






摘要
提出了一种基于波利亚-伽马数据扩增和诱导点的可扩展随机变分方法。与以往的方法不同,我们获得了基于自然梯度的封闭式更新,从而得到有效的优化。我们在包含多达 1100 万个数据点的真实数据集上评估了该算法,证明它比目前的状态快了两个数量级,同时就精度而言,它也具有竞争性。
1、 介绍
高斯过程(GPs)提供了一种流行的贝叶斯非线性非参数的回归和分类方法。由于 GPs 能够精确地适应数据,从而在提供良好校准的不确定性估计的同时实现高预测精度,因此它是几个应用领域的标准方法,包括地理空间预测建模和机器人学。
然而,最近科学技术中数据可用性的趋势使得开发能够处理海量数据的算法变得很有必要。目前,GP 分类对大数据的适用性有限。朴素推理通常按数据点的数量来衡量,而精确计算后验概率和边际概率是很难的。
尽管如此,所谓的稀疏高斯过程技术与近似推断方法的结合,如期望传播(EP)或变分方法,已使对包含数百万数据点的数据集的 GP 分类成为可能。
虽然这些结果已经令人印象深刻,但我们将在这篇论文中展现,可以实现两个数量级的加速。我们的方法是基于考虑一个增强版本的原始 GP 分类模型和用更有效的自然梯度代替普通(随机)梯度进行优化,即标准欧几里得梯度乘以逆费雪信息矩阵。近年来,自然梯度已成功地应用于各种变分推理问题。
遗憾的是,一个对于 GP 分类问题中自然梯度的有效计算不是直接的。Dezfouli 等人对 probit 链接函数的使用,导致变分目标函数中的期望只能通过数值求积计算,因此,阻止了有效的优化。
我们针对 GP 分类的变分推理提出了一种基于 logit 链接的自然梯度方法。我们开发了相应的可能性,有一个辅助变量表示作为一个包含波利亚-伽马随机变量的连续高斯混合。
与以前的方法不同,我们的自然梯度更新可以用封闭的形式计算。此外,它们的优势在于它们对应于块坐标提升更新,因此,可以选择接近自己的学习率。这就形成了一个快速、稳定、易于实现的算法。我们的主要贡献如下:
- 我们提出了一个使用 logit 链接函数的高斯过程分类模型,其基于波利亚-伽马数据扩增和高斯过程推理的诱导点。
- 我们推出了一个基于随机变分推理和自然梯度的有效推理算法。所有的自然梯度更新都以封闭形式给出,不依赖于数值求积方法或采样方法。自然梯度的优势在于它们提供了有效的二阶优化更新。
- 在我们的实验中,我们证明了我们的方法将速度提高了两个数量级,同时在预测性能方面具有竞争力。我们将我们的方法应用于含有高达 1100 万个点的真实世界的大规模数据集,其展现优越的可伸缩性。
论文组织如下。在第二节中,我们将讨论相关的工作。在第 3 节,我们介绍了我们的新可扩展的 GP 分类模型,在第 4 节,我们提出了一个有效的变分推理算法。第 5 部分以实验结尾。我们的代码可以通过 Github 获得。
2、 背景及相关工作
高斯过程分类 Hensman 和 Matthews(2015)用 probit 逆链路函数考虑高斯过程分类,并提出了建立在诱导点上的变分高斯模型。通过使用自动微分,Salimbeni、Eleftheriadis 和 Hensman(2018)推广了这种方法,在非共轭 GP 模型中使用自然梯度。Khan 和 Nielsen(2018)在指数族的变分推理设置中考虑了自然梯度更新。与我们的方法不同的是,这些方法不能从封闭形式的更新中获益,必须诉诸于数值逼近。此外,我们的方法还有一个优势,即可以选择接近一个的较高学习率,从而得到可以解释为块坐标提升改变的更新。
Izmailov、Novikov 和 Kropotov(2018)使用张量序列分解来允许训练具有数十亿诱导点的 GP 模型。更新不是以封闭的形式计算的,他们不使用自然的梯度。
Dezfouli 和 Bonilla(2015)提出了一种用于非共轭似然稀疏 GP 模型的通用自动变分推理方法。由于它们遵循黑箱方法,并且不利用模型特定的属性,因此它们不使用有效的优化技术。
Hernandez-Lobato 和 Hernandez-Lobato(2016)采用了基于诱导点的期望传播方法,其计算成本与 Hensman 和 Matthews(2015)相似。
波利亚-伽马数据扩增 Polson、Scott 和 Windle(2013)从使用波利亚-伽马分布类的逻辑模型中引入了数据增强的想法。这允许通过吉布斯(Gibbs)抽样或近似变分推理方案进行精确推断。
Linderman、Johnson 和 Adams(2015)将这一思想扩展到多项模型,并讨论了具有多项观测值的高斯过程的应用,但他们的方法不适用于大数据集,也没有考虑诱导点的概念。
3、 模型
logit GP 分类模型定义如下。

