







最近学习音乐自动标注的过程中,看到了有关使用MFCC提取音频特征的内容,特地在网上找到资料,学习了一下相关内容。此笔记大部分内容摘自博文 http://blog.csdn.net/zouxy09/article/details/9156785 有小部分标注和批改时我自己加上的,以便今后查阅。
语音信号处理之(四)梅尔频率倒谱系数(MFCC)
在任意一个Automatic speech recognition 系统中,第一步就是提取特征。换句话说,我们需要把音频信号中具有辨识性的成分提取出来,然后把其他的乱七八糟的信息扔掉,例如背景噪声啊,情绪啊等等。
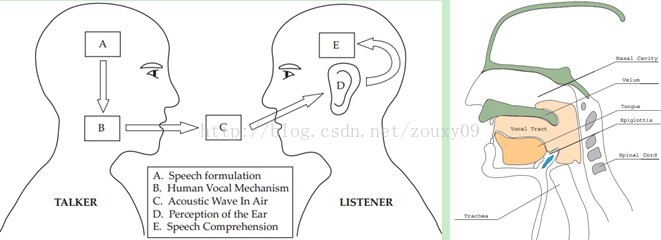
搞清语音是怎么产生的对于我们理解语音有很大帮助。人通过声道产生声音,声道的shape(形状?)决定了发出怎样的声音。声道的shape包括舌头,牙齿等。如果我们可以准确的知道这个形状,那么我们就可以对产生的音素phoneme进行准确的描述。声道的形状在语音短时功率谱的包络中显示出来。而MFCCs就是一种准确描述这个包络的一种特征。
MFCCs(Mel Frequency Cepstral Coefficents)是一种在自动语音和说话人识别中广泛使用的特征。它是在1980年由Davis和Mermelstein搞出来的。从那时起。在语音识别领域,MFCCs在人工特征方面可谓是鹤立鸡群,一枝独秀,从未被超越啊(至于说Deep Learning的特征学习那是后话了)。
好,到这里,我们提到了一个很重要的关键词:声道的形状,然后知道它很重要,还知道它可以在语音短时功率谱的包络中显示出来。哎,那什么是功率谱?什么是包络?什么是MFCCs?它为什么有效?如何得到?下面咱们慢慢道来。
一、声谱图(Spectrogram)
我们处理的是语音信号,那么如何去描述它很重要。因为不同的描述方式放映它不同的信息。那怎样的描述方式才利于我们观测,利于我们理解呢?这里我们先来了解一个叫声谱图的东西。
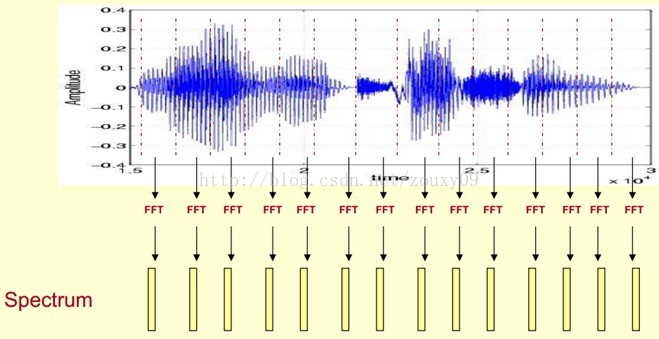
这里,这段语音被分为很多帧,每帧语音都对应于一个频谱(通过短时FFT计算),频谱表示频率与能量的关系。在实际使用中,频谱图有三种,即线性振幅谱、对数振幅谱、自功率谱(对数振幅谱中各谱线的振幅都作了对数计算,所以其纵坐标的单位是dB(分贝)。这个变换的目的是使那些振幅较低的成分相对高振幅成分得以拉高,以便观察掩盖在低幅噪声中的周期信号)。
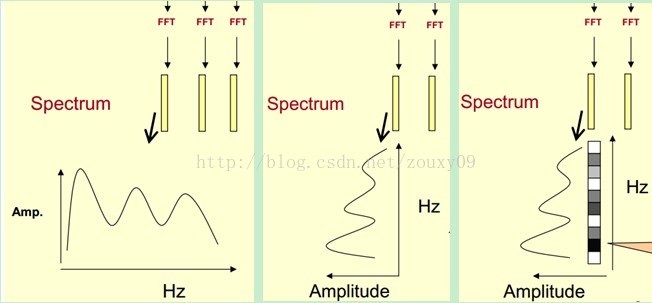
我们先将其中一帧语音的频谱通过坐标表示出来,如上图左。现在我们将左边的频谱旋转90度。得到中间的图。然后把这些幅度映射到一个灰度级表示(也可以理解为将连续的幅度量化为256个量化值?),0表示黑,255表示白色。幅度值越大,相应的区域越黑。这样就得到了最右边的图。那为什么要这样呢?为的是增加时间这个维度,这样就可
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









