisms for immutability, and for working effectively with immutable data (i.e. persistent data structures).
Yes, we can ensure that objects communicate only by passing immutable messages and never pass any references (which is rarely done). Such programs would be more reliable than mainstream OOP. However, the objects still have to mutate their own state once a message has been received. A message is a side effect, and its single purpose is to cause changes. Messages would be useless if they couldn’t mutate the state of other objects.
It is impossible to make use of OOP without causing state mutations.
The Trojan Horse of Encapsulation


We’ve been told that encapsulation is one of the greatest benefits of OOP. It is supposed to protect the object’s internal state from outside access. There’s a small problem with this though. It doesn’t work.
Encapsulation is the trojan horse of OOP. It sells the idea of shared mutable state by making it appear safe. Encapsulation allows (and even encourages) unsafe code to sneak into our codebase, making the codebase rot from within.
The global state problem
We’ve been told that global state is the root of all evil. It should be avoided at all costs. What we have never been told is that encapsulation, in fact, is glorified global state.
To make the code more efficient, objects are passed not by their value, but by their reference. This is where “dependency injection” falls flat.
Let me explain. Whenever we create an object in OOP, we pass references to its dependencies to the constructor. Those dependencies also have their own internal state. The newly created object happily stores references to those dependencies in its internal state and is then happy to modify them in any way it pleases. And it also passes those references down to anything else it might end up using.
This creates a complex graph of promiscuously shared objects that all end up changing each other’s state. This, in turn, causes huge problems since it becomes almost impossible to see what caused the program state to change. Days might be wasted trying to debug such state changes. And you’re lucky if you don’t have to deal with concurrency (more on this later).
Methods/Properties
The methods or properties that provide access to particular fields are no better than changing the value of a field directly. It doesn’t matter whether you mutate an object’s state by using a fancy property or method — the result is the same: mutated state.
The Problem with Real World Modeling


Some people say that OOP tries to model the real world. This is simply not true — OOP has nothing to relate to in the real world. Trying to model programs as objects probably is one of the biggest OOP mistakes.
The real world is not hierarchical
OOP attempts to model everything as a hierarchy of objects. Unfortunately, that is not how things work in the real world. Objects in the real world interact with each other using messages, but they mostly are independent of each other.
Inheritance in the real world
OOP inheritance is not modeled after the real world. The parent object in the real world is unable to change the behavior of child objects at run-time. Even though you inherit your DNA from your parents, they’re unable to make changes to your DNA as they please. You do not inherit “behaviors” from your parents, you develop your own behaviors. And you’re unable to “override” your parents’ behaviors.
The real world has no methods
Does the piece of paper you’re writing on have a “write” method? No! You take an empty piece of paper, pick up a pen, and write some text. You, as a person, don’t have a “write” method either — you make the decision to write some text based on outside events or your internal thoughts.
The Kingdom of Nouns
Objects bind functions and data structures together in indivisible units. I think this is a fundamental error since functions and data structures belong in totally different worlds.
— Joe Armstrong, creator of Erlang


Objects (or nouns) are at the very core of OOP. A fundamental limitation of OOP is that it forces everything into nouns. And not everything should be modeled as nouns. Operations (functions) should not be modeled as objects. Why are we forced to create a Multiplierclass when all we need is a function that multiplies two numbers? Simply have a Multiply function, let data be data and let functions be functions!
In non-OOP languages, doing trivial things like saving data to a file is straightforward — very similar to how you would describe an action in plain English.
Real-world example, please!
Sure, going back to the painter example, the painter owns a PaintingFactory. He has hired a dedicated BrushManager , ColorManager, a CanvasManager and a MonaLisaProvider. His good friend zombie makes use of a BrainConsumingStrategy . Those objects, in turn, define the following methods: CreatePainting , FindBrush , PickColor , CallMonaLisa , and ConsumeBrainz.
Of course, this is plain stupidity, and could never have happened in the real world. How much unnecessary complexity has been created for the simple act of drawing a painting?
There’s no need to invent strange concepts to hold your functions when they’re allowed to exist separately from the objects.
Unit Testing


Automated testing is an important part of the development process and helps tremendously in preventing regressions (i.e. bugs being introduced into existing code). Unit Testing plays a huge role in the process of automated testing.
Some might disagree, but OOP code is notoriously difficult to unit test. Unit Testing assumes testing things in isolation, and to make a method unit-testable:
- Its dependencies have to be extracted into a separate class.
- Create an interface for the newly created class.
- Declare fields to hold the instance of the newly created class.
- Make use of a mocking framework to mock the dependencies.
- Make use of a dependency-injection framework to inject the dependencies.
How much more complexity has to be created just to make a piece of code testable? How much time was wasted just to make some code testable?
> PS we’d also have to instantiate the entire class in order to test a single method. This will also bring in the code from all of its parent classes.
With OOP, writing tests for legacy code is even harder — almost impossible. Entire companies have been created (TypeMock) around the issue of testing legacy OOP code.
Boilerplate code
Boilerplate code is probably the biggest offender when it comes to the signal-to-noise ratio. Boilerplate code is “noise” that is required to get the program to compile. Boilerplate code takes time to write and makes the codebase less readable because of the added noise.
While “program to an interface, not to an implementation” is the recommended approach in OOP, not everything should become an interface. We’d have to resort to using interfaces in the entire codebase, for the sole purpose of testability. We’d also probably have to make use of dependency injection, which further introduced unnecessary complexity.
Testing private methods
Some people say that private methods shouldn’t be tested… I tend to disagree, unit testing is called “unit” for a reason — test small units of code in isolation. Yet testing of private methods in OOP is nearly impossible. We shouldn’t be making private methodsinternal just for the sake of testability.
In order to achieve testability of private methods, they usually have to be extracted into a separate object. This, in turn, introduces unnecessary complexity and boilerplate code.
Refactoring
Refactoring is an important part of a developer’s day-to-day job. Ironically, OOP code is notoriously hard to refactor. Refactoring is supposed to make the code less complex, and more maintainable. On the contrary, refactored OOP code becomes significantly more complex — to make the code testable, we’d have to make use of dependency injection, and create an interface for the refactored class. Even then, refactoring OOP code is really hard without dedicated tools like Resharper.
