





总览
HTML几乎是直观的。 CSS是一项伟大的进步,可以将页面的结构与外观完全分开。 JavaScript增加了一些赞誉。 那是理论。 现实世界有些不同。
在本教程中,您将学习如何呈现在浏览器中看到的内容,以及如何在必要时进行抓取。 特别是,您将学习如何计算Disqus评论。 我们的工具将是Python和很棒的软件包,例如请求,BeautifulSoup和Selenium。
什么时候应该使用网页爬取?
Web抓取是一种自动获取旨在与人类用户进行交互的网页内容,对其进行解析并提取一些信息(可能导航到其他页面的链接)的实践。 如果没有其他方法可以提取必要的信息,则有时是必要的。 理想情况下,该应用程序提供专用API,以编程方式访问其数据。 网络抓取应是您的最后选择,原因有以下几种:
- 它非常脆弱(您要抓取的网页可能会经常更改)。
- 可能被禁止(某些Web应用程序具有禁止抓取的政策)。
- 它可能会很慢且很宽泛(如果您需要获取并消除大量的噪音)。
了解真实世界的网页
通过查看一些常见的Web应用程序代码的输出,让我们了解要面对的挑战。 在文章Vagrant简介中 ,页面底部有一些Disqus评论:
