






一、什么是 Python
Python (蟒蛇)是一门简单易学、 优雅健壮、 功能强大、 面向对象的解释型脚本语言.具有 20+ 年发展历史, 成熟稳定. 具有丰富和强大的类库支持日常应用。
1989 年, 罗萨姆想要开发出一套工具完成日常系统管理任务, 能够访问分布式操作系统 Amoeba 的系统调用. 于是从 1989 年底开始创作通用性开发语言Python.
二、为什么选择 Python
语言都有使用场景,只有合适和不合适
语言是工具,想法(思路&算法)是基础
三、Python 的优势
简单易学
简单、易学、免费、开源、可移植、可扩展、可嵌入、面向对象等优点
功能健全,能满足我们工作中绝大多数需求的开发
通用语言,几乎可以用在任何领域和场合,可以跨平台使用,目前各 Linux系统都默认安装 Python 运行环境
社区,是否有一个完善的生态系统
pypi, github, StackOverFlow , oschina
成功案例
国内:豆瓣、知乎、盛大、BAT、 新浪、网易…
国外:谷歌、YouTube、Facebook、红帽…
四、Python 有哪些使用场景
系统管理任务
Web 编程
图形处理、多媒体应用
文本处理(爬虫)
数学处理(数据分析、机器学习)
网络编程
游戏开发
黑客( POC 脚本、木马)
自动化测试
运维开发
云计算
五、什么是爬虫
按照一定规则自动的获取互联网上的信息(随着网络的迅速发展,互联网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战)
应用
搜索引擎(Google、百度、Bing等搜索引擎,辅助人们检索信息)
股票软件(爬取股票数据,帮助人们分析决策,进行金融交易)
Web扫描(需要对网站所有的网页进行漏洞扫描)
获取某网站最新文章收藏
爬取天气预报
爬取漂亮mm照片
给空间朋友点赞
......

六、实战项目
1、项目目标
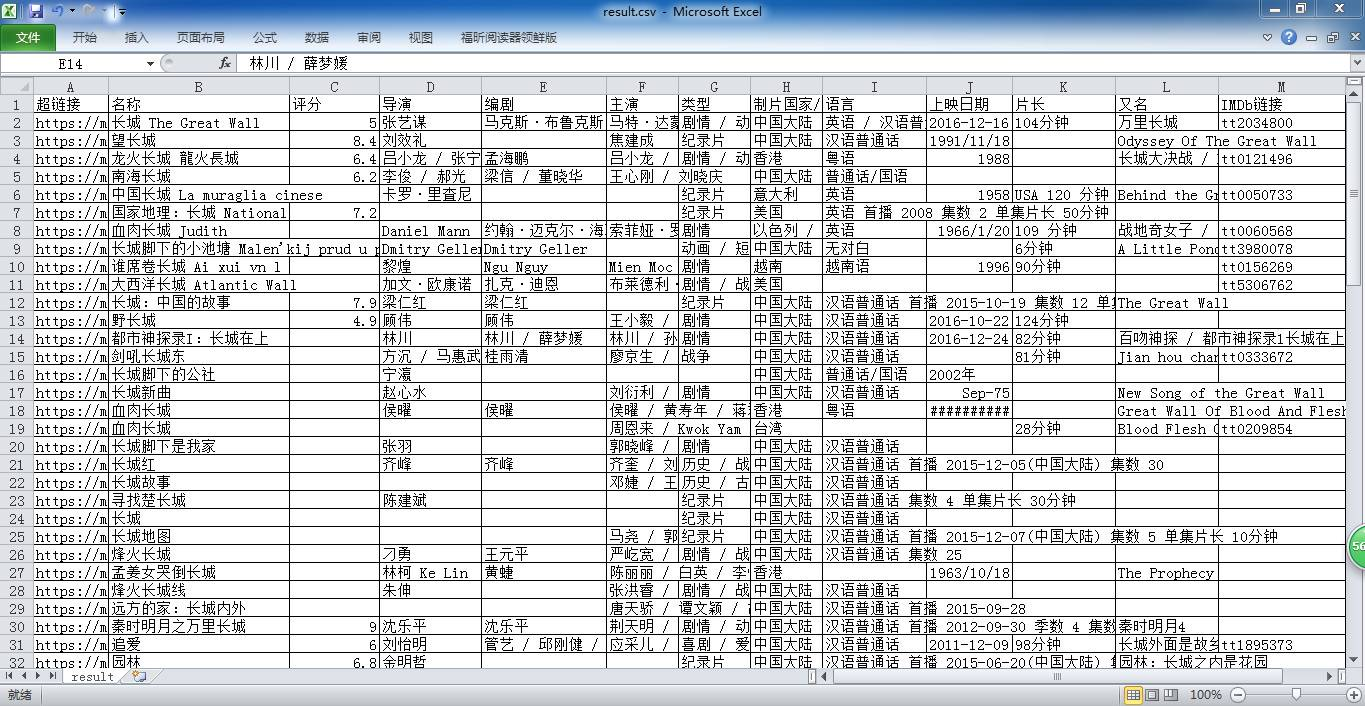
目标:在豆瓣中获取自己喜欢的TOP N电影信息
2、基础知识
HTTP 协议
客户端发起请求,服务器接收到请求后返回格式化的数据,客户端接收、解析并处理数据
HTML(超文本标记语言)
Python
基础语法
模块
>>>常用系统模块
>>>第三方模块安装&使用
>>>pip install requests
>>>pip install pyquery

