






内容总览:
1.scrapy安装与pip更换下载源
2.scrapy创建第一个工程于爬虫文件
1>禁止robots协议
2>UA伪装
3>scrapy的xpath解析
3.scrapy持久化存储
1>基于终端指令(parse必须有一个返回值)
2>基于管道的存储(存储到本地文件)
3>基于管道存储(mysql,redis)
4.scrapy的递归解析
5.scrapy手动发送post请求
1>手动发送post请求
6.scrapy框架的工作流程
1>工作组件的简介
2>工作流程图
7.日志等级
8.请求传参(meta={'item',item})
1>事例1--58同城二手房信息
2>事例2--校花网图片
9.scrapy的中间件
1>下载中间件对请求处理
2>下载中间件对响应进行处理
10.crawlspider全栈数据爬取
1>创建工程
2>事例--抽屉新热榜
11.scrapy的分布式
一.scrapy的安装与更换pip下载源
######################scrapy安装################################
a. pip3 install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
d. pip3 install pywin32
e. pip3 install scrapy
######################pip更换下载源###############################
- windows
(1)打开文件资源管理器(文件夹地址栏中)
(2)地址栏上面输入 %appdata%
(3)在这里面新建一个文件夹 pip
(4)在pip文件夹里面新建一个文件叫做 pip.ini ,内容写如下即可
[global]
timeout = 6000
index-url = https://mirrors.aliyun.com/pypi/simple/
trusted-host = mirrors.aliyun.com
- linux
(1)cd ~
(2)mkdir ~/.pip
(3)vi ~/.pip/pip.conf
(4)编辑内容,和windows一模一样
- 需要安装:
pip install bs4
bs4在使用时候需要一个第三方库,把这个库也安装一下
pip install lxml
二.scrapy创建第一个工程与爬虫文件
1>禁止遵从robots协议
#创建工程 scrapy startproject firstBlood #切换到工程的目录 cd firstBlood #创建爬虫文件 scrapy genspider first www.xxx.com #修改爬虫文件 class FirstSpider(scrapy.Spider): #爬虫文件名称:根据该名称可以定位到一个具体的爬虫文件 name = 'first' #优先级比start_urls高,只获取百度的url页面 # allowed_domains = ['www.baidu.com'] #起始的url列表--按顺序爬取列表中的url # start_urls = ['https://www.sogou.com/','www.baidu.com'] start_urls = ['https://www.sogou.com/'] def parse(self, response): #url请求之后的响应体,parse方法会根据url个数调用url个数的次数 print(response)
#response.text response.body
#终端执行爬虫文件并输出日志 scrapy crawl first #DEBUG: Crawled (200) <GET https://www.sogou.com/robots.txt> (referer: None) #当前状态没有拿到返回的信息,因为settings.py中配置遵从robots协议 #-修改配置 ROBOTSTXT_OBEY = False #执行爬虫文件不输出日志 scrapy crawl first --nolog <200 https://www.sogou.com/>
2>UA伪装
#有UA检测的网站 start_urls = ['https://www.qiushibaike.com/'] scrapy crawl first #[scrapy.downloadermiddlewares.retry] DEBUG: Gave up retrying <GET https://www.qiushibaike.com/> (failed 3 times):
#[<twisted.python.failure.Failure twisted.internet.error.ConnectionDone: Connection was closed cleanly.>] #settings.py中设置UA客户端 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' scrapy crawl first --nolog <200 https://www.qiushibaike.com/>
3>scrapy解析--无需取出页面数据
import scrapy
from firstBlood.items import FirstbloodItem
def parse(self, response): #url请求之后的响应体,parse方法会根据url个数调用url个数的次数 # print(response.body)#二进制的数据 # print(response.text)#字符串型的数据 #scrapy封装了高性能的解析方式 l_lst=response.xpath('//*[@id="qiushi_tag_121132611"]/div/a/text()') print(l_lst[0]) #<Selector xpath='//*[@id="qiushi_tag_121132611"]/div/a/text()' data='什么叫秒怂,这就是~'> #将select方法中的data参数值获取 s_text= response.xpath('//*[@id="qiushi_tag_121435939"]/div[1]/a[2]/h2/text()')[0].extract() scrapy crawl first --nolog <Selector xpath='//*[@id="qiushi_tag_121435939"]/div[1]/a[2]/h2/text()' data='\n薛家小姐姐\n'> #第二种取值的方法--保证列表里只有一个列表元素 s_text= response.xpath('//*[@id="qiushi_tag_121435939"]/div[1]/a[2]/h2/text()').extract_first()