In the simple example above, the line count has more than doubled just to extract a single method. Why does refactoring create even more complexity, when the code is being refactored in order to decrease complexity in the first place?
Contrast this to a similar refactor of non-OOP code in JavaScript:
The code has literally stayed the same — we simply moved the isValidInput function to a different file and added a single line to import that function. We’ve also added _isValidInput to the function signature for the sake of testability.
This is a simple example, but in practice the complexity grows exponentially as the codebase gets bigger.
And that’s not all. Refactoring OOP code is extremely risky. Complex dependency graphs and state scattered all over OOP codebase, make it impossible for the human brain to consider all of the potential issues.
The Band-aids


What do we do when something is not working? It is simple, we only have two options — throw it away or try fixing it. OOP is something that can’t be thrown away easily, millions of developers are trained in OOP. And millions of organizations worldwide are using OOP.
You probably see now that OOP doesn’t really work, it makes our code complex and unreliable. And you’re not alone! People have been thinking hard for decades trying to address the issues prevalent in OOP code. They’ve come up with a myriad of design patterns.
Design patterns
OOP provides a set of guidelines that should theoretically allow developers to incrementally build larger and larger systems: SOLID principle, dependency injection, design patterns, and others.
Unfortunately, the design patterns are nothing other than band-aids. They exist solely to address the shortcomings of OOP. A myriad of books has even been written on the topic. They wouldn’t have been so bad, had they not been responsible for the introduction of enormous complexity to our codebases.
The problem factory
In fact, it is impossible to write good and maintainable Object-Oriented code.
On one side of the spectrum we have an OOP codebase that is inconsistent and doesn’t seem to adhere to any standards. On the other side of the spectrum, we have a tower of over-engineered code, a bunch of erroneous abstractions built one on top of one another. Design patterns are very helpful in building such towers of abstractions.
Soon, adding in new functionality, and even making sense of all the complexity, gets harder and harder. The codebase will be full of things like SimpleBeanFactoryAwareAspectInstanceFactory, AbstractInterceptorDrivenBeanDefinitionDecorator, TransactionAwarePersistenceManagerFactoryProxyorRequestProcessorFactoryFactory .
Precious brainpower has to be wasted trying to understand the tower of abstractions that the developers themselves have created. The absence of structure is in many cases better than having bad structure (if you ask me).

Further reading: FizzBuzzEnterpriseEdition
The Fall of the Four OOP Pillars
The four pillars of OOP are: Abstraction, Inheritance, Encapsulation, and Polymorphism.
Let’s see what they really are, one-by-one.


Inheritance
I think the lack of reusability comes in object-oriented languages, not in functional languages. Because the problem with object-oriented languages is they’ve got all this implicit environment that they carry around with them. You wanted a banana but what you got was a gorilla holding the banana and the entire jungle.
— Joe Armstrong, creator of Erlang
OOP inheritance has nothing to do with the real world. Inheritance, in fact, is an inferior way to achieve code reusability. The gang of four has explicitly recommended preferring composition over inheritance. Some modern programming languages avoid inheritance altogether.
There are a few problems with inheritance:
- Bringing in a lot of code that your class doesn’t even need (banana and the jungle problem).
- Having parts of your class defined somewhere else makes the code hard to reason about, especially with multiple levels of inheritance.
- In most programming languages, multiple inheritance isn’t even possible. This mostly renders inheritance useless as a code-sharing mechanism.
OOP polymorphism
Polymorphism is great, it allows us to change program behavior at runtime. However, it is a very basic concept in computer programming. I’m not too sure why OOP focuses so much on polymorphism. OOP polymorphism gets the job done but once again it results in the act of mental juggling. It makes the codebase significantly more complex, and reasoning about the concrete method that is being invoked becomes really hard.
Functional programming, on the other hand, allows us to achieve the same polymorphism in a much more elegant way…by simply passing in a function that defines the desired runtime behavior. What could be simpler than that? No need to define a bunch of overloaded abstract virtual methods in multiple files (and the interface).
Encapsulation
As we discussed earlier, encapsulation is the trojan horse of OOP. It is actually a glorified global mutable state and makes the unsafe code appear safe. An unsafe coding practice is a pillar that OOP programmers rely on in their day-to-day job…
Abstraction
Abstraction in OOP attempts to tackle complexity by hiding unnecessary details from the programmer. Theoretically, it should allow the developer to reason about the codebase without having to think about the hidden complexity.
I don’t even know what to say…a fancy word for a simple concept. In procedural/functional languages we can simply “hide” the implementation details in a neighboring file. No need to call this basic act an “abstraction”.
For more details on the fall of OOP pillars, please read Goodbye, Object Oriented Programming
Why Does OOP Dominate the Industry?
The answer is simple, the reptiloid alien race has conspired with the NSA (and the Russians) to torture us programmers to death…


But seriously, Java is probably the answer.
Java is the most distressing thing to happen to computing since MS-DOS.
- Alan Kay, the inventor of object-oriented programming
Java was Simple
When it was first introduced in 1995, Java was a very simple programming language, compared to the alternatives. At that time, the barrier of entry for writing desktop applications was high. Developing desktop applications involved writing low-level win32 APIs in C, and developers also had to concern themselves with manual memory management. The other alternative was Visual Basic, but many probably didn’t want to lock themselves into the Microsoft ecosystem.
When Java was introduced, it was a no-brainer for many developers since it was free, and could be used across all platforms. Things like built-in garbage collection, friendly-named APIs (compared to the cryptic win32 APIs), proper namespaces, and familiar C-like syntax made Java even more approachable.
GUI programming was also becoming more popular, and it seemed that various UI components mapped well to classes. Method autocompletion in the IDEs also made people claim that OOP APIs are easier to use.
Perhaps Java wouldn’t have been so bad had it not forced OOP on developers. Everything else about Java seemed pretty good. Its garbage collection, portability, exception handling features, which other mainstream programming languages lacked, were really great in 1995,
Then C# came along
Initially, Microsoft had been relying heavily on Java. When things started getting awry (and after a long legal battle with Sun Microsystems over Java licensing), Microsoft decided to invest in its own version of Java. That is when C# 1.0 was born. C# as a language has always been thought of as “the better Java”. However, there’s one huge problem — it was the same OOP language with the same flaws, hidden under a slightly improved syntax.