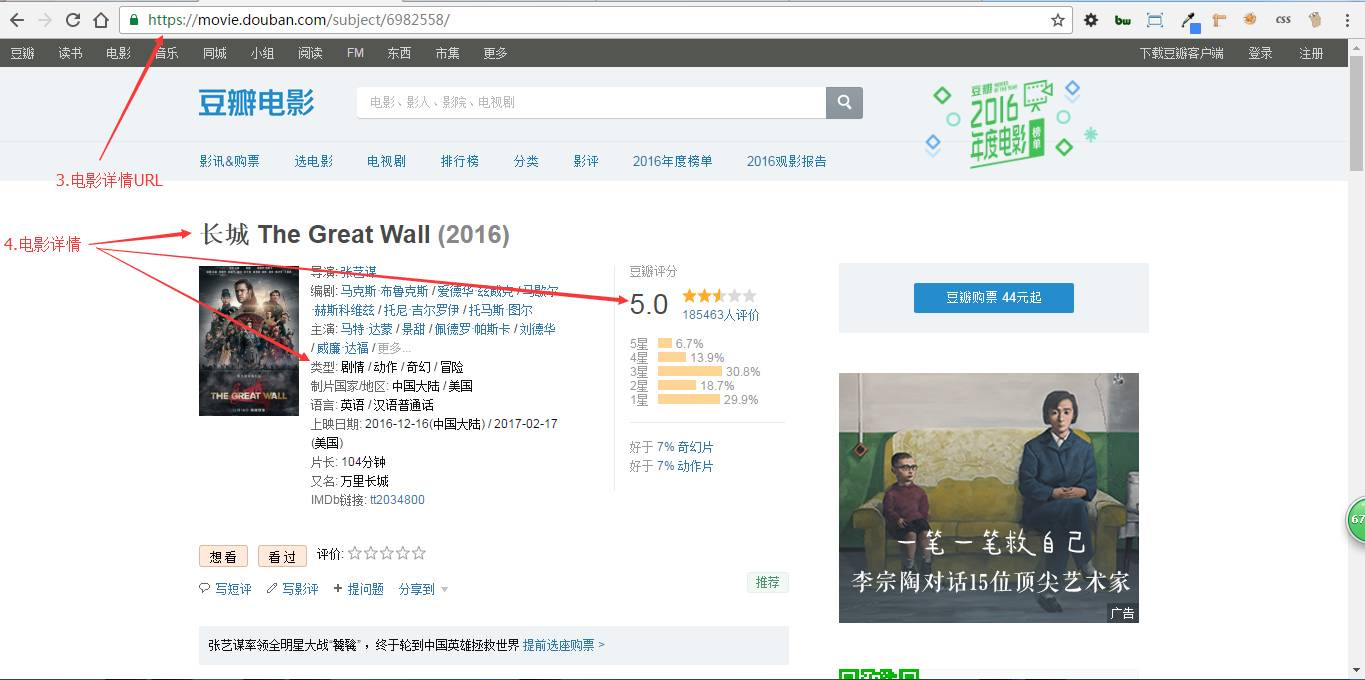
3、手动搜索
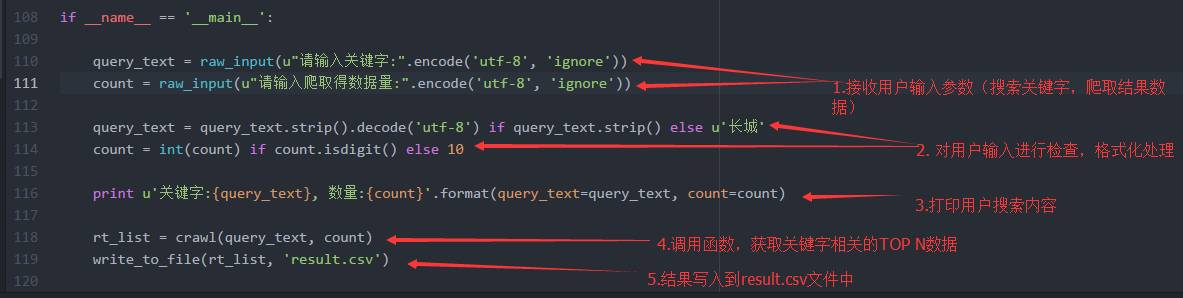
4、程序启动
5、获取电影列表