三.scrapy持久化存储
1>基于终端指令(保证parse有一个返回值)
def parse(self, response): div_list=response.xpath('//div[@id="content-left"]/div') # print(div_list) all_data=[] for div in div_list: # xpath返回的是一个列表 #作者名字可能存在不同的标签块里,需要不同的解析方式 author=div.xpath('./div[1]/a[2]/h2/text() | ./div[1]/span/h2/text()').extract_first()#列表中就一个元素的情况 content=div.xpath('.//div[@class="content"]/span//text()').extract()#列表中有多个元素的情况 content=''.join(content).strip() dic={ 'author':author, 'content':content } all_data.append(dic) #持久化存储的俩种方式 #基于终端指令:必须要保证parse方法有一个返回值 return all_data #注意:只能保存指定格式的文件例如csv,json,pickle #终端: scrapy crawl first -o qiubai.csv
2>基于管道的存储(存储到本地文件)
#爬虫文件 from firstBlood.items import FirstbloodItem def parse(self, response): div_list=response.xpath('//div[@id="content-left"]/div') for div in div_list: author=div.xpath('./div[1]/a[2]/h2/text() | ./div[1]/span/h2/text()').extract_first()#列表中就一个元素的情况 content=div.xpath('.//div[@class="content"]/span//text()').extract()#列表中有多个元素的情况 content=''.join(content).strip() #基于管道 #1>将解析到的作者和内容先存到item类型对象中,先要在item中声明要存变量的类型 item=FirstbloodItem() item['author']=author item['content']=content #2>将item类型的对象提交到管道 #3>在管道文件中对接收到的item进行持久化存储 #4>在settings文件中开启管道 yield item #item.py import scrapy class FirstbloodItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() author=scrapy.Field() content=scrapy.Field() #pipelines.py #只要涉及持久化存储的相关操作代码都需要写在该文件中 #将item写入我们的磁盘文件中,返回值返回到text或者mysql或者redis中 class FirstbloodPipeline(object): #根据爬取的数据判断,文件只需要被打开一次即可 #重写父类方法,在子类中只会执行一次 fp=None def open_spider(self,spider): print('开始爬虫') self.fp=open('./qiushibaike.txt','w',encoding='utf-8') def process_item(self, item, spider): # print(item['author'],item['content']) self.fp.write(item['author']+':'+item['content']) return item def close_spider(self,spider): print('结束爬虫') self.fp.close() #settings.py ITEM_PIPELINES = { #300代表优先级,数字越小优先级越高 'firstBlood.pipelines.FirstbloodPipeline': 300, }
3>基于管道的存储(存储到mysql,redis)