3.1 波利亚-伽马数据扩增
由于似然函数的分析形式不方便,logit GP 分类的推理是一个具有挑战性的问题。我们的目的是通过考虑原始模型的扩增表示来解决这个问题。稍后我们将看到,扩充模型确实是有利的,因为它在我们的变分推理方案中导致有效的封闭形式更新。
Polson、Scott 和 Windle(2013)引入了波利亚-伽马随机变量类,并提出了二项概率模型中用于推理的数据扩增策略。扩增模型有一个吸引人的特性,即在扩增波利亚-伽马变量的条件下,隐函数

的似然性与高斯密度成正比。这就允许使用吉布斯采样方法,其中模型参数和波利亚-伽马变量可以从后验 Polson、Scott 和 Windle(2013)交替取样。另外,该扩增方案也可用于在变分推理框架中推导出一种高效的近似推理算法。

由矩量母函数(3)可直接计算出一阶矩


有趣的是,将一种结构化的平均场变分推理方法(第 4 节)应用于简单的的波利亚-伽马扩增模型(5),得到了由 Gibbs 和 MacKay(2000)推导的 GP 分类的相同界限。这是关于此边界的一个有趣的新视角,因为它们不使用数据扩充方法。我们的方法超越了 Gibbs 和 MacKay(2000),提供了一个完全的贝叶斯观点,包括模型中的稀疏 GP 先验(第 3.2 节),并提出了一个基于自然梯度的可扩展推理算法(第 4 节)。
3.2 稀疏高斯过程


4、 推理
贝叶斯推理的目标是计算潜在模型变量的后验值。由于该问题对于现有模型来说是难以处理的,我们采用变分推理将推理问题映射为可行的优化问题。首先选取一组可处理的变分分布,并通过最小化变分分布与后验值之间的 KL(Kullback-Leibler)散度来选择最优候选变量。这相当于在边际上相似地优化一个下界,称为证据下界(ELBO)。
下面,我们开发了一个随机变分推理(SVI)算法,以封闭的形式使随机优化基于自然梯度更新。
4.1 为什么使用自然梯度?
在标准欧氏梯度上使用自然梯度是有利的,因为自然梯度对变分族的重新参数化是不变的,同时 Amari (1998)、Hoffman 等人(2013)提供有效的二阶优化更新。
在我们的方法中使用自然梯度的优越性可以如下解释。我们将 GP 分类模型重构为一个有条件共轭的扩增模型。当学习率为 1 时,自然梯度更新对应于块坐标上升更新,即在每次迭代中,给定剩余参数,将每个参数设置为最优值。在实际应用中,我们采用随机变分推理,即我们只使用小批量的数据来获得自然梯度的一个有噪版本。在这种情况下,必须选择学习率略小于 1 的。
这与以前的基于自然梯度的方法形成了对比,例如 Salimbeni、Eleftheriadis 和 Hensman(2018),这些方法侧重于原始的非共轭 GP 分类模型。虽然它们从使用自然梯度中获益,但它们也有缺点,即它们的更新与坐标上升更新不一致。因此,学习速度要小得多,来确保收敛。
因此,我们在实验中证明了,我们的方法中可以使用更高的学习率和更快和更稳定的优化速度。
4.2 变分近似


