






configparser模块
configparser用于处理特定格式的文件,看模块名字就知道这应该是用于处理配置文件的,其本质上是利用open来操作文件
指定的格式
以mysql配置文件为例(my.ini)
[client]
default-character-set=utf8
password = your_password
port = 3306
socket = /tmp/mysql.sock
# Here follows entries for some specific programs
# The MySQL server
[wampmysqld]
port = 3306
socket = /tmp/mysql.sock
key_buffer_size = 16M
max_allowed_packet = 1M
sort_buffer_size = 512K
net_buffer_length = 8K
read_buffer_size = 256K
read_rnd_buffer_size = 512K
myisam_sort_buffer_size = 8M
basedir=e:/wamp/bin/mysql/mysql5.6.17
log-error=e:/wamp/logs/mysql.log
datadir=e:/wamp/bin/mysql/mysql5.6.17/data注意的就是如果对文件进行了修改,就需要使用write(fp)函数重新写入文件
获取所有节点信息
sections()
import configparser
config=configparser.ConfigParser()
config.read("my.ini")
ret=config.sections()# 获取配置文件中所有节点的信息。返回一个列表
print ret
################output###############
"['client', 'wampmysqld']"获取指定节点下所有的键值对
items(section, raw=False, vars=None)
config=configparser.ConfigParser()
config.read("my.ini")
ret=config.items('client') #读取[client]节点下的键值对,返回一个元素是元组的列表
print ret
################output###############
"[('default-character-set', 'utf8'), ('password', 'your_password'), ('port', '3306'), ('socket', '/tmp/mysql.sock')]"
获取指定节点下的所有键(选项)
options(section)
config=configparser.ConfigParser()
config.read("my.ini")
ret=config.options('client') #返回一个列表
print ret
################output###############
"['default-character-set', 'password', 'port', 'socket']"
获取指定节点下指定key的值(即选项的值)
get(section, option, raw=False, vars=None)
config=configparser.ConfigParser()
config.read("my.ini")
ret=config.get('client','password')
print ret #your_password
检查,删除,添加节点
config=configparser.ConfigParser()
config.read("my.ini")
#检查配置文件中是否存在这个节点
#has_section(section)
check=config.has_section('client')
print check #True
#添加节点
#add_section(section)添加一个节点,若存在就报错
addSection=config.add_section("mysql")
#将新添加的节点写入到源文件中
#write(fp) 参数为一个文件对象
config.write(open('my.ini','w'))
#删除节点
#remove_section(section)
config.remove_section('mysql')
#写入文件
config.write(open("my.ini",'w'))
检查、删除、设置指定节点内的键值对
config=configparser.ConfigParser()
config.read("my.ini")
#检查有没有这个键值对
has_opt=config.has_option('client','password')
print has_opt #True
#设置一个新的键值对
config.set('client','name','cmustard')
config.write(open("my.ini",'w'))
#删除
config.remove_option('client','name')
config.write(open("my.ini",'w'))
XML模块
XML是实现不同语言或程序之间进行数据交换的协议,XML文件格式如下
a.xml
