






遇到的问题:网站设置了简单的反爬虫规则:数字防爬,如:这样的。
解决方法:直接获取0-9的编码加入字典以此替换。
代码如下:
import requests,re,time,xlwt headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' } end_list = [] replace_dict={ "":"0", "":"1", "":"2", "":"3", "":"4", "":"5", "":"6", "":"7", "":"8", "":"9"} def get_links(url): wb_data = requests.get(url,headers=headers) wb_data.encoding=wb_data.apparent_encoding links = re.findall('class="name-box clearfix".*?href="(.*?)"',wb_data.text,re.S) for link in links: get_infos('https://www.shixiseng.com'+link) def get_infos(url): wb_data = requests.get(url,headers=headers) wb_data.encoding=wb_data.apparent_encoding salarys = re.findall('class="job_money cutom_font">(.*?)</span>',wb_data.text,re.S) addresses = re.findall('class="job_position">(.*?)</span>',wb_data.text,re.S) educations = re.findall('class="job_academic">(.*?)</span>',wb_data.text,re.S) jobways = re.findall('class="job_week cutom_font">(.*?)</span>',wb_data.text,re.S) months = re.findall('class="job_time cutom_font">(.*?)</span>',wb_data.text,re.S) jobgoods = re.findall('class="job_good".*?>(.*?)</div>',wb_data.text,re.S) contents = re.findall(r'div class="job_til">([\s\S]*?)<div class="job_til">', wb_data.text, re.S)[0].replace(' ','').replace('\n', '').replace(' ', '') contents = re.sub(r'<[\s\S]*?>', "", str(contents)) #requires = re.findall(r'class="job_detail".*?>font-size:14px;>([\s\S]*?)</span>',wb_data.text,re.S) for salary,address,education,jobway,month,jobgood in zip(salarys,addresses,educations,jobways,months,jobgoods): for key, vaule in replace_dict.items(): salary = salary.replace(key, vaule) jobway = jobway.replace(key,vaule) month = month.replace(key,vaule) list=[url,salary,address,education,jobway,month,jobgood,contents] end_list.append(list) if __name__ == '__main__': try: urls = ['https://www.shixiseng.com/it/{}'.format(str(i)) for i in range(1,10)] q = 1 for url in urls: print('正在打印第%d页'%q) q+=1 get_links(url) time.sleep(3) book = xlwt.Workbook(encoding='utf-8') sheet = book.add_sheet('newjobmessage') header = ['网址','日薪','地址','学历','上班要求','实习期','福利','要求'] for h in range(len(header)): sheet.write(0,h,header[h]) i = 1 for list in end_list: j = 0 for data in list: sheet.write(i,j,data) j+=1 i+=1 book.save('123.xls') except: print('endprocess')
效果图: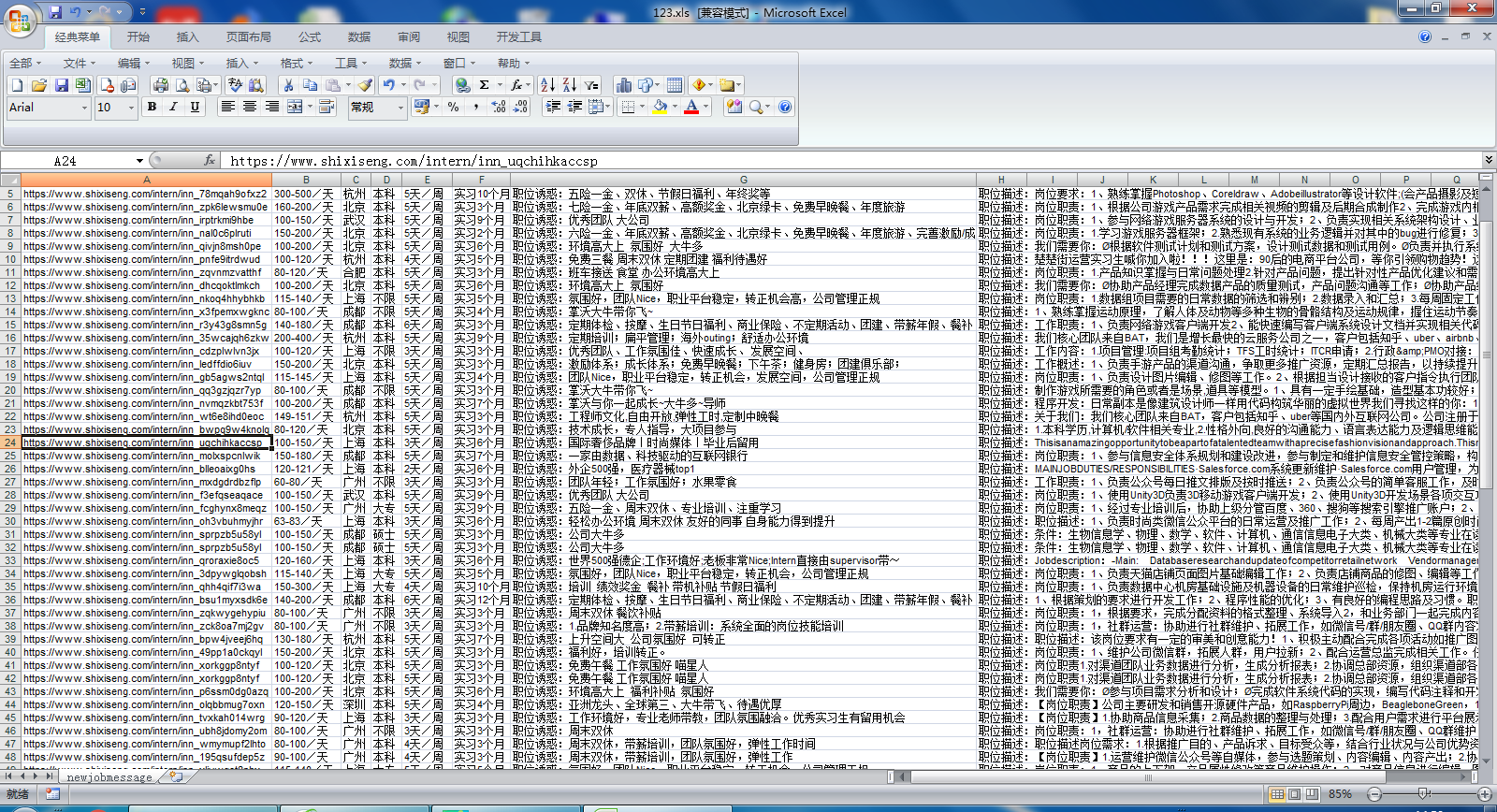















 1066
1066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