import pymysql from redis import Redis class MysqlPipleLine(object): conn=None cursor=None def open_spider(self, spider): self.conn=pymysql.Connect(host='', port=3306, user='root', password='', db='day23spider') print(self.conn) def process_item(self, item, spider): self.cursor=self.conn.cursor() try: self.cursor.execute('insert into qiubai values("%s","%s")'%(item['author'],item['content'])) self.conn.commit() except Exception as e: print(e) self.conn.rollback() return item def close_spider(self, spider): self.cursor.close() self.conn.close() class RedisPileLine(object): conn = None def open_spider(self, spider): self.conn=Redis(host='127.0.0.1',port=6379) print(self.conn) def process_item(self, item, spider): dic={ 'author':item['author'], 'content':item['content'] } self.conn.lpush('qiubai',dic) #settings.py ITEM_PIPELINES = { #300代表优先级,数字越小优先级越高 'firstBlood.pipelines.FirstbloodPipeline': 300, 'firstBlood.pipelines.MysqlPipleLine': 301, 'firstBlood.pipelines.RedisPileLine': 302, } #注意: #redis服务器配置文件--redis.window.conf--注释bind的IP与修改75行的保护模式 #旧版的模块才支持字典直接写入redis #pip install -U redis==2.10.6 #reid-cli 127.0.0.1:6379> keys * 1) "qiubai" 127.0.0.1:6379> lrange qiubai 0 -1
四.scrapy的递归解析--解析其他分页的页码
import scrapy
from firstBlood.items import FirstbloodItem
class FirstSpider(scrapy.Spider): name = 'first' start_urls = ['https://www.qiushibaike.com/text/'] url='https://www.qiushibaike.com/text/page/%d/' page=1 def parse(self, response): div_list=response.xpath('//div[@id="content-left"]/div') for div in div_list: author=div.xpath('./div[1]/a[2]/h2/text() | ./div[1]/span/h2/text()').extract_first()#列表中就一个元素的情况 content=div.xpath('.//div[@class="content"]/span//text()').extract()#列表中有多个元素的情况 content=''.join(content).strip() item=FirstbloodItem() item['author']=author item['content']=content yield item #指定第二页的url并进行请求的发送 if self.page <= 13: print(self.page) self.page +=1 new_url=format(self.url%self.page) yield scrapy.Request(url=new_url,callback=self.parse) #yield使用场景 #1>向管道提交item #2>手动发送请求
五.scrapy手动发送post请求
1>手动发送post请求
import scrapy import json class PostSpider(scrapy.Spider): name = 'post' # allowed_domains = ['www.xxx.com'] start_urls = ['https://fanyi.baidu.com/sug'] def start_requests(self): for url in self.start_urls: data={ 'kw':'dog' } #发送POST请求 yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse) def parse(self, response): ret_json=response.text ret=json.loads(ret_json) print(ret) ###终端执行### scrapy crawl post --nolog {'errno': 0, 'data': [{'k': 'dog', 'v': 'n. 狗; 蹩脚货; 丑女人; 卑鄙小人; v. 困扰; 跟踪;'},
{'k': 'dogs', 'v': 'n. 公狗( dog的名词复数 ); (尤用于形容词后)家伙; [机械学]夹头; 不受欢迎的人;'},
{'k': 'doge', 'v': 'n. 共和国总督;'}, {'k': 'doggy', 'v': 'n. 小犬,小狗; adj. 像狗一样的;'},
{'k': 'doggie', 'v': 'n. 小狗,狗,汪汪;'}]}
六.scrapy框架的工作流程
1>工作组件简介
引擎:
用来处理整个系统的数据流处理,触发事务
调度器:
用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回,可以想象成一个url的优先队列,又它决定下一个抓取的网址,并且去重
下载器:
用于下载网页内容,并将网页内容返回给蜘蛛(简历在twisted这个高效异步模型上)
爬虫文件:
从特定的网页中提取自己需要的信息,即所谓的实体(item)用户也可以从中提取链接,让scrapy取下一个页面
项目管道:
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体,验证实体的有效性,清除不需要的信息.