<root>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year auth="True">2015</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year auth="True">2015</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year auth="True">2014</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</root>导入模块
import xml.etree.ElementTree as ET
或者
from xml.etree import ElementTree as ETxml文件解析,有两种方式
1.利用ElementTree.XML将文件解析成xml对象,这是解析的字符串,需要读取文件
f=open('a.xml','r')
xmlFile=f.read()
f.close()
#将字符串解析成xml特殊对象,root代指xml文件的根节点
root=ET.XML(xmlFile)
print root #<Element 'Root' at 0x32ed7b8>2.利用ElementTree.parse将文件直接解析成xml对象,直接解析文件
tree=ET.parse('a.xml')
#获取xml文件的根节点
root=tree.getroot()
print root #<Element 'Root' at 0x3aedef0>操作xml文件
遍历xml文档所有内容
方式一:解析字符串
f=open('a.xml','r')
xmlFile=f.read()
f.close()
root=ET.XML(xmlFile)
#获取xml的根节点
root=tree.getroot()
#顶层标签
print root.tag #Root
#遍历xml的第二层
for child in root:
#第二层节点标签名和标签属性
print child.tag,child.attrib
print "--------------------"
#遍历第三层
for i in child:
#第三层节点的标签名和内容
print i.tag,i.text```
方式二:直接解析xml文件
tree=ET.parse('a.xml')
#获取xml的根节点
root=tree.getroot()
#顶层标签
print root.tag #Root
#遍历xml的第二层
for child in root:
#第二层节点标签名和标签属性
print child.tag,child.attrib
print "--------------------"
#遍历第三层
for i in child:
#第三层节点的标签名和内容
print i.tag,i.text结果都是
root
country {'name': 'Liechtenstein'}
--------------------
rank 2
year 517888
gdppc 141100
neighbor None
neighbor None
country {'name': 'Singapore'}
--------------------
rank 5
year 518656
gdppc 59900
neighbor None
country {'name': 'Panama'}
--------------------
rank 69
year 518656
gdppc 13600
neighbor None
neighbor None遍历XML中指定的节点
f=open('a.xml','r')
xmlFile=f.read()
f.close()
root=ET.XML(xmlFile)
#或者
tree=ET.parse('a.xml')
#获取xml的根节点
root=tree.getroot()
print root.tag
#遍历xml中的所有year节点
for node in root.iter('year'):
#获取节点标签名和内容
print node.tag,node.text 结果
root
year 2015
year 2015
year 2014修改节点内容
(xml直接解析和字符串解析 代码是不一样的,保存文件的方式不一样)
xml直接解析:删除和设置节点属性
###################直接解析##########################
#利用ElementTree.parse将文件直接解析成xml对象,解析文件
tree=ET.parse('a.xml')
#获取xml文件的根节点
root=tree.getroot()
print root.tag
print [x for x in root.iter()] #遍历所有节点
"[<Element 'root' at 0x351a828>, <Element 'country' at 0x351a860>, <Element 'rank' at 0x351a898>, <Element 'year' at 0x351a8d0>, <Element 'gdppc' at 0x351a908>, <Element 'neighbor' at 0x351a940>, <Element 'neighbor' at 0x351a978>, <Element 'country' at 0x351a9b0>, <Element 'rank' at 0x351a9e8>, <Element 'year' at 0x351aa20>, <Element 'gdppc' at 0x351aa58>, <Element 'neighbor' at 0x351aa90>, <Element 'country' at 0x351aac8>, <Element 'rank' at 0x351ab00>, <Element 'year' at 0x351ab38>, <Element 'gdppc' at 0x351ab70>, <Element 'neighbor' at 0x351aba8>, <Element 'neighbor' at 0x351abe0>]"
