






原理:
给定n个权值作为n个叶子结点,构建一棵二叉树,若带权值路径长度达到最小,称这样的二叉树为哈夫曼树。
Huffman树是一种特殊的二叉树,其叶结点的编码是一种前缀码,同时,通过统计字符的频度,能够达到编码电文的最小化。
假设有n个权值,则构造出的哈夫曼树有n个叶子结点。n个权值分别设为w1、w2、···、wn,则哈夫曼树的构造规则为:
(1) 将w1、w2、···、wn看成有n棵树的森林(每棵树仅有一个结点);
(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3) 将新树加入森林中;
(4) 重复(2)、(3)步,直到森林中的树都被比较过为止,该树即为所求得的哈夫曼树。
实现步骤:
1.建立哈夫曼树前先根据权值对结点进行从小到大的排序1...n;
2.哈夫曼树的总结点数为2*n-1,新节点下标从n+1到2*n-1新节点从小到大产生;
3.最小结点和次小结点在旧结点未加入树里的最小两个结点和新结点未被加入到树里的最小的两个结点总共四个结点中产生;设置旧结点未加入树里的最小结点的下标为kfirst,新节点未被加入到树里的最小结点的下标为ksum:
(1)当产生第一个新结点即下标为n+1的结点时,最小结点和次小结点的下标分别是1和2;
(2)当产生第二个新结点即下标为n+2的结点时,最小结点和次小结点的下标在3,4和n+1中产生;
(3)当产生新结点的下标大于n+2时,最小结点和次小结点的下标在kfirst,kfirst+1和ksum,ksum+1中产生;
画图显示蓝色表示新节点,红色表示旧结点:

总流程图,红色表示旧结点:
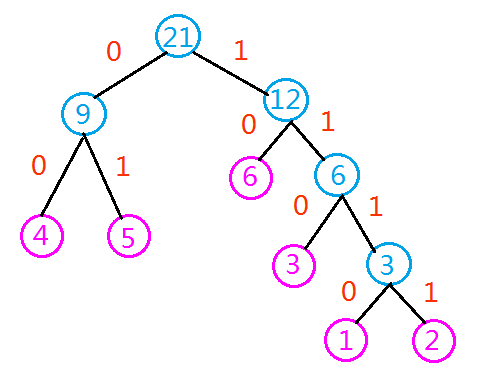
C语言源代码:
1 #include<stdio.h> 2 #include<stdlib.h> 3 #include<malloc.h> 4 #include<string.h> 5 typedef struct{ 6 unsigned int weight;//权值 7 unsigned int parent, lchild,rchild;//父结点,左孩子,右孩子 8 }HTNode,*HuffmanTree; 9 typedef char ** HuffmanCode; 10 //旧结点根据权值由小到大排序 11 int sort(HuffmanTree t,int n) 12 { 13 int i,j,k; 14 for(i=1;i<n;i++){ 15 for(j=1;j<=n-i;j++) 16 if(t[j].weight>t[j+1].weight) 17 { 18 k=t[j].weight; 19 t[j].weight=t[j+1].weight; 20 t[j+1].weight=k; 21 } 22 } 23 return 1; 24 } 25 //找出未被加入树里的最小结点和次小结点下标 26 int Select(HuffmanTree HT,int n,int *s1,int *s2,int i,int &kfirst,int &ksum) 27 { 28 if(i==n+1) 29 { 30 *s1=1; 31 *s2=2; 32 kfirst=3; 33 ksum=n+1; 34 } 35 else{ 36 int b[4]={0,0,0,0}; 37 int index[4]; 38 int ii,j; 39 //把旧结点中未加入树中的最小和次小值加到b数组中 40 for(j=0, ii=kfirst;ii<kfirst+2&&ii<=n&&j<4;ii++,j++){ 41 b[j]=HT[ii].weight; 42 index[j]=ii; 43 } 44 //把新结点中未加入树中的最小和次小值加到b数组中 45 for(j=j, ii=ksum;ii<ksum+2&&ii<=i-1&&j<4;ii++,j++){ 46 b[j]=HT[ii].weight; 47 index[j]=ii; 48 } 49 //把最小值和次小值得下标分别放到index[0]和index[1]中 50 for(int aa=0;aa<2;aa++){ 51 if(aa==0){ 52 for(int k=1;k<4&&b[k]>0;k++){ 53 if(b[0]>b[k]){ 54 int temp=b[0]; 55 int subtemp=index[0]; 56 b[0]=b[k]; 57 index[0]=index[k]; 58 b[k]=temp; 59 index[k]=subtemp; 60 } 61 } 62 } 63 else{ 64 for(int k=2;k<4&&b[k]>0;k++){ 65 if(b[1]>b[k]){ 66 int temp=b[1]; 67 int subtemp=index[1]; 68 b[1]=b[k]; 69 index[1]=index[k]; 70 b[k]=temp; 71 index[k]=subtemp; 72 } 73 } 74 } 75 } 76 *s1=index[0]; 77 *s2=index[1]; 78 //找出旧结点中未加入到树中的最小结点对应的下标kfirst和新结点中未加入到树中的最小结点对应的下标ksum 79 if(index[1]==kfirst+1&&kfirst+2<=n){ 80 kfirst=kfirst+2; 81 }else if(index[1]==ksum+1&&ksum+2<=2*n-1){ 82 ksum=ksum+2; 83 } 84 else{ 85 kfirst=kfirst+1; 86 ksum=ksum+1; 87 } 88 } 89 return 1; 90 } 91 92 void HuffmanCoding(HuffmanTree &HT,HuffmanCode &HC,int *w,int n,int &kfirst,int &ksum) 93 { 94 int i,m,s1,s2,start; 95 char *cd; 96 unsigned int c,f; 97 if(n<=1) exit(1); 98 m=2*n-1; 99 for(i=n+1;i<=m;i++) 100 { 101 HT[i].parent=0; 102 } 103 //产生新节点 104 