






1. 数据准备:收集数据与读取
2. 数据预处理:处理数据
3. 训练集与测试集:将先验数据按一定比例进行拆分。
4. 提取数据特征,将文本解析为词向量 。
5. 训练模型:建立模型,用训练数据训练模型。即根据训练样本集,计算词项出现的概率P(xi|y),后得到各类下词汇出现概率的向量 。
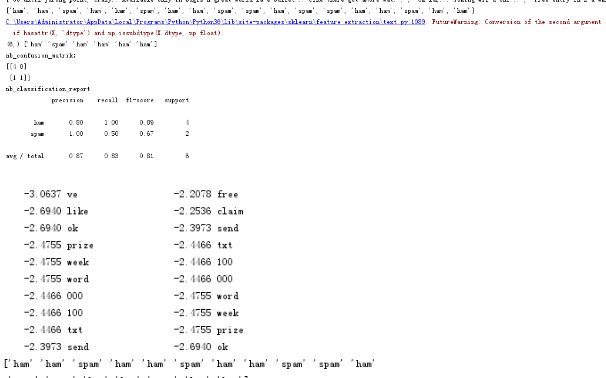
6. 测试模型:用测试数据集评估模型预测的正确率。
混淆矩阵
准确率、精确率、召回率、F值
7. 预测一封新邮件的类别。
import csv file_path = r"C:/Users/sms.txt" sms = open(file_path,'r',encoding = 'utf-8') sms_data = [] sms_label = [] csv_reader = csv.reader(sms,delimiter='\t') for line in csv_reader: sms_label.append(line[0]) sms_data.append(line[1]) sms.close() print("邮件总数:",len(sms_label)) print(sms_data) print(sms_label) #按0.7:0.3比例分为训练集和测试集 import numpy as np sms_data=np.array(sms_data) sms_label=np.array(sms_label) #print(sms_data) #print(sms_label) from sklearn.model_selection import train_test_split#训练集与测试集 a_train,a_test,b_train,b_test = train_test_split(sms_data,sms_label,test_size=0.3,random_state=0,stratify=sms_label) #print(a_train) #print(a_test) #print(b_train) #print(b_test) from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer(min_df = 2,ngram_range=(1,2),stop_words='english',strip_accents='unicode',norm='l2') a1= vectorizer.fit_transform(a_train) a2= vectorizer.transform(a_test) #print(a1) #print(b2) from sklearn.naive_bayes import MultinomialNB clf=MultinomialNB().fit(a1,b_train) y_nb_pred=clf.predict(a2) #print(y_nb_pred) #分类结果显示 from sklearn.metrics import confusion_matrix from sklearn.metrics import classification_report print(y_nb_pred.shape,y_nb_pred)#x_test预测结果 print('nb_confusion_matrik:') cm=confusion_matrix(b_test,y_nb_pred) print(cm) print('nb_classification_report:') cr=classification_report(b_test,y_nb_pred) print(cr) feature_names=vectorizer.get_feature_names() coefs=clf.coef_#先验概率 P(x_i|y),6034 feature_log_prob_ intercept=clf.intercept_#P(y),class_log_prior_:array,shape(n_classes,) coefs_with_fns=sorted(zip(coefs[0],feature_names)) n=10 top=zip(coefs_with_fns[:n],coefs_with_fns[:-(n+1):-1]) for(coef_1,fn_1),(coef_2,fn_2) in top: print('\t%.4f\t%-15s\t\t%.4f\t%-15s'%(coef_1,fn_1,coef_2,fn_2)) print(sms_label) print(len(a_train),len(b_test)) print(a1.shape,a2.shape) print(a_train) print(a1) #预测一封新邮件的类别。 new_email=['新邮件'] vectorizer(new_email) clf.predict(new_email)















 2535
2535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