#循环所有year节点
for node in root.iter('year'):
#将year的值乘以2
new_name=int(node.text)*2
node.text=str(new_name)
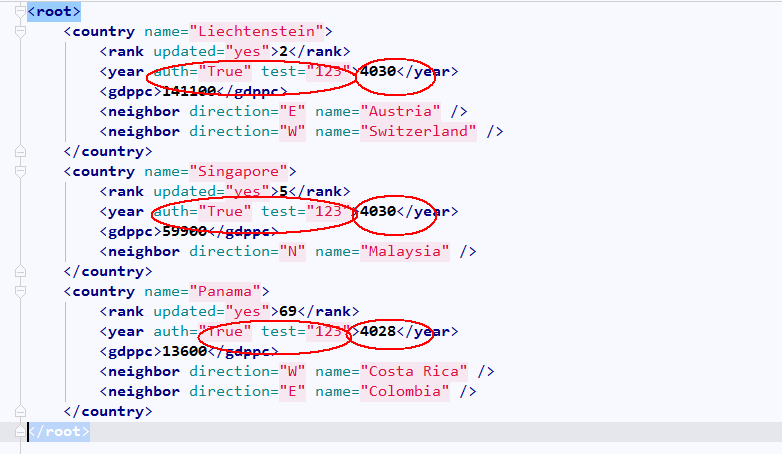
#设置属性<year auth='True' test='123'>
node.set('auth','True')
node.set("test",'123')
#删除属性
del node.attrib['test']
############ 保存文件 ############
#由于对文件做了改动,因此需要重新保存文件
tree.write("a.xml")没删除test之前结果:
删除之后结果:
字符串解析(删除节点)

############ 解析字符串方式打开 ############
# 打开文件,读取XML内容
with open('a.xml','r') as f:
str_xml = f.read()
# 将字符串解析成xml特殊对象,root代指xml文件的根节点
root = ET.XML(str_xml)
# 顶层标签
print(root.tag)
# 遍历root下的所有country节点
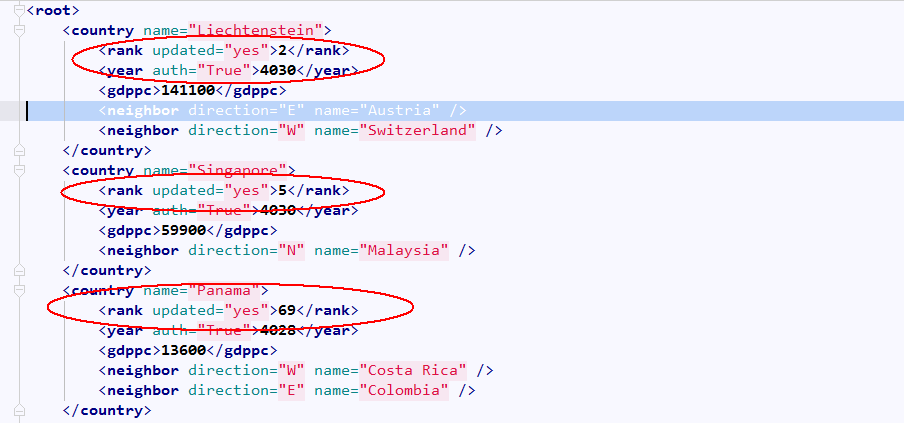
for country in root.findall('country'):
# 获取每一个country节点下rank节点的内容
print country
"""
结果:
<Element 'country' at 0x2efa828>
<Element 'country' at 0x2efa978>
<Element 'country' at 0x2efaa90>
"""
rank = country.find('rank').text
if int(rank)>50:
# 删除指定country节点
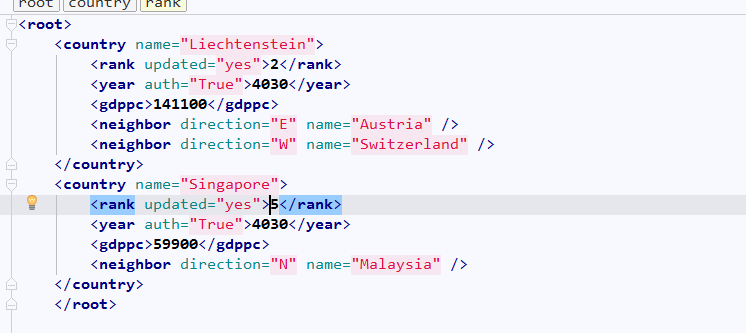
root.remove(country)
############ 保存文件 ############
tree = ET.ElementTree(root)
tree.write("a.xml")删除前
删除后
创建xml文件
方式一
#创建名叫data的根节点
root=ET.Element("data")
#创建第二层(即大儿子)
son1=root.makeelement('son1',{'name':'s1'})
son2=root.makeelement("son2",{'name':'s2'})
#在son1 中创建第三层
grandson1=son1.makeelement('grandson1',{'name':'gs1'})
grandson2=son2.makeelement('grandson2',{'name':'gs2'})
#添加节点
son1.append(grandson1)
son2.append(grandson2)
root.append(son1)
root.append(son2)
#创建xml文件
tree=ET.ElementTree(root)
tree.write('b.xml')b.xml

方式二:
####################方式二#############
root=ET.Element('root')
son1=ET.SubElement(root,'son1',attrib={'name':'s1'})
son2=ET.SubElement(root,'son2',attrib={'name':'s2'})
grandson1=ET.SubElement(son1,'grandson1',attrib={'name':'gs1'})
grandson1.text='haha'
grandson2=ET.SubElement(son2,'grandson2',attrib={'name':'gs2'})
grandson2.text='hehe'
et=ET.ElementTree(root) #生成文档对象
et.write('test.xml',xml_declaration=True)test.xml

我们可以看出以上创建的xml是没有进行缩进的,都在一行
这个时候我们需要一个函数来解决这个问题,先将xml节点转换成字符串,然后通过open()函数写入文件中
导入模块
from xml.dom import minidom
转换代码
def transfer(elem):
"将节点转换成字符串,并添加缩进"
rough_string=ET.tostring(elem,'utf-8')
reparsed=minidom.parseString(rough_string)
return reparsed.toprettyxml(indent='\t')代码实现
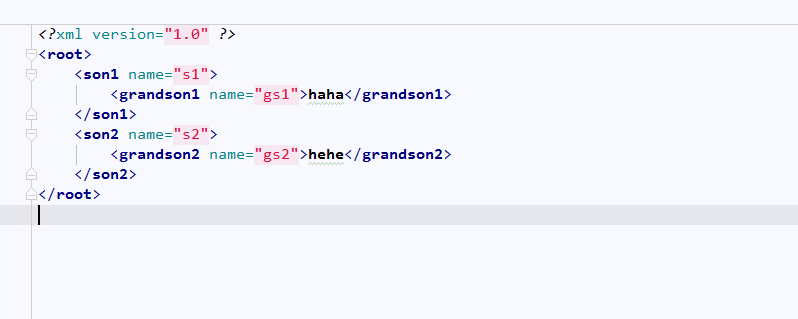
root=ET.Element('root')
son1=ET.SubElement(root,'son1',attrib={'name':'s1'})
son2=ET.SubElement(root,'son2',attrib={'name':'s2'})
grandson1=ET.SubElement(son1,'grandson1',attrib={'name':'gs1'})