4.3 随机变分推理






5、 实验
我们比较我们提出的方法、有效的高斯过程分类(X-GPC),用在包 GPflow 中提供的最先进的方法 SVGPC,它由 Hernandez-Lobato 和 Hernandez-Lobato(2016)建立在 TensorFlow 和 EP 方法 EPGPC 之上,由 R 语言实现。所有的方法都应用于包含多达 1100 万数据点的实际数据集。
在所有的实验中,均使用了一个平方指数协方差函数,该函数的每个维度都有一个共同的长度尺度参数、一个振幅参数和一个附加的噪声参数。内核超参数被初始化为相同的值,并使用 Adam 进行优化,而诱导点的定位是通过 k-means++进行初始化,并在训练中保持固定。SVI 基础方法、X-GPC 和 SVGPC 都使用自适应学习率。所有算法都在一个 CPU 上运行。我们实验了来自 OpenML 网站和 UCI 知识库的 12 个数据集,数据点数量在 768 万到 1100 之间。在第一个实验(5.1 节)中,我们检查了 X-GPC 提供的近似的质量。在接下来的实验中,我们评估了 X-GPC、SVGPC 和 EPGPC 在几个真实数据集上的预测性能和运行时间。最后,在 5.3 中,我们检查了所有方法对诱导点数目的敏感性。
5.1 近似值的质量
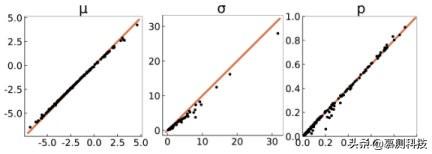
我们经验地检验了由我们的方法所提供的变分近似的质量。在图 1 中,我们比较了近似值和用渐近正确的吉布斯采样器获得的真正后验值。我们比较后验均值和方差以及预测概率与准确性。由于吉布斯采样器不适用于大型数据集,我们在小型糖尿病数据集上进行实验。在图一中,我们画出近似值与实际值的对比图。我们发现我们的近似值非常接近真实的后验值。

5.2 数值比较
表 1:平均检验预测误差,负检验对数似然(NLL)和时间(秒)以及一个标准差。最佳值已被突出显示。

我们对 X-GPC 方法以及与之竞争的 SVGPC 和 EPGPC 方法的预测性能和运行时间进行了评价。我们在各种不同的数据集上进行实验,并在表 1 中报告每种方法的预测误差、负检验对数似然和运行时间。
实验进行如下。对于每个数据集,我们执行 10 次交叉验证,对于超过 100 万的数据集,我们将测试集限制为 10 万。我们报告平均预测误差、负检验对数似然(14)和运行时间以及一个标准偏差。对于所有数据集,我们使用 100 个诱导点并将小批量的规模设为 100 个点。
对于 X-GPC,我们发现以下对全局参数的样本收敛标准可以得到很好的结果:滑动窗口平均值小于 10^-4 的阈值。不幸的是,SVGPC 和 EPGPC 的初始实现没有包含收敛标准。我们发现,SVGPC 的全局参数轨迹有较大的噪声,而使用全局参数的收敛准则往往会导致较差的结果。为了进行公平的比较,我们因此监控在一个预留集合上的预测性能的收敛性,并对所有方法使用平均大小为 5 的滑动窗口和 10^-3 的阈值作为收敛准则。
我们观察到 X-GPC 在大多数数据集中比 SVGPC 和 EPGPC 快一到两个数量级。仅在数据集 wXa 上,EPGPC 略快于 X-GPC。所有方法的预测误差都是相似的,但 X-GPC 在大多数数据集(aXa、银行营销、点击预测、Cod RNA、糖尿病、电力、German、Higgs、Mnist、SUSY)的测试对数似然方面优于竞争对手。这意味着预测中的置信水平在 X-GPC 中得到了更好的校准,也就是说,在预测错误的标签时,SVGPC 和 EPGPC 往往比 X-GPC 有信心。
性能作为时间函数 由于所有考虑的方法都基于一个优化方案,因此在算法的运行时间和预测性能之间存在权衡。我们通过在每个数据集上绘制预测性能作为时间函数,使这种权衡透明。对于每一种方法,我们在预留测试集上,监测 10 倍交叉验证的平均负检验对数似然和预测误差作为时间函数。
所选三个数据集的结果显示在图 2 中。对于所有的数据集,我们观察到,经过几次迭代后,因为其有效的封闭式自然梯度更新,X-GPC 已经接近最优。X-GPC 的预测误差和检验对数似然收敛速度都比 SVGPC 和 EPGPC 快 1 到 2 个数量级。此外,SVGPC 的性能曲线往往比 X-GPC 和 EPGPC 的噪声更大。对于 HIGGS 和 IJCNN 数据集,EPGPC 的最终预测性能稍微好一些,但运行时的成本比 X-GPC 低 4 个数量级(约为 28 小时 vs 9 小时 435 秒)。
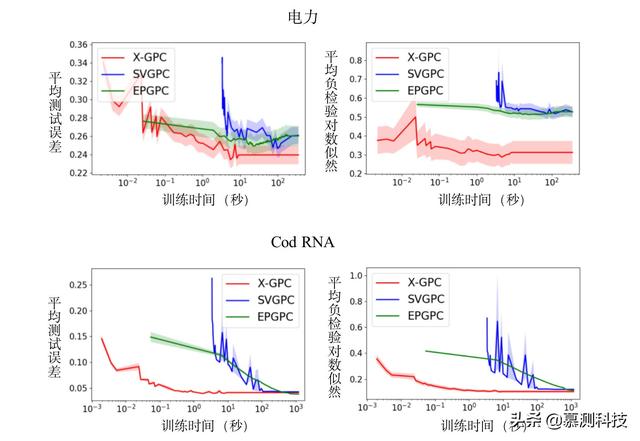
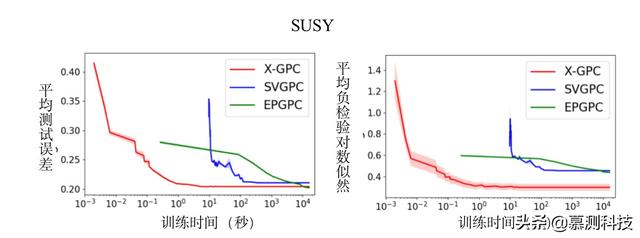
图 2:数据集 Electricity(45,312 点)、Cod RNA(343,564 点)和 SUSY(500 万点)上的平均负检验对数似然以及平均测试预测误差作为训练时间函数(以 log10 为单位的秒)。X-GPC (本文提出的)在经过几次迭代后就能接近最优值,而 SVGPC 和 EPGPC 要慢一到两个数量级。