2>工作流程图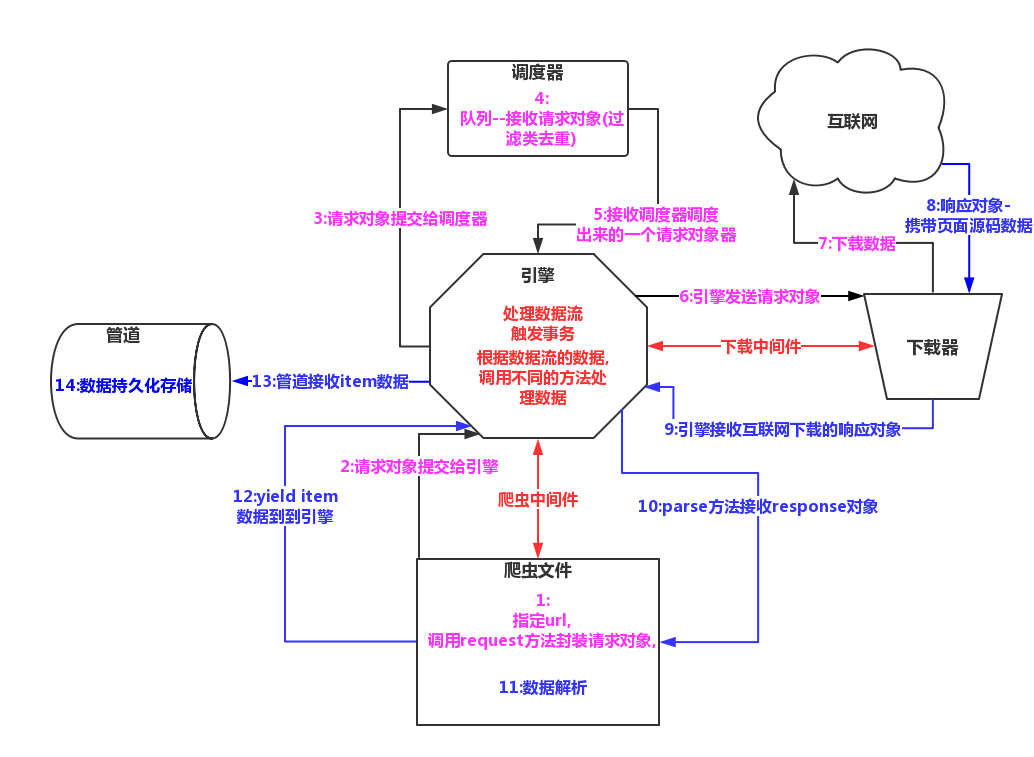
七.scrapy的日志等级
1>日志信息分类:
ERROR:一般错误
WARNING:警告
INFO:一般的信息
DEBUG:调试信息
2>设置日志信息指定输出
#settings.py #只输出error等级的日志 LOG_LEVEL='ERROR' #记录日志到文件中 LOG_FILE='./log.txt'
八.请求传参--(传递item)
1>事例1--58同城二手房信息与其详情页信息抓取
import scrapy from housePro.items import HouseproItem class HouseSpider(scrapy.Spider): name = 'house' # allowed_domains = ['www.xxx.com'] start_urls = ['https://tj.58.com/ershoufang/?utm_source=sem-baidu-pc&spm=105916146735.26420796328&PGTID=0d100000-0001-26d4-4831-908598290f27&ClickID=3'] def parse(self, response): #注意定位标签的正确与否,这里是ul不是div li_list=response.xpath('//ul[@class="house-list-wrap"]/li') for li in li_list: title=li.xpath('./div[2]/h2/a/text()').extract_first() #注意属性是否正确,这里是href不是herf detail_url=li.xpath('./div[2]/h2/a/@href').extract_first()
#注意页面中的url都是不一样的,有的缺少前缀 if detail_url.split('//')[0] !='https:': detail_url='https:'+detail_url price=li.xpath('./div[3]//text()').extract() price=''.join(price).strip() item=HouseproItem() item['title'] = title item['price']=price yield scrapy.Request(url=detail_url,callback=self.parseSecond,meta={'item':item}) # break def parseSecond(self,response): item=response.meta['item']#接受请求传参的数据 detail=response.xpath('//*[@id="generalSituation"]/div//text()').extract() detail=''.join(detail).strip() desc=response.xpath('//*[@id="generalDesc"]/div//text()').extract() desc=''.join(desc).strip() item['desc']=desc item['detail']=detail yield item ###pipelines### class HouseproPipeline(object): def process_item(self, item, spider): # print(len(item)) print(item['desc']) return item
2>事例2--http://www.521609.com/daxuemeinv/?charset=gb2312校花网信息与其图片二进制数据爬取
############爬虫文件中下载图片的二进制数据############ import scrapy from xiaohuaPro.items import XiaohuaproItem class XiaohuaSpider(scrapy.Spider): name = 'xiaohua' # allowed_domains = ['www.xxx.com'] start_urls = ['http://www.521609.com/daxuemeinv/'] def parse(self, response): li_list=response.xpath('//div[@class="index_img list_center"]/ul/li') for li in li_list: item=XiaohuaproItem() item['name']=li.xpath('./a[2]//text()').extract_first() #排错记录--注意extract方法拼写 item['url'] = 'http://www.521609.com' + li.xpath('./a[1]/img/@src').extract_first() # print(item['name'], item['url']) # break yield scrapy.Request(url=item['url'],callback=self.getImgData,meta={'item':item}) def getImgData(self,response): item=response.meta['item'] item['img_data']=response.body yield item #pipelines.py class XiaohuaproPipeline(object): def process_item(self, item, spider): fileName=item['name']+'.jpg' # print('./img/%s'%fileName) with open(r'F:/scrapypro/xiaohuaPro/xiaohuaPro/img/%s'%fileName,'wb') as fp: fp.write(item['img_data']) print(fileName+'下载成功') return item ############提升scrapy框架的效率############ #settings.py LOG_LEVEL='ERROR' #提升日志等级 CONCURRENT_REQUESTS = 32 #开启线程 COOKIES_ENABLED = False #禁止cookie,降低cpu的使用率 RETRY_ENABLED = False #禁止重试 DOWNLOAD_TIMEOUT = 10 #减少下载超时