grandson1.text='haha'
grandson2=ET.SubElement(son2,'grandson2',attrib={'name':'gs2'})
grandson2.text='hehe'
#转换
str_xml=transfer(root)
f=open("tab.xml",'w')
f.write(str_xml)
f.close()
tab.xml
requests模块
1.安装模块
pip install requests2.使用模块
GET请求
import requests
ret = requests.get('https://www.baidu.com')
print(ret.url) #https://www.baidu.com/
print(ret.text)
结果:
"""
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;cha......
"""
#有get参数
payload = {'wd': 'csdn'}
ret = requests.get("https://www.baidu.com/s", params=payload)
print(ret.url) #https://www.baidu.com/s?wd=csdn
print(ret.text)
"""
<html>
<head>
<script>.....
"""POST请求
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
ret = requests.post(url, data=payload)
print(ret.text)
# 2、发送请求头和数据实例
import requests
import json
#post参数
payload = {'some': 'data'}
#header头部
headers = {'content-type': 'application/json'}
#携带cookie进行post提交
ret = requests.post(url, data=json.dumps(payload),cookies=_cookies, headers=headers)
print(ret.text)
print(ret.cookies) #得到返回的cookie其他请求
requests.get(url, params=None, **kwargs)
requests.post(url, data=None, json=None, **kwargs)
requests.put(url, data=None, **kwargs)
requests.head(url, **kwargs)
requests.delete(url, **kwargs)
requests.patch(url, data=None, **kwargs)
requests.options(url, **kwargs)
subprocess模块
用于在进程中执行相关命令
call(args, stdin=None, stdout=None, stderr=None, shell=False),执行成功返回状态码0,否则返回1,并不会返回命令执行结果
import subprocess
>>> a=subprocess.call("ls -l")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python2.7/subprocess.py", line 522, in call
return Popen(*popenargs, **kwargs).wait()
File "/usr/lib/python2.7/subprocess.py", line 710, in __init__
errread, errwrite)
File "/usr/lib/python2.7/subprocess.py", line 1335, in _execute_child
raise child_exception
OSError: [Errno 2] No such file or directory
>>> a=subprocess.call(['ls','-l']) #执行成功
print a
"""
shell=True参数会让subprocess.call接受字符串类型的变量作为命令,并调用shell去执行这个字符串
"""
a=subprocess.call("ls -l",shell=True)
print a #0check_call(args, stdin=None, stdout=None, stderr=None, shell=False),执行成功返回状态码0,否则抛出异常
import subprocess
a=subprocess.call("ls -l",shell=True)
print a #0check_output(args, stdin=None, stdout=None, stderr=None, shell=False)
>>> a=subprocess.check_output("ls")
>>> a #返回命令的执行结果
'11.py\n1.pcap\nc.py\ndevelop\nhtml\nSQLiScanner\nsqlmap\nWebScarab.properties\nwww.tar\nx\n\xe5\x85\xac\xe5\x85\xb1\n\xe6\xa8\xa1\xe6\x9d\xbf\n\xe8\xa7\x86\xe9\xa2\x91\n\xe5\x9b\xbe\xe7\x89\x87\n\xe6\x96\x87\xe6\xa1\xa3\n\xe4\xb8\x8b\xe8\xbd\xbd\n\xe9\x9f\xb3\xe4\xb9\x90\n\xe6\xa1\x8c\xe9\x9d\xa2\n'