图 3:对于 Shuttle 数据集,预测误差作为训练时间的函数(以 log10 为单位的秒)。考虑不同个数的诱导点,M =16、32、64、128。X-GPC (本文提出的)在所有不同诱导点数量的设置下收敛速度最快。仅使用 32 个诱导点就可以获得所有方法的最优预测性能,但是 SVGPC 在小于 128 个诱导点的情况下会变得不稳定。
这三种方法都是在不同的编程框架中实现的: X-GPC 利用 Julia、SVGPC 利用 TensorFlow、EPGPC 利用 R,导致了不同的高效实现。然而,我们发现我们方法的主要加速来自于有效的自然梯度更新,只与使用不同的编程语言略有关联。为了验证这一点,我们也在 Julia 中实现了 EPGPC,并获得了类似的运行时间。因为 SVGPC 是高度优化的 GPflow 包的一部分,所以我们只使用原始的实现。
5.3 诱导点
我们研究了不同诱导点个数对预测性能和运行时间的影响。对于所有的方法,我们比较不同数量的诱导点:M =16、32、64、128。对于每个设置,我们对 Shuttle 数据集执行 10 次交叉验证,并绘制出平均预测误差作为时间函数。结果如图 3 所示。我们观察到,诱导点数目越多,预测性能越好,但运行时间越长。在所有诱导点的设置中,我们的方法始终比竞争对手快一到两个数量级。对于航天飞机数据集,使用 M = 32 个诱导点就足够了,对于所有的方法,使用更多的诱导点只能略有改进。但当诱导点小于 128 时,SVGPC 的性能曲线不稳定。
6、 结论
我们提出了一种基于波利亚-伽马数据扩增和诱导点的高斯过程分类方法。实验评估表明,我们的方法比最先进的方法快两个数量级,同时在预测性能方面具有竞争力。速度的提高是由于波利亚-伽马数据扩增方法,实现了有效的二阶优化。
本文的工作说明了数据扩增如何加速 GPs 的变分逼近。我们的分析可能为使用数据扩增得到有效的随机变分算法铺平道路,也适用于变分贝叶斯模型,而不是 GPs。此外,未来的工作可能致力于将该方法扩展到多类和多标签分类。
致谢
本论文由 iSE 实验室 2020 级硕士生顾雪晴转述。















 1413
1413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