Microsoft has been investing heavily in its .NET ecosystem, which also included good developer tooling. For years Visual Studio has probably been one of the best IDEs available. This, in turn, has led to wide-spread adoption of the .NET framework, especially in the enterprise.
More recently Microsoft has been investing heavily in the browser ecosystem, by pushing its TypeScript. TypeScript is great because it can compile pure JavaScript and adds in things like static type checking. What’s not so great about it is it has no proper support for functional constructs — no built-in immutable data structures, no function composition, no proper pattern matching. TypeScript is OOP-first, and mostly is C# for the browser. Anders Hejlsberg was even responsible for the design of both C# and TypeScript.
Functional languages
Functional languages, on the other hand, have never been backed by someone as big as Microsoft. F# doesn’t count since the investment was minuscule. The development of functional languages is mostly community-driven. This probably explains the differences in popularity between OOP and FP languages.
Time to Move On?
We now know that OOP is an experiment that failed. It is time to move on. It is time that we, as a community, admit that this idea has failed us, and we must give up on it.


Why are we stuck using something that fundamentally is a suboptimal way to organize programs? Is this plain ignorance? I doubt it, the people working in software engineering aren’t stupid. Are we perhaps more worried about “looking smart” in the face of our peers by making use of fancy OOP terms like “design patterns”, “abstraction”, “encapsulation”, “polymorphism” and “interface segregation”? Probably not.
I think that it’s really easy to continue using something that we’ve been using for decades. Most of the people have never really tried Functional Programming. Those who have (like myself) can never go back to writing OOP code.
Henry Ford once famously said — “If I had asked people what they wanted, they would have said faster horses”. In the world of software, most people would probably want a “better OOP language”. People can easily describe a problem they’re having (getting the codebase organized and less complex), but not the best solution.
What Are the Alternatives?
Spoiler alert: Functional Programming.


If terms like functors and monads make you a little uneasy, then you’re not alone! Functional Programming wouldn’t have been so scary had they given more intuitive names to some of its concepts. Functor? That’s simply something we can transform with a function, think list.map. Monad? Simply computations that can be chained!
Trying out Functional Programming will make you a better developer. You will finally have the time to write real code that solves real-world problems, rather than having to spend most of your time thinking about abstractions and design patterns.
You might not realize this, but you already are a functional programmer. Are you using functions in your day-to-day work? Yes? Then you’re already a functional programmer! You just have to learn how to make the best use of those functions.
Two great functional languages with a very gentle learning curve are Elixirand Elm. They let the developer focus on what matters most — writing reliable software while removing all of the complexity that more traditional functional languages have.
What are the other options? Is your organization already is using C#? Give F# a try — it is an amazing functional language, and provides great interoperability with the existing .NET code. Using Java? Then using Scala or Clojure are both really good options. Using JavaScript? With the right guidance and linting, JavaScript can be a good functional language.
The Defenders of OOP


I expect some sort of reaction from the defenders of OOP. They will say that this article is full of inaccuracies. Some might even start calling names. They might even call me a “junior” developer with no real-world OOP experience. Some might say that my assumptions are erroneous, and examples are useless. Whatever.
They have the right to their opinion. However, their arguments in the defense of OOP are usually quite weak. It is ironic that most of them probably have never really programmed in a true functional language. How can someone draw comparisons between two things if you have never really tried both? Such comparisons aren’t very useful.
The Law of Demeter is not very useful — it does nothing to address the issue of non-determinism, shared mutable state is still shared mutable state, no matter how you access or mutate that state. a.total()is not much better than a.getB().getC().total(). It simply sweeps the problem under the rug.
Domain-Driven Design? That’s a useful design methodology, it helps a bit with the complexity. However, it still does nothing to address the fundamental issue of shared mutable state.
Just a tool in a toolbox…
I often hear people say that OOP is just another tool in a toolbox. Yes, it is as much a tool in a toolbox as horses and cars are both tools for transportation… After all, they all serve the same purpose, right? Why use cars when we can continue riding good old horses?
History repeats itself
This actually reminds me of something. At the beginning of the 20th century, automobiles started replacing the horses. In the year 1900 New York had only a few cars on the roads, people have been using horses for transportation. In the year 1917, no more horses were left on the roads. A huge industry was centered around horse transportation. Entire businesses have been created around things like manure cleaning.
And people resisted change. They called automobiles another “fad” that eventually pass. After all, horses have been here for centuries! Some even asked the government to intervene.
How is this relevant? The software industry is centered around OOP. Millions of people are trained in OOP, and millions of companies make use of OOP in their code. Of course, they will try to discredit anything that threatens their bread-and-butter! It’s just common sense.
We clearly see the history repeating itself — in the 20th century it was the horses vs automobiles, in the 21st century it is Object-Oriented vs Functional Programming.
What’s Next?
- Goodbye, Object Oriented Programming by Charles Scalfani
- Object-Oriented Programming Oversold
- The Forgotten History of OOP by Eric Elliott
- Why OO Sucks by Joe Armstrong, creator of Erlang
- Object-Oriented Programming is Bad by Brian Will
- Execution in the Kingdom of Nouns by Steve Yegge
- Was object-oriented programming a failure?
Object-Oriented Programming — The Trillion Dollar Disaster
Why it’s time to move on from OOP
OOP is considered by many to be the crown jewel of computer science. The ultimate solution to code organization. The end to all our problems. The only true way to write our programs. Bestowed upon us by the one true God of programming himself…
Until…it’s not, and people start succumbing under the weight of abstractions, and the complex graph of promiscuously shared mutable objects. Precious time and brainpower are being spent thinking about “abstractions” and “design patterns” instead of solving real-world problems.
Many people have criticized Object-Oriented Programming, including very prominent software engineers. Heck, even the inventor of OOP himself is a well-known critic of modern OOP!
