






LDA: 有监督降维
Scikit(摘录):
Linear DiscriminantAnalysis (LDA) tries to identify attributes that account for the most variance between classes. (类间变化最大) In particular, LDA, in contrast to PCA, is asupervised method, using known class labels.
博客(摘录):
LDA的计算:要找到一个向量w,将数据x投影到w上去之后,得到新的数据y。第一,为了实现投影后的两个类别的距离较远,用映射后两个类别的均值差的绝对值来度量。第二,为了实现投影后,每个类内部数据点比较聚集,用投影后每个类别的方差来度量。
类内近:最小方差;类间远:最大均值距离
python使用代码:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
lda = LDA(n_components = 2)
X_l = lda.fit(X,y).transform(X)
plt.figure()
colors = ['navy', 'turquoise', 'darkorange']
lw = 2
for color, i ,target_name in zip(colors, [0,1,2], target_names):
plt.scatter(X_l[y ==i ,0], X_r[y ==i,1], color = color,alpha = .8,
lw = lw, label = target_name)
plt.legend(loc = 'best', shadow = False, scatterpoints = 1)
plt.title('PCA of IRIS dataset')
plt.show()
PCA: 无监督降维
最小二乘、最大方差准则下的低维空间投影。
PPCA:
设x:数据空间的随机向量,z:投影空间的随机向量。首先明白一点在于,知道了p(z|x)的分布,就相当于知道了PCA如何投影。而p(z|x)的求解是要使用贝叶斯定理,所以先假设z的先验分布,p(z);其次由投影的原理构造p(x|z),即x = Wz + mu + epsilon. 其中的参数W, mu, sigma^2可由最大似然求的,从而得到p(z|x)。
需要理解的一个问题在于:PPCA可以自动地确定子空间的维度。这是由于p(z|x)的分布是由最大似然求解出的,因此W已知,即维度D*M已知,所以M已知。
PCA python代码:
pca = PCA(n_components = 2)
X_r = pca.fit(X).transform(X)
plt.figure()
colors = ['navy', 'turquoise', 'darkorange']
lw = 2
for color, i ,target_name in zip(colors, [0,1,2], target_names):
plt.scatter(X_r[y ==i ,0], X_r[y ==i,1], color = color,alpha = .8,
lw = lw, label = target_name)
plt.legend(loc = 'best', shadow = False, scatterpoints = 1)
plt.title('PCA of IRIS dataset')
plt.show()IPCA(增式PCA):
PCA有以下限制:scikit(摘录) The biggest limitation is that PCA only supports batch processing, which means all of the data to be processed must fit in main memory.
因此,为了解决该问题,提出了IPCA。其主要思想在于:使用minibatch,允许部分计算(partial computations)。
代码关键在于ipca = IncrementalPCA(n_components=n_components, batch_size=10)生成实例使用IncrementalPCA类。
n_components = 2
ipca = IncrementalPCA(n_components=n_components, batch_size=10)
X_ipca = ipca.fit_transform(X)
pca = PCA(n_components=n_components)
X_pca = pca.fit_transform(X)PCA SVD:
在PCA的推导中,不论使用最小误差形式还是使用最大方差形式,我们都可以把PCA问题的求解写成求相应矩阵S的最大特征值对应的特征向量问题(参考PRML书中562页)。因此,通过SVD来求解是自然的方法。在python中应用的方法在于加入可选参数 svd_solver='randomized'。
Kernel_PCA:
将原空间利用kernel trick变换到特征空间,即
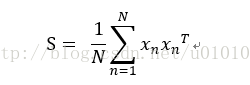
变换为
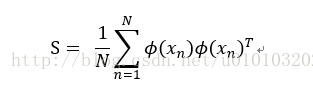
由此PCA变为在特征空间上的求解问题。注意到kernelPCA与PCA区别在于矩阵S的维度不同,PCA为数据维度D而kernelPCA维度为数据量N。
代码:
实例化一个kpca:
kpca = kernelPCA(kernel = 'rbf', fit_inverse_transform = True, gamma = 10)
执行kernelPCA变换:
X_t = kpca.fit_transform(X)
#等价的: X_t = kpca.fit(X).transform(X)
执行投影后的反变换:
X_tt = kpca.inverse_transform(X_t)
Sparse PCA:
稀疏PCA的主要作用在于产生的低维投影中的每个分量是稀疏的(相较PCA得到了稠密分量的子空间)。举人脸的例子来说,就是将每个特征脸(PCA的结果)变成大部分区域为0,仅剩鼻子或者眼睛等部分区域的特征脸(Sparse PCA)
MiniBatchSparsePCA(n_components=n_components, alpha=0.8,
n_iter=100, batch_size=3,
random_state=rng)Factor Analysis:

FA与PCA的区别在于其协方差在不同方向可取不同的值,其效果近似。PPCA中W可吸收数据的旋转,而FA中phi可以吸收数据的尺缩。
ICA:
1.首先需要直觉上理解线性高斯隐变量为什么无法分辨独立分量
ANS:因为高斯隐变量的线性模型下,对于空间数据的旋转具有不变性,因此对于两个旋转关系的数据是无法分辨的;从原理上讲,线性模型下的高斯隐变量中的投影数据是相互无关的(协方差矩阵对角化),但是这个条件不是充分条件。
2.ICA属于线性模型、隐变量非高斯的情形,x=Wz。
ica = FastICA(n_components = 3)
S_it = ica.fit_transform(X)总结PPCA、FA和ICA中的概率原理:
建立在隐藏变量假设的基础上,即x=Wx + u + e。通过假设隐藏变量的概率分布,可以分别得到p(z)和p(x|z)。从而通过概率原理得到x的边缘概率分布p(x)。接着对p(x)进行最大似然估计P(x; W,u,e)即可。
PPCA、FA和ICA的区别在于ICA假设z不服从高斯分布。ICA中 x = Wz。
Reference:
scikit-learn 降维部分(代码来自示例)















 4420
4420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