>>> Popen(args, bufsize=0, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=False, shell=False,cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0)
executable 参数指定一个要执行的替换程序。它很少需要用到。当shell=False时,executable 将替换args 指定的要执行的程序。但是,原始的args 仍然会传给该程序。大部分程序将args 当做命令的名字,它可以不同于真实执行的程序。在Unix上, args 名字变成utilities中可执行程序的显示名字,例如ps。如果shell=True,在Unix上executable 参数表示指定一个替换默认的/bin/sh的shell。
stdin、stdout 和stderr 分别指定要执行的程序的标准输入、标准输出和标准错误文件句柄。合法的值有PIPE、一个已经存在的文件描述符(一个正整数)、一个已经存在的文件对象和None。 PIPE表示应该为子进程创建一个新的管道。 如果为默认设置None,则不会发生重定向; 子进程的文件句柄将从父进程中继承。 另外,stderr 可以为STDOUT,它表示来自子进程中标准错误的数据应该被捕获到和标准输出相同的文件中。
preexec_fn 如果设定为一个可调用对象,该对象将在子进程中在子进程执行之前调用。(只在Unix上)
close_fds 如果为真,所有的描述符除了0、1 和2之外将在执行子进程之前关闭。(只在Unix上)。或者,在Windows上,close_fds 如果为真,那么子进程不会继承任何句柄。注意,在Windows上,你不可以设置close_fds 为真并同时通过设置stdin、stdout 或者stderr重定向标准句柄 。
cwd 如果不为None,那么子进程在当前目录在其执行之前将改变为cwd。 注意在搜索可执行程序时,该目录不会考虑在内,所以你不可以指定相对cwd 的程序路径。
env 如果不为None,它必须是一个定义了新进程环境变量的映射;这些环境变量将被使用而不是继承当前进程的环境这种默认的行为。
universal_newlines 如果为True,那么文件对象stdout 和stderr 作为文本文件以universal newlines 模式打开。每一行的终止符可能是Unix风格的'\n'、旧式Macintosh风格的'\r'或者Windows风格的'\r\n'。所有这些外部的表示在Python程序看来都是'\n'
#由于进程之间默认是无法进行通讯的,如果进程间要进行通信,需要通过管道进行连接,即subprocess.PIPE
>>> a=subprocess.Popen("ls",shell=True,stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
>>> a
<subprocess.Popen object at 0x7f4ad5a4ff90>
>>> a.stdout.read()
'11.py\n1.pcap\nc.py\ndevelop\nhtml\nSQLiScanner\nsqlmap\nWebScarab.properties\nwww.tar\nx\n\xe5\x85\xac\xe5\x85\xb1\n\xe6\xa8\xa1\xe6\x9d\xbf\n\xe8\xa7\x86\xe9\xa2\x91\n\xe5\x9b\xbe\xe7\x89\x87\n\xe6\x96\x87\xe6\xa1\xa3\n\xe4\xb8\x8b\xe8\xbd\xbd\n\xe9\x9f\xb3\xe4\xb9\x90\n\xe6\xa1\x8c\xe9\x9d\xa2\n'
>>> 通过这Popen()函数进行命令行交互
>>> import subprocess
>>> s=subprocess.Popen(['python'],shell=True,stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
>>> s.stdin.write('print("hello1")\n')
>>> s.stdin.write('print("hello2")\n')
>>> s.stdin.write('print("hello3")\n')
>>> a=s.communicate()
>>> a
('hello1\nhello2\nhello3\n', '')
>>>
>>> s=subprocess.Popen(['python'],shell=True,stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
>>> s.stdin.write('print("hello1")\n')>>> s.stdin.write('print("hello2")\n')
>>> s.stdin.close()
>>> cmd_out=s.stdout.read()
>>> s.stdout.close()
>>> print cmd_out
hello1
hello2
logging模块
日志级别
日志的级别默认为warning,所以如果不指定level,那么INFO与debug级别的信息就不会给予显示

最简单的用法
logging.warning("warning!!!!")
logging.debug("debug!!!")
logging.critical("critiacl!!!")