The ultimate goal of every software developer should be to write reliable code. Nothing else matters if the code is buggy and unreliable. And what is the best way to write code that is reliable? Simplicity. Simplicity is the opposite of complexity. Therefore our first and foremost responsibility as software developers should be to reduce code complexity.
Disclaimer
I’ll be honest, I’m not a raving fan of object-orientation. Of course, this article is going to be biased. However, I have good reasons to dislike OOP.
I also understand that criticism of OOP is a very sensitive topic — I will probably offend many readers. However, I’m doing what I think is right. My goal is not to offend, but to raise awareness of the issues that OOP introduces.
I’m not criticizing Alan Kay’s OOP — he is a genius. I wish OOP was implemented the way he designed it. I’m criticizing the modern Java/C# approach to OOP.
I think that it is not right that OOP is considered the de-facto standard for code organization by many people, including those in very senior technical positions. It is also unacceptable that many mainstream languages don’t offer any other alternatives to code organization other than OOP.
Hell, I used to struggle a lot myself while working on OOP projects. And I had no single clue why I was struggling this much. Maybe I wasn’t good enough? I had to learn a couple more design patterns (I thought)! Eventually, I got completely burned out.
This post sums up my first-hand decade-long journey from Object-Oriented to Functional programming. Unfortunately, no matter how hard I try, I can no longer find use cases for OOP. I have personally seen OOP projects fail because they become too complex to maintain.
TLDR
Object oriented programs are offered as alternatives to correct ones…
— Edsger W. Dijkstra, pioneer of computer science
Object-Oriented Programming has been created with one goal in mind — to manage the complexity of procedural codebases. In other words, it was supposed to improve code organization. There’s no objective and open evidence that OOP is better than plain procedural programming.
The bitter truth is that OOP fails at the only task it was intended to address. It looks good on paper — we have clean hierarchies of animals, dogs, humans, etc. However, it falls flat once the complexity of the application starts increasing. Instead of reducing complexity, it encourages promiscuous sharing of mutable state and introduces additional complexity with its numerous design patterns. OOP makes common development practices, like refactoring and testing, needlessly hard.
Some might disagree with me, but the truth is that modern Java/C# OOP has never been properly designed. It never came out of a proper research institution (in contrast with Haskell/FP). Lambda calculus offers a complete theoretical foundation for Functional Programming. OOP has nothing to match that.
Using OOP is seemingly innocent in the short-term, especially on greenfield projects. But what are the long-term consequences of using OOP? OOP is a time bomb, set to explode sometime in the future when the codebase gets big enough.
Projects get delayed, deadlines get missed, developers get burned-out, adding in new features becomes next to impossible. The organization labels the codebase as the “legacy codebase”, and the development team plans a rewrite.
OOP is not natural for the human brain, our thought process is centered around “doing” things — go for a walk, talk to a friend, eat pizza. Our brains have evolved to do things, not to organize the world into complex hierarchies of abstract objects.
OOP code is non-deterministic — unlike with functional programming, we’re not guaranteed to get the same output given the same inputs. This makes reasoning about the program very hard. As an oversimplified example, the output of 2+2 or calculator.Add(2, 2) mostly is equal to four, but sometimes it might become equal to three, five, and maybe even 1004. The dependencies of the Calculator object might change the result of the computation in subtle, but profound ways. OOPs…
The Need for a Resilient Framework
Good programmers write good code, bad programmers write bad code, no matter the programming paradigm. However, the programming paradigm should constrain bad programmers from doing too much damage. Of course, this is not you, since you already are reading this article and putting in the effort to learn. Bad programmers never have the time to learn, they only press random buttons on the keyboard like crazy. Whether you like it or not, you will be working with bad programmers, some of them will be really really bad. And, unfortunately, OOP does not have enough constraints in place that would prevent bad programmers from doing too much damage. OOPs…
I don’t consider myself a bad programmer, but even I am unable to write good code without a strong framework to base my work on. Yes, there are frameworks that concern themselves with some very particular problems (e.g. Angular or ASP.Net).
I’m not talking about the software frameworks. I’m talking about the more abstract dictionary definition of a framework: “an essential supporting structure” — frameworks that concern themselves with the more abstract things like code organization and tackling code complexity. Even though Object-Oriented and Functional Programming are both programming paradigms, they’re also both very high-level frameworks.
Limiting our choices
C++ is a horrible [object-oriented] language… And limiting your project to C means that people don’t screw things up with any idiotic “object model” c&@p.
— Linus Torvalds, the creator of Linux
Linus Torvalds is widely known for his open criticism of C++ and OOP. One thing he was 100% right about is limiting programmers in the choices they can make. In fact, the fewer choices programmers have, the more resilienttheir code becomes. In the quote above, Linus Torvalds highly recommends having a good framework to base our code upon.
Many dislike speed limits on the roads, but they’re essential to help prevent people from crashing to death. Similarly, a good programming framework should provide mechanisms that prevent us from doing stupid things.
A good programming framework helps us to write reliable code. First and foremost, it should help reduce complexity by providing the following things:
- Modularity and reusability
- Proper state isolation
- High signal-to-noise ratio
Unfortunately, OOP provides developers too many tools and choices, without imposing the right kinds of limitations. Even though OOP promises to address modularity and improve reusability, it fails to deliver on its promises (more on this later). OOP code encourages the use of shared mutable state, which has been proven to be unsafe time and time again. OOP typically requires a lot of boilerplate code (low signal-to-noise ratio).
Functional programming
What exactly is Functional Programming? Some people consider it to be a highly complicated programming paradigm that is only applicable in academia and is not suitable for the “real-world”. This couldn’t be further from the truth!
Yes, Functional Programming has a strong mathematical foundation and takes its roots in lambda calculus. However, most of its ideas emerged as a response to the weaknesses in the more mainstream programming languages. Functions are the core abstraction of Functional Programming. When used properly, functions provide a level of code modularity and reusability never seen in OOP. It even features design patterns that address the issues of nullability and provides a superior way of error handling.
The one thing that Functional Programming does really well is it helps us write reliable software. The need for a debugger almost disappears completely. Yep, no need to step through your code and watch variables. I personally haven’t touched a debugger in a very long time.
The best part? If you already know how to use functions, then you’re already a functional programmer. You just need to learn how to make the best use of those functions!