九.scrapy框架的中间件
1>下载中间件对请求进行处理----更换UA与代理IP
####settings中开启下载中间件####################
DOWNLOADER_MIDDLEWARES = {
'xiaohuaPro.middlewares.XiaohuaproDownloaderMiddleware': 543,
}
#middewares.py
class XiaohuaproDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
#拦截请求对象
def process_request(self, request, spider):
#设置请求对象的代理IP
if request.url.split(':')[0]=='http':
request.meta['proxy']='http://106.14.162.110:8080'
print(request)
else:
print('使用https的代理')
request.headers['User-Agent']='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1'
return None
##############可以使用IP代理池##################
#可被选用的代理IP
PROXY_http = [ '153.180.102.104:80', '195.208.131.189:56055', ]
PROXY_https = [ '120.83.49.90:9000', '95.189.112.214:35508', ]
class Proxy(object): def process_request(self, request, spider):
#对拦截到请求的url进行判断(协议头到底是http还是https)
#request.url返回值:http://www.xxx.com h = request.url.split(':')[0]
#请求的协议头
if h == 'https':
ip = random.choice(PROXY_https)
request.meta['proxy'] = 'https://'+ip
else:
ip = random.choice(PROXY_http)
request.meta['proxy'] = 'http://' + ip
2>下载中间件对响应进行处理--替换响应对象
#########爬虫文件####################### import scrapy from selenium import webdriver from newsPro.items import NewsproItem class NewsSpider(scrapy.Spider): name = 'news' def __init__(self): self.bro=webdriver.Chrome(executable_path=r'F:\pywork\day22\chromedriver.exe') # allowed_domains = ['www.xxx.com'] start_urls = ['http://news.163.com/domestic/'] def parse(self, response): res=response.xpath('/html/body/div/div[3]/div[4]/div[1]/div/div/ul/li/div/div[6]/div/div[1]/h3/a/text()').extract_first() print(res) def closed(self,spider): self.bro.quit() #settings.py DOWNLOADER_MIDDLEWARES = { 'newsPro.middlewares.NewsproDownloaderMiddleware': 543, } ############中间件对响应对象的替换######### from scrapy import signals from scrapy.http import HtmlResponse import time class NewsproDownloaderMiddleware(object): def process_request(self, request, spider): return None #浏览器不需要实例化多次 def process_response(self, request, response, spider): bro=spider.bro #浏览器发起请求页码数据 bro.get(request.url) js = 'window.scrollTo(0,document.body.scrollHeight)' bro.execute_script(js) #等待浏览器的缓冲加载数据的时间 time.sleep(3) #获取页码源码数据是包含了动态加载出来的新闻数据 page_text=bro.page_source new_response =HtmlResponse(url=bro.current_url,body=page_text,encoding='utf-8',request=request) return new_response
十.crawlspider全栈数据爬取
1>创建工程
scrapy startproject choutiPro
注意:新建爬虫文件的参数
scrapy genspider -t crawl chouti www.xxx.com
2>事例--抽屉新热榜分页数据爬取
