







在学会了抓包,接口请求(如requests库)和Selenium的一些操作方法后,基本上就可以编写爬虫,爬取绝大多数网站的内容。
在爬虫领域,Selenium永远是最后一道防线。从本质上来说,访问网页实际上就是一个接口请求。请求url后,返回的是网页的源代码。
我们只需要解析html或者通过正则匹配提取出我们需要的数据即可。
有些网站我们可以使用requests.get(url),得到的响应文本中获取到所有的数据。而有些网页数据是通过JS动态加载到页面中的。使用requests获取不到或者只能获取到一部分数据。
此时我们就可以使用selenium打开页面来,使用driver.page_source来获取JS执行完后的完整源代码。
例如,我们要爬取,diro官网女包的名称,价格,url,图片等数据,可以使用requests先获取到网页源代码:
访问网页,打开开发者工具,我们可以看到所有的商品都在一个
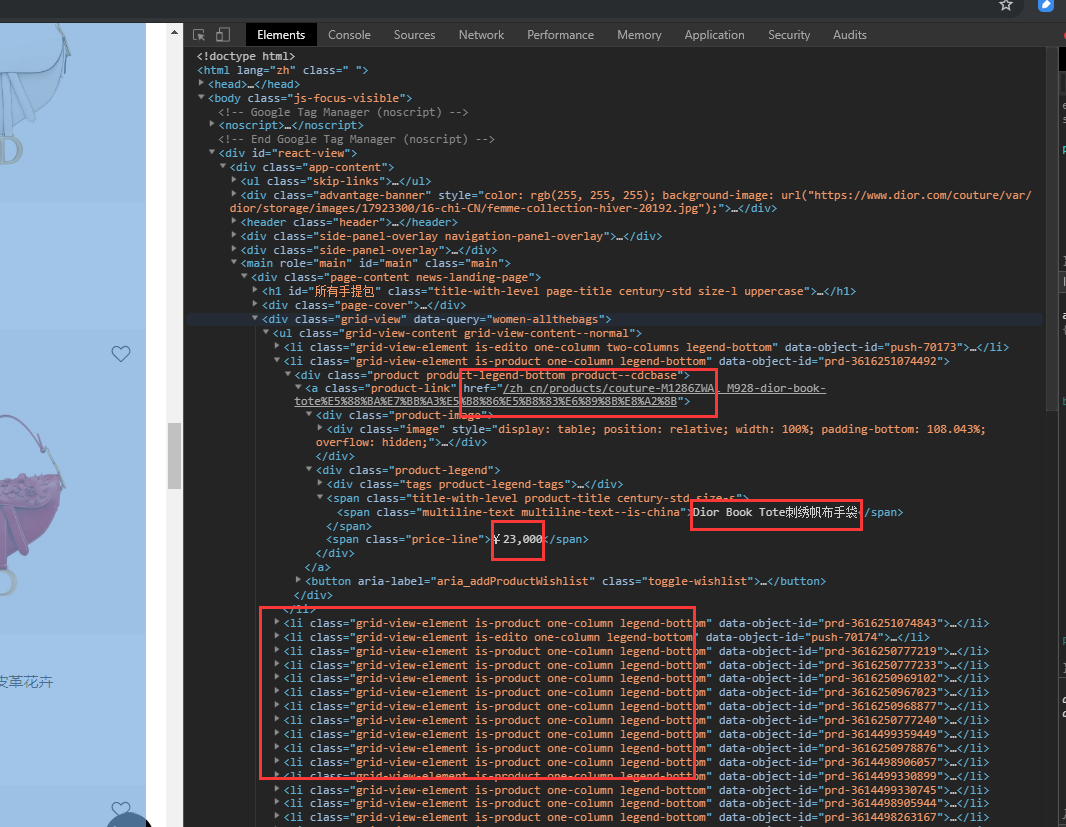
从html格式的源码中提取数据,有多种选择,可以使用xml.etree等等方式,bs4是一个比较方便易用的html解析库,配合lxml解析速度比较快。
bs4的使用方法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1068
1068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