I’m not preaching Functional Programming, I don’t really care what programming paradigm you use writing your code. I’m simply trying to convey the mechanisms that Functional Programming provides to address the problems inherent with OOP/imperative programming.
We Got OOP All Wrong
I’m sorry that I long ago coined the term “objects” for this topic because it gets many people to focus on the lesser idea. The big idea is messaging.
- Alan Kay, the inventor of OOP
Erlang is not usually thought of as an Object-Oriented language. But probably Erlang is the only mainstream Object-Oriented language out there. Yes, of course Smalltalk is a proper OOP language — however, it is not in wide use. Both Smalltalk and Erlang make use of OOP the way it was originally intended by its inventor, Alan Kay.
Messaging
Alan Kay coined the term “Object Oriented Programming” in the 1960s. He had a background in biology and was attempting to make computer programs communicate the same way living cells do.
Alan Kay’s big idea was to have independent programs (cells) communicate by sending messages to each other. The state of the independent programs would never be shared with the outside world (encapsulation).
That’s it. OOP was never intended to have things like inheritance, polymorphism, the “new” keyword, and the myriad of design patterns.
OOP in its purest form
Erlang is OOP in its purest form. Unlike more mainstream languages, it focuses on the core idea of OOP — messaging. In Erlang, objects communicate by passing immutable messages between objects.
Is there proof that immutable messages are a superior approach compared to method calls?
Hell yes! Erlang is probably the most reliable language in the world. It powers most of the world’s telecom (and hence the internet) infrastructure. Some of the systems written in Erlang have reliability of 99.9999999% (you read that right — nine nines).
Code Complexity
With OOP-inflected programming languages, computer software becomes more verbose, less readable, less descriptive, and harder to modify and maintain.
The most important aspect of software development is keeping the code complexity down. Period. None of the fancy features matter if the codebase becomes impossible to maintain. Even 100% test coverage is worth nothing if the codebase becomes too complex and unmaintainable.
What makes the codebase complex? There are many things to consider, but in my opinion, the top offenders are: shared mutable state, erroneous abstractions, and low signal-to-noise ratio (often caused by boilerplate code). All of them are prevalent in OOP.
The Problems of State
What is state? Simply put, state is any temporary data stored in memory. Think variables or fields/properties in OOP. Imperative programming (including OOP) describes computation in terms of the program state and changes to that state. Declarative (functional) programming describes the desired results instead, and don’t specify changes to the state explicitly.
Mutable State — the act of mental juggling
I think that large objected-oriented programs struggle with increasing complexity as you build this large object graph of mutable objects. You know, trying to understand and keep in your mind what will happen when you call a method and what will the side effects be.
— Rich Hickey, creator of Clojure
State by itself is quite harmless. However, mutable state is the big offender. Especially if it is shared. What exactly is mutable state? Any state that can change. Think variables or fields in OOP.
Real-world example, please!
You have a blank piece of paper, you write a note on it, and you end up with the same piece of paper in a different state (text). You, effectively, have mutated the state of that piece of paper.
That is completely fine in the real world since nobody else probably cares about that piece of paper. Unless this piece of paper is the original Mona Lisa painting.
Limitations of the Human Brain
Why is mutable state such a big problem? The human brain is the most powerful machine in the known universe. However, our brains are really bad at working with state since we can only hold about 5 items at a time in our working memory. It is much easier to reason about a piece of code if you only think about what the code does, not what variables it changes around the codebase.
Programming with mutable state is an act of mental juggling️. I don’t know about you, but I could probably juggle two balls. Give me three or more balls and I will certainly drop all of them. Why are we then trying to perform this act of mental juggling every single day at work?
Unfortunately, the mental juggling of mutable state is at the very core of OOP . The sole purpose for the existence of methods on an object is to mutate that same object.
Scattered state
OOP makes the problem of code organization even worse by scattering state all over the program. The scattered state is then shared promiscuously between various objects.
Real-world example, please!
Let’s forget for a second that we’re all grown-ups, and pretend we’re trying to assemble a cool lego truck.
However, there’s a catch — all the truck parts are randomly mixed with parts from your other lego toys. And they have been put in 50 different boxes, randomly again. And you’re not allowed to group your truck parts together — you have to keep in your head where the various truck parts are, and can only take them out one by one.
Yes, you will eventually assemble that truck, but how long will it take you?
How does this relate to programming?
In Functional Programming, state typically is being isolated. You always know where some state is coming from. State is never scattered across your different functions. In OOP, every object has its own state, and when building a program , you have to keep in mind the state of all of the objects that you currently are working with.
To make our lives easier, it is best to have only a very small portion of the codebase deal with state. Let the core parts of your application be stateless and pure. This actually is the main reason for the huge success of the flux pattern on the frontend (aka Redux).
Promiscuously shared state
As if our lives aren’t already hard enough because of having scattered mutable state, OOP goes one step further!
Real-world Example, Please!
Mutable state in the real world is almost never a problem, since things are kept private and never shared. This is “proper encapsulation” at work. Imagine a painter who is working on the next Mona Lisa painting. He is working on the painting alone, finishes up, and then sells his masterpiece for millions.
Now, he’s bored with all that money and decides to do things a little bit differently. He thinks that it would be a good idea to have a painting party. He invites his friends elf, Gandalf, policeman, and a zombie to help him out. Teamwork! They all start painting on the same canvas at the same time. Of course, nothing good comes out of it — the painting is a complete disaster!
Shared mutable state makes no sense in the real world. Yet this is exactly what happens in OOP programs — state is promiscuously shared between various objects, and they mutate it in any way they see fit. This, in turn, makes reasoning about the program harder and harder as the codebase keeps growing.
Concurrency issues
The promiscuous sharing of mutable state in OOP code makes parallelizing such code almost impossible. Complex mechanisms have been invented in order to address this problem. Thread locking, mutex, and many other mechanisms have been invented. Of course, such complex approaches have their own drawbacks — deadlocks, lack of composability, debugging multi-threaded code is very hard and time-consuming. I’m not even talking about the increased complexity caused by making use of such concurrency mechanisms.