for(i=n+1;i<=m;i++) 105 { 106 Select(HT,n,&s1,&s2, i,kfirst,ksum); 107 HT[s1].parent=i;HT[s2].parent=i; 108 HT[i].lchild=s1;HT[i].rchild=s2; 109 HT[i].weight=HT[s1].weight+HT[s2].weight; 110 } 111 HC=(HuffmanCode )malloc((n+1)*sizeof(char* )); 112 cd=(char *)malloc(n*sizeof(char )); 113 cd[n-1]='\0'; 114 for(i=1;i<=n;i++) 115 { 116 HC[i]=(char*)malloc((n-start)*sizeof(char)); 117 start=n-1; 118 for(c=i,f=HT[i].parent;f!=0;c=f,f=HT[f].parent) 119 { 120 if(HT[f].lchild==c) 121 { 122 cd[--start]='0'; 123 } 124 else 125 { 126 cd[--start]='1'; 127 } 128 129 strcpy(HC[i],&cd[start]); 130 } 131 } 132 free(cd); 133 } 134 void main() 135 { 136 HuffmanTree HT; 137 HuffmanCode HC; 138 int *w,n,j,K; 139 int i,m,s1,s2;//i为结点的下标,m为总结点数,s1为最小结点下标,s2为次小结点的下标 140 int kfirst=0,ksum=0;//旧结点未加入树里的最小结点的下标kfirst,新节点未被加入到树里的最小结点的下标ksum: 141 HuffmanTree p; 142 char *cd; 143 printf("结点的个数为:\n"); 144 scanf("%d",&n); 145 w=(int *)malloc(n*sizeof(int)); 146 for(i=1;i<=n;i++) 147 { 148 printf("第%d个结点的权值为:",i); 149 scanf("%d",w+i-1); 150 } 151 if(n<=1) exit(1); 152 m=2*n-1;//总结点数 153 HT=(HuffmanTree)malloc((m+1)*sizeof(HTNode)); 154 for(i=1;i<=n;i++,w++) 155 { 156 HT[i].weight=*w; 157 HT[i].parent=0; 158 HT[i].lchild=0; 159 HT[i].rchild=0; 160 } 161 sort(HT, n); 162 HuffmanCoding(HT,HC,w, n,kfirst,ksum); 163 for(i=1;i<=n;i++) 164 { 165 printf("权值为%d结点的哈夫曼编码:",HT[i].weight); 166 puts(HC[i]); 167 } 168 for(i=1;i<=n;i++) 169 free(HC[i]); 170 free(HC); 171 free(HT); 172 }
运行结果:

Java源代码:
1 import java.util.Scanner; 2 3 //结点类 4 class HTNode { 5 int weight; 6 int parent, lchild, rchild; 7 } 8 9 public class HuffmanDemo { 10 static int[] s = new int[3]; 11 static int kfirst = 1;//旧结点未加入树里的最小结点的下标kfirst 12 static int ksum;//新节点未被加入到树里的最小结点的下标ksum: 13 14 public static void main(String[] args) { 15 HuffmanDemo hf = new HuffmanDemo(); 16 17 int n; 18 System.out.println("结点的个数为:"); 19 Scanner sc = new Scanner(System.in); 20 n = sc.nextInt(); 21 ksum = n + 1;//新结点从n+1开始,由小到大产生 22 HTNode[] HT = new HTNode[2 * n];//总结点数为2*n-1,从下标1开始 23 for (int i = 0; i <= 2 * n - 1; i++) { 24 HT[i] = new HTNode(); 25 } 26 hf.input(n, HT); 27 StringBuilder[] HC = new StringBuilder[n + 1]; 28 hf.sort(HT, n); 29 StringBuilder[] hcret; 30 hcret = hf.HuffmanCoding(HT, HC, n); 31 for (int i = 1; i <= n; i++) { 32 System.out.print("权值为" + HT[i].weight + "结点的哈夫曼编码:"); 33 System.out.println(hcret[i].reverse()); 34 } 35 } 36 37 // 输入结点权值 38 void input(int n, HTNode[] HT) { 39 Scanner sc = new Scanner(System.in); 40 int[] w = new int[20]; 41 int i; 42 for (i = 1; i <= n; i++) { 43 System.out.println("第" + i + "个结点的权值为:"); 44 w[i] = sc.nextInt(); 45 } 46 if (n <= 1) 47 System.exit(1); 48 for (i = 1; i <= n; i++) { 49 HT[i].weight = w[i]; 50 HT[i].parent = 0; 51 HT[i].lchild = 0; 