##############爬虫文件############### import scrapy #链接提取器 from scrapy.linkextractors import LinkExtractor #规则提取器 from scrapy.spiders import CrawlSpider, Rule class ChoutiSpider(CrawlSpider): name = 'chouti' # allowed_domains = ['www.xxx.com'] start_urls = ['https://dig.chouti.com/r/scoff/hot/1'] #链接提取器,对起始url对应的页面源码中提取符合要求的链接 #allow参数的值表示的是一个正则表达式 link=LinkExtractor(allow=r'/r/scoff/hot/\d+') rules = ( #规则解析器对象 #follow参数会将链接提取器作用到每一个页码, # 如果产生了新的页码会继续作用直至所有页码, # 调度器会自动去重重复的请求对象 Rule(link, callback='parse_item', follow=True), ) def parse_item(self, response): #链接提取器作用到哪个页码的页面,会将页面中产生的所有页码对应的url进行请求 print(response)
十一.scrapy的分布式
1>准备工作
必备的模块--pip3 install scrapy-redis
1.爬虫文件的修改 --导包:from scrapy_redis.spiders import RedisCrawlSpider --爬虫类的父类修改成RedisCrawlSpider --删除start_urls属性 --添加一个属性:redis_key ='xxx' 该属性表示的就是可以被共享的调度器中队列的名称 2.爬虫文件提交的item,提交到可以被共享的管道中,在配置中添加 ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 400} 3.需要将爬虫文件中产生的请求对象全部提交到可以被共享的调度器中,添加配置 # 使用scrapy-redis组件的去重队列 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis组件自己的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 是否允许暂停 SCHEDULER_PERSIST = True 4.在配置文件中进行数据库的配置: REDIS_HOST = 'redis服务的ip地址' REDIS_PORT = 6379 REDIS_ENCODING = ‘utf-8’ REDIS_PARAMS = {‘password’:’123456’} 5.redis的配置文件中 - 注释bind, - 取消保护模式 6.开启redis的服务端和客户端 7.执行当前的爬虫文件:scrapy runspider redisDemo.py 名称+后缀 8.从redis客户端扔入一个起始的url - lpush chouti www.xxx.com - keys * - lrange xxx 0 -1
2>代码实现
############爬虫文件#################
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from scrapy_redis.spiders import RedisCrawlSpider from redis_choutiPro.items import RedisChoutiproItem class RedisdemoSpider(RedisCrawlSpider): name = 'redisDemo' # allowed_domains = ['www.xxx.com'] # start_urls = ['http://www.xxx.com/'] redis_key = 'chouti' rules = ( Rule(LinkExtractor(allow=r'/r/pic/hot/\d+'), callback='parse_item', follow=True), ) def parse_item(self, response): div_list = response.xpath('//div[@id="content-list"]/div') for div in div_list: item = RedisChoutiproItem() item['title']=div.xpath('./div[3]/div[1]/a/text()').extract_first() item['author']=div.xpath('./div[3]/div[2]/a[4]/b/text()').extract_first() yield item ##############settings文件############## #item提交到scrapy_redis中可以被共享的管道类中 ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 400 } # 使用scrapy-redis组件的去重队列 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis组件自己的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 是否允许暂停 SCHEDULER_PERSIST = True REDIS_HOST = '127.0.0.1' REDIS_PORT = 6379 # REDIS_ENCODING = 'utf-8' # REDIS_PARAMS = {'password':''}
#################终端在爬虫文件夹中执行#######################
F:\scrapypro\redis_choutiPro\redis_choutiPro\spiders> scrapy runspider ./redisDemo.py















 9009
9009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