Not all state is evil
Is all state evil? No, Alan Kay state probably is not evil! State mutation probably is fine if it is truly isolated (not the “OOP-way” isolated).
It is also completely fine to have immutable data-transfer-objects. The key here is “immutable”. Such objects are then used to pass data between functions.
However, such objects would also make OOP methods and properties completely redundant. What’s the use in having methods and properties on an object if it cannot be mutated?
Mutability is Inherent to OOP
Some might argue that mutable state is a design choice in OOP, not an obligation. There is a problem with that statement. It is not a design choice, but pretty much the only option. Yes, one can pass immutable objects to methods in Java/C#, but this is rarely done since most of the developers default to data mutation. Even if developers attempt to make proper use of immutability in their OOP programs, the languages provide no built-in mechanisms for immutability, and for working effectively with immutable data (i.e. persistent data structures).
Yes, we can ensure that objects communicate only by passing immutable messages and never pass any references (which is rarely done). Such programs would be more reliable than mainstream OOP. However, the objects still have to mutate their own state once a message has been received. A message is a side effect, and its single purpose is to cause changes. Messages would be useless if they couldn’t mutate the state of other objects.
It is impossible to make use of OOP without causing state mutations.
The Trojan Horse of Encapsulation
We’ve been told that encapsulation is one of the greatest benefits of OOP. It is supposed to protect the object’s internal state from outside access. There’s a small problem with this though. It doesn’t work.
Encapsulation is the trojan horse of OOP. It sells the idea of shared mutable state by making it appear safe. Encapsulation allows (and even encourages) unsafe code to sneak into our codebase, making the codebase rot from within.
The global state problem
We’ve been told that global state is the root of all evil. It should be avoided at all costs. What we have never been told is that encapsulation, in fact, is glorified global state.
To make the code more efficient, objects are passed not by their value, but by their reference. This is where “dependency injection” falls flat.
Let me explain. Whenever we create an object in OOP, we pass references to its dependencies to the constructor. Those dependencies also have their own internal state. The newly created object happily stores references to those dependencies in its internal state and is then happy to modify them in any way it pleases. And it also passes those references down to anything else it might end up using.
This creates a complex graph of promiscuously shared objects that all end up changing each other’s state. This, in turn, causes huge problems since it becomes almost impossible to see what caused the program state to change. Days might be wasted trying to debug such state changes. And you’re lucky if you don’t have to deal with concurrency (more on this later).
Methods/Properties
The methods or properties that provide access to particular fields are no better than changing the value of a field directly. It doesn’t matter whether you mutate an object’s state by using a fancy property or method — the result is the same: mutated state.
The Problem with Real World Modeling
Some people say that OOP tries to model the real world. This is simply not true — OOP has nothing to relate to in the real world. Trying to model programs as objects probably is one of the biggest OOP mistakes.
The real world is not hierarchical
OOP attempts to model everything as a hierarchy of objects. Unfortunately, that is not how things work in the real world. Objects in the real world interact with each other using messages, but they mostly are independent of each other.
Inheritance in the real world
OOP inheritance is not modeled after the real world. The parent object in the real world is unable to change the behavior of child objects at run-time. Even though you inherit your DNA from your parents, they’re unable to make changes to your DNA as they please. You do not inherit “behaviors” from your parents, you develop your own behaviors. And you’re unable to “override” your parents’ behaviors.
The real world has no methods
Does the piece of paper you’re writing on have a “write” method? No! You take an empty piece of paper, pick up a pen, and write some text. You, as a person, don’t have a “write” method either — you make the decision to write some text based on outside events or your internal thoughts.
The Kingdom of Nouns
Objects bind functions and data structures together in indivisible units. I think this is a fundamental error since functions and data structures belong in totally different worlds.
— Joe Armstrong, creator of Erlang
Objects (or nouns) are at the very core of OOP. A fundamental limitation of OOP is that it forces everything into nouns. And not everything should be modeled as nouns. Operations (functions) should not be modeled as objects. Why are we forced to create a Multiplierclass when all we need is a function that multiplies two numbers? Simply have a Multiply function, let data be data and let functions be functions!
In non-OOP languages, doing trivial things like saving data to a file is straightforward — very similar to how you would describe an action in plain English.
Real-world example, please!
Sure, going back to the painter example, the painter owns a PaintingFactory. He has hired a dedicated BrushManager , ColorManager, a CanvasManager and a MonaLisaProvider. His good friend zombie makes use of a BrainConsumingStrategy . Those objects, in turn, define the following methods: CreatePainting , FindBrush , PickColor , CallMonaLisa , and ConsumeBrainz.
Of course, this is plain stupidity, and could never have happened in the real world. How much unnecessary complexity has been created for the simple act of drawing a painting?
There’s no need to invent strange concepts to hold your functions when they’re allowed to exist separately from the objects.
Unit Testing
Automated testing is an important part of the development process and helps tremendously in preventing regressions (i.e. bugs being introduced into existing code). Unit Testing plays a huge role in the process of automated testing.
Some might disagree, but OOP code is notoriously difficult to unit test. Unit Testing assumes testing things in isolation, and to make a method unit-testable:
- Its dependencies have to be extracted into a separate class.
- Create an interface for the newly created class.
- Declare fields to hold the instance of the newly created class.
- Make use of a mocking framework to mock the dependencies.
- Make use of a dependency-injection framework to inject the dependencies.
How much more complexity has to be created just to make a piece of code testable? How much time was wasted just to make some code testable?
> PS we’d also have to instantiate the entire class in order to test a single method. This will also bring in the code from all of its parent classes.
With OOP, writing tests for legacy code is even harder — almost impossible. Entire companies have been created (TypeMock) around the issue of testing legacy OOP code.
Boilerplate code
Boilerplate code is probably the biggest offender when it comes to the signal-to-noise ratio. Boilerplate code is “noise” that is required to get the program to compile. Boilerplate code takes time to write and makes the codebase less readable because of the added noise.
While “program to an interface, not to an implementation” is the recommended approach in OOP, not everything should become an interface. We’d have to resort to using interfaces in the entire codebase, for the sole purpose of testability. We’d also probably have to make use of dependency injection, which further introduced unnecessary complexity.