"""
#################Output###############
WARNING:root:warning!!!!
CRITICAL:root:critiacl!!!
"""
#由于默认显示级别为warning,因此无法显示debug的日志信息,要想解决这个问题我们需要改变默认的日志显示级别
#修改默认显示的级别
logging.basicConfig(level=logging.DEBUG)
logging.warning("warning!!!!")
logging.critical("critiacl!!!")
logging.debug("debug!!!!")
#################Output###############
WARNING:root:warning!!!!
CRITICAL:root:critiacl!!!
DEBUG:root:debug!!!日志输出到文件
logging.basicConfig(filename,filemode=’a’,format=None,datefmt=None,level=logging.warning,stream=None)
kwargs 支持如下几个关键字参数:
filename :日志文件的保存路径。如果配置了些参数,将自动创建一个FileHandler作为Handler;
filemode :日志文件的打开模式。 默认值为’a’,表示日志消息以追加的形式添加到日志文件中。如果设为’w’, 那么每次程序启动的时候都会创建一个新的日志文件;
format :设置日志输出格式;
datefmt :定义日期格式;
level :设置日志的级别.对低于该级别的日志消息将被忽略;
stream :设置特定的流用于初始化StreamHandler;
#首先设置日志输入到文件的格式
logging.basicConfig(filename='log',level=logging.DEBUG)
logging.warning("warning!!!!")
logging.critical("critiacl!!!")
logging.debug("debug!!!!")
日志文件
WARNING:root:warning!!!!
CRITICAL:root:critiacl!!!
DEBUG:root:debug!!!!发现没有时间,需要改进
logging.basicConfig(filename='log',level=logging.DEBUG,filemode='a',format="%(asctime)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
logging.warning("warning!!!!")
logging.critical("critiacl!!!")
logging.debug("debug!!!!")
日志文件
2016-10-06 10:13:45 warning!!!!
2016-10-06 10:13:45 critiacl!!!
2016-10-06 10:13:45 debug!!!!format的格式汇总