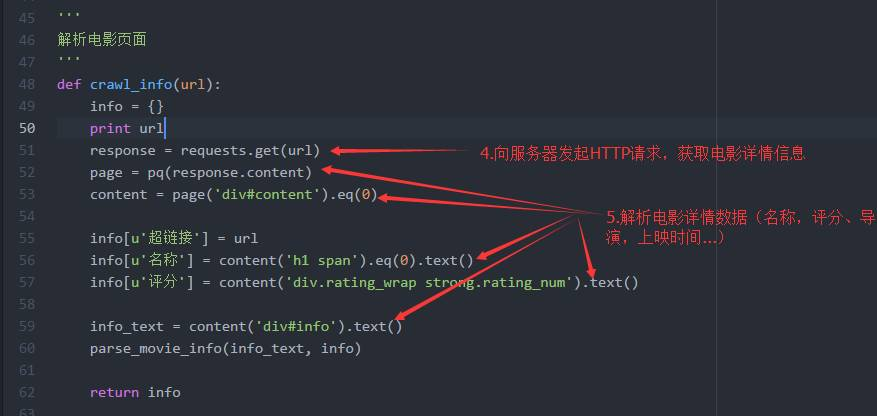
6、获取电影详情
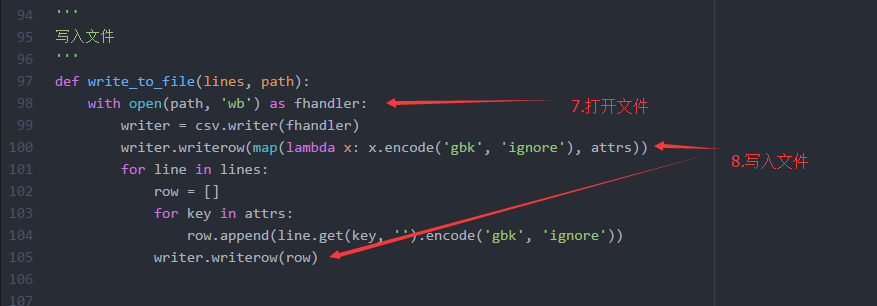
7、写入csv文件
如何学习 Python
多抄、多写、多想、多问、多看、多听、多说
学习编程是为了解决实际的问题,把自己在工作或学习中的重复工作程序化
谷歌和度娘
加入开源社区(多看、多分享、多交流)
交流QQ群:238757010















 938
938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