Testing private methods
Some people say that private methods shouldn’t be tested… I tend to disagree, unit testing is called “unit” for a reason — test small units of code in isolation. Yet testing of private methods in OOP is nearly impossible. We shouldn’t be making private methodsinternal just for the sake of testability.
In order to achieve testability of private methods, they usually have to be extracted into a separate object. This, in turn, introduces unnecessary complexity and boilerplate code.
Refactoring
Refactoring is an important part of a developer’s day-to-day job. Ironically, OOP code is notoriously hard to refactor. Refactoring is supposed to make the code less complex, and more maintainable. On the contrary, refactored OOP code becomes significantly more complex — to make the code testable, we’d have to make use of dependency injection, and create an interface for the refactored class. Even then, refactoring OOP code is really hard without dedicated tools like Resharper.
In the simple example above, the line count has more than doubled just to extract a single method. Why does refactoring create even more complexity, when the code is being refactored in order to decrease complexity in the first place?
Contrast this to a similar refactor of non-OOP code in JavaScript:
The code has literally stayed the same — we simply moved the isValidInput function to a different file and added a single line to import that function. We’ve also added _isValidInput to the function signature for the sake of testability.
This is a simple example, but in practice the complexity grows exponentially as the codebase gets bigger.
And that’s not all. Refactoring OOP code is extremely risky. Complex dependency graphs and state scattered all over OOP codebase, make it impossible for the human brain to consider all of the potential issues.
The Band-aids
What do we do when something is not working? It is simple, we only have two options — throw it away or try fixing it. OOP is something that can’t be thrown away easily, millions of developers are trained in OOP. And millions of organizations worldwide are using OOP.
You probably see now that OOP doesn’t really work, it makes our code complex and unreliable. And you’re not alone! People have been thinking hard for decades trying to address the issues prevalent in OOP code. They’ve come up with a myriad of design patterns.
Design patterns
OOP provides a set of guidelines that should theoretically allow developers to incrementally build larger and larger systems: SOLID principle, dependency injection, design patterns, and others.
Unfortunately, the design patterns are nothing other than band-aids. They exist solely to address the shortcomings of OOP. A myriad of books has even been written on the topic. They wouldn’t have been so bad, had they not been responsible for the introduction of enormous complexity to our codebases.
The problem factory
In fact, it is impossible to write good and maintainable Object-Oriented code.
On one side of the spectrum we have an OOP codebase that is inconsistent and doesn’t seem to adhere to any standards. On the other side of the spectrum, we have a tower of over-engineered code, a bunch of erroneous abstractions built one on top of one another. Design patterns are very helpful in building such towers of abstractions.
Soon, adding in new functionality, and even making sense of all the complexity, gets harder and harder. The codebase will be full of things like SimpleBeanFactoryAwareAspectInstanceFactory, AbstractInterceptorDrivenBeanDefinitionDecorator, TransactionAwarePersistenceManagerFactoryProxyorRequestProcessorFactoryFactory .
Precious brainpower has to be wasted trying to understand the tower of abstractions that the developers themselves have created. The absence of structure is in many cases better than having bad structure (if you ask me).
Further reading: FizzBuzzEnterpriseEdition
The Fall of the Four OOP Pillars
The four pillars of OOP are: Abstraction, Inheritance, Encapsulation, and Polymorphism.
Let’s see what they really are, one-by-one.
Inheritance
I think the lack of reusability comes in object-oriented languages, not in functional languages. Because the problem with object-oriented languages is they’ve got all this implicit environment that they carry around with them. You wanted a banana but what you got was a gorilla holding the banana and the entire jungle.
— Joe Armstrong, creator of Erlang
OOP inheritance has nothing to do with the real world. Inheritance, in fact, is an inferior way to achieve code reusability. The gang of four has explicitly recommended preferring composition over inheritance. Some modern programming languages avoid inheritance altogether.
There are a few problems with inheritance:
- Bringing in a lot of code that your class doesn’t even need (banana and the jungle problem).
- Having parts of your class defined somewhere else makes the code hard to reason about, especially with multiple levels of inheritance.
- In most programming languages, multiple inheritance isn’t even possible. This mostly renders inheritance useless as a code-sharing mechanism.
OOP polymorphism
Polymorphism is great, it allows us to change program behavior at runtime. However, it is a very basic concept in computer programming. I’m not too sure why OOP focuses so much on polymorphism. OOP polymorphism gets the job done but once again it results in the act of mental juggling. It makes the codebase significantly more complex, and reasoning about the concrete method that is being invoked becomes really hard.
Functional programming, on the other hand, allows us to achieve the same polymorphism in a much more elegant way…by simply passing in a function that defines the desired runtime behavior. What could be simpler than that? No need to define a bunch of overloaded abstract virtual methods in multiple files (and the interface).
Encapsulation
As we discussed earlier, encapsulation is the trojan horse of OOP. It is actually a glorified global mutable state and makes the unsafe code appear safe. An unsafe coding practice is a pillar that OOP programmers rely on in their day-to-day job…
Abstraction
Abstraction in OOP attempts to tackle complexity by hiding unnecessary details from the programmer. Theoretically, it should allow the developer to reason about the codebase without having to think about the hidden complexity.
I don’t even know what to say…a fancy word for a simple concept. In procedural/functional languages we can simply “hide” the implementation details in a neighboring file. No need to call this basic act an “abstraction”.
For more details on the fall of OOP pillars, please read Goodbye, Object Oriented Programming
Why Does OOP Dominate the Industry?
The answer is simple, the reptiloid alien race has conspired with the NSA (and the Russians) to torture us programmers to death…
But seriously, Java is probably the answer.
Java is the most distressing thing to happen to computing since MS-DOS.
- Alan Kay, the inventor of object-oriented programming
Java was Simple
When it was first introduced in 1995, Java was a very simple programming language, compared to the alternatives. At that time, the barrier of entry for writing desktop applications was high. Developing desktop applications involved writing low-level win32 APIs in C, and developers also had to concern themselves with manual memory management. The other alternative was Visual Basic, but many probably didn’t want to lock themselves into the Microsoft ecosystem.