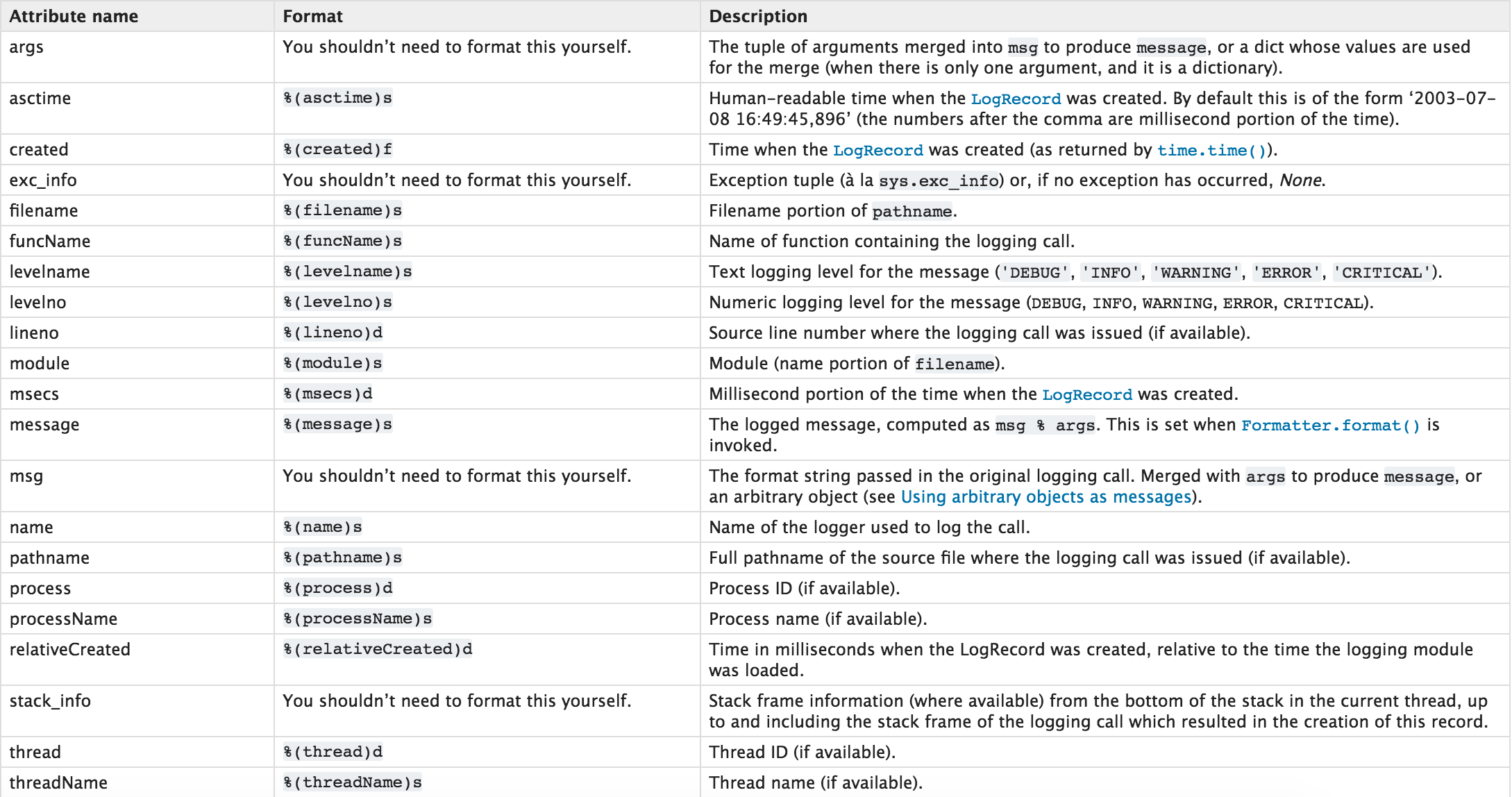
高级用法
如果我们想要将日志同时输出到屏幕和文件中或者将一个程序的日志输出到多个日志文件中,logging给我们提供了接口和处理器
#首先申明一个logger对象
logger=logging.getLogger("TEST-LOG") #这个TEST-LOG 可以根据实际情况改变
logger.setLevel(logging.DEBUG) #设置logger默认的的日志级别
#创建一个console 处理器,用来处理屏幕上的输出
ch=logging.StreamHandler()
ch.setLevel(logging.DEBUG)
#创建一个文件日志处理器
fh=logging.FileHandler('log')
fh.setLevel(logging.WARNING) #由于fh设置的日志级别为Warnning,所以会覆盖logger设置的级别,因此写入文件的级别为warning
#创建一个格式
formatter=logging.Formatter("%(asctime)s %(name)s %(levelname)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
#将创建的格式用到ch和fh上
ch.setFormatter(formatter)
fh.setFormatter(formatter)
#将ch和fh加入到logger中
logger.addHandler(ch)
logger.addHandler(fh)
#使用
logger.debug("debug message!!!")
logger.info("info message!!!")
logger.warning("warning message!!!")
logger.error("error message!!!")
logger.critical("critical message!!!")
屏幕
2016-10-06 10:23:06 TEST-LOG DEBUG debug message!!!
2016-10-06 10:23:06 TEST-LOG INFO info message!!!
2016-10-06 10:23:06 TEST-LOG WARNING warning message!!!
2016-10-06 10:23:06 TEST-LOG ERROR error message!!!
2016-10-06 10:23:06 TEST-LOG CRITICAL critical message!!!日志文件
2016-10-06 10:23:06 TEST-LOG WARNING warning message!!!
2016-10-06 10:23:06 TEST-LOG ERROR error message!!!
2016-10-06 10:23:06 TEST-LOG CRITICAL critical message!!!














 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