52 HT[i].rchild = 0; 53 } 54 } 55 56 // 结点根据权值由小到大排序 57 int sort(HTNode[] t, int n) { 58 int i, j, k; 59 for (i = 1; i < n; i++) 60 for (j = 1; j <= n - i; j++) 61 if (t[j].weight > t[j + 1].weight) { 62 k = t[j].weight; 63 t[j].weight = t[j + 1].weight; 64 t[j + 1].weight = k; 65 } 66 return 1; 67 } 68 69 // 找出未被加入树里的最小结点和次小结点下标 70 public int[] Select(HTNode[] HT, int n, int[] s, int i) { 71 if (i == n + 1) { 72 s[1] = 1; 73 s[2] = 2; 74 kfirst = 3; 75 ksum = n + 1; 76 } else { 77 int b[] = { 0, 0, 0, 0 }; 78 int index[] = new int[4]; 79 int ii, j; 80 // 把旧结点中未加入树中的最小和次小值加到b数组中 81 for (j = 0, ii = kfirst; ii < kfirst + 2 && ii <= n && j < 4; ii++, j++) { 82 b[j] = HT[ii].weight; 83 index[j] = ii; 84 } 85 // 把新结点中未加入树中的最小和次小值加到b数组中 86 for (ii = ksum, j = j; ii < ksum + 2 && ii <= i - 1 && j < 4; ii++, j++) { 87 b[j] = HT[ii].weight; 88 index[j] = ii; 89 } 90 // 把最小值和次小值得下标分别放到index[0]和index[1]中 91 for (int aa = 0; aa < 2; aa++) { 92 if (aa == 0) { 93 for (int k = 1; k < 4 && b[k] > 0; k++) { 94 if (b[0] > b[k]) { 95 int temp = b[0]; 96 int subtemp = index[0]; 97 b[0] = b[k]; 98 index[0] = index[k]; 99 b[k] = temp; 100 index[k] = subtemp; 101 } 102 } 103 } else { 104 for (int k = 2; k < 4 && b[k] > 0; k++) { 105 if (b[1] > b[k]) { 106 int temp = b[1]; 107 int subtemp = index[1]; 108 b[1] = b[k]; 109 index[1] = index[k]; 110 b[k] = temp; 111 index[k] = subtemp; 112 } 113 } 114 } 115 } 116 s[1] = index[0]; 117 s[2] = index[1]; 118 // 找出旧结点中未加入到树中的最小结点对应的下标kfirst和新结点中未加入到树中的最小结点对应的下标ksum 119 if (index[1] == kfirst + 1 && kfirst + 2 <= n) { 120 kfirst = kfirst + 2; 121 } else if (index[1] == ksum + 1 && ksum + 2 <= 2 * n - 1) { 122 ksum = ksum + 2; 123 } else { 124 kfirst = kfirst + 1; 125 ksum = ksum + 1; 126 } 127 } 128 return s; 129 } 130 131 // 编码 132 StringBuilder[] HuffmanCoding(HTNode[] HT, StringBuilder[] HC, int n) { 133 134 int i, m, start; 135 char[] cd = new char[100]; 136 int c, f; 137 if (n <= 1) 138 System.exit(1); 139 m = 2 * n - 1; 140 for (i = n + 1; i <= m; i++) { 141 HT[i].parent = 0; 142 } 143 for (i = n + 1; i <= m; i++) { 144 int[] ss = new int[3]; 145 int[] sa = new int[3]; 146 sa = Select(HT, n, ss, i); 147 HT[sa[1]].parent = i; 148 HT[sa[2]].parent = i; 149 HT[i].lchild = sa[1]; 150 HT[i].rchild = sa[2]; 151 HT[i].weight = HT[sa[1]].weight + HT[sa[2]].weight; 152 } 153 cd[n - 1] = '\0'; 154 for (i = 1; i <= n; i++) { 155 HC[i] = new StringBuilder(); 156 start = n - 1; 157 for (c = i, f = HT[i].parent; f != 0; c = f, f = HT[f].parent) { 158 if (HT[f].lchild == c) { 159 cd[--start] = '0'; 160 } else { 161 cd[--start] = '1'; 162 } 163 HC[i].append((char) cd[start]); 164 } 165 } 166 return HC; 167 } 168 }
运行结果:
















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