When Java was introduced, it was a no-brainer for many developers since it was free, and could be used across all platforms. Things like built-in garbage collection, friendly-named APIs (compared to the cryptic win32 APIs), proper namespaces, and familiar C-like syntax made Java even more approachable.
GUI programming was also becoming more popular, and it seemed that various UI components mapped well to classes. Method autocompletion in the IDEs also made people claim that OOP APIs are easier to use.
Perhaps Java wouldn’t have been so bad had it not forced OOP on developers. Everything else about Java seemed pretty good. Its garbage collection, portability, exception handling features, which other mainstream programming languages lacked, were really great in 1995,
Then C# came along
Initially, Microsoft had been relying heavily on Java. When things started getting awry (and after a long legal battle with Sun Microsystems over Java licensing), Microsoft decided to invest in its own version of Java. That is when C# 1.0 was born. C# as a language has always been thought of as “the better Java”. However, there’s one huge problem — it was the same OOP language with the same flaws, hidden under a slightly improved syntax.
Microsoft has been investing heavily in its .NET ecosystem, which also included good developer tooling. For years Visual Studio has probably been one of the best IDEs available. This, in turn, has led to wide-spread adoption of the .NET framework, especially in the enterprise.
More recently Microsoft has been investing heavily in the browser ecosystem, by pushing its TypeScript. TypeScript is great because it can compile pure JavaScript and adds in things like static type checking. What’s not so great about it is it has no proper support for functional constructs — no built-in immutable data structures, no function composition, no proper pattern matching. TypeScript is OOP-first, and mostly is C# for the browser. Anders Hejlsberg was even responsible for the design of both C# and TypeScript.
Functional languages
Functional languages, on the other hand, have never been backed by someone as big as Microsoft. F# doesn’t count since the investment was minuscule. The development of functional languages is mostly community-driven. This probably explains the differences in popularity between OOP and FP languages.
Time to Move On?
We now know that OOP is an experiment that failed. It is time to move on. It is time that we, as a community, admit that this idea has failed us, and we must give up on it.
Why are we stuck using something that fundamentally is a suboptimal way to organize programs? Is this plain ignorance? I doubt it, the people working in software engineering aren’t stupid. Are we perhaps more worried about “looking smart” in the face of our peers by making use of fancy OOP terms like “design patterns”, “abstraction”, “encapsulation”, “polymorphism” and “interface segregation”? Probably not.
I think that it’s really easy to continue using something that we’ve been using for decades. Most of the people have never really tried Functional Programming. Those who have (like myself) can never go back to writing OOP code.
Henry Ford once famously said — “If I had asked people what they wanted, they would have said faster horses”. In the world of software, most people would probably want a “better OOP language”. People can easily describe a problem they’re having (getting the codebase organized and less complex), but not the best solution.
What Are the Alternatives?
Spoiler alert: Functional Programming.
If terms like functors and monads make you a little uneasy, then you’re not alone! Functional Programming wouldn’t have been so scary had they given more intuitive names to some of its concepts. Functor? That’s simply something we can transform with a function, think list.map. Monad? Simply computations that can be chained!
Trying out Functional Programming will make you a better developer. You will finally have the time to write real code that solves real-world problems, rather than having to spend most of your time thinking about abstractions and design patterns.
You might not realize this, but you already are a functional programmer. Are you using functions in your day-to-day work? Yes? Then you’re already a functional programmer! You just have to learn how to make the best use of those functions.
Two great functional languages with a very gentle learning curve are Elixirand Elm. They let the developer focus on what matters most — writing reliable software while removing all of the complexity that more traditional functional languages have.
What are the other options? Is your organization already is using C#? Give F# a try — it is an amazing functional language, and provides great interoperability with the existing .NET code. Using Java? Then using Scala or Clojure are both really good options. Using JavaScript? With the right guidance and linting, JavaScript can be a good functional language.
The Defenders of OOP
I expect some sort of reaction from the defenders of OOP. They will say that this article is full of inaccuracies. Some might even start calling names. They might even call me a “junior” developer with no real-world OOP experience. Some might say that my assumptions are erroneous, and examples are useless. Whatever.
They have the right to their opinion. However, their arguments in the defense of OOP are usually quite weak. It is ironic that most of them probably have never really programmed in a true functional language. How can someone draw comparisons between two things if you have never really tried both? Such comparisons aren’t very useful.
The Law of Demeter is not very useful — it does nothing to address the issue of non-determinism, shared mutable state is still shared mutable state, no matter how you access or mutate that state. a.total()is not much better than a.getB().getC().total(). It simply sweeps the problem under the rug.
Domain-Driven Design? That’s a useful design methodology, it helps a bit with the complexity. However, it still does nothing to address the fundamental issue of shared mutable state.
Just a tool in a toolbox…
I often hear people say that OOP is just another tool in a toolbox. Yes, it is as much a tool in a toolbox as horses and cars are both tools for transportation… After all, they all serve the same purpose, right? Why use cars when we can continue riding good old horses?
History repeats itself
This actually reminds me of something. At the beginning of the 20th century, automobiles started replacing the horses. In the year 1900 New York had only a few cars on the roads, people have been using horses for transportation. In the year 1917, no more horses were left on the roads. A huge industry was centered around horse transportation. Entire businesses have been created around things like manure cleaning.
And people resisted change. They called automobiles another “fad” that eventually pass. After all, horses have been here for centuries! Some even asked the government to intervene.
How is this relevant? The software industry is centered around OOP. Millions of people are trained in OOP, and millions of companies make use of OOP in their code. Of course, they will try to discredit anything that threatens their bread-and-butter! It’s just common sense.
We clearly see the history repeating itself — in the 20th century it was the horses vs automobiles, in the 21st century it is Object-Oriented vs Functional Programming.
What’s Next?
- Goodbye, Object Oriented Programming by Charles Scalfani
- Object-Oriented Programming Oversold
- The Forgotten History of OOP by Eric Elliott
- Why OO Sucks by Joe Armstrong, creator of Erlang
- Object-Oriented Programming is Bad by Brian Will
- Execution in the Kingdom of Nouns by Steve Yegge
- Was object-oriented programming a failure?














 326
326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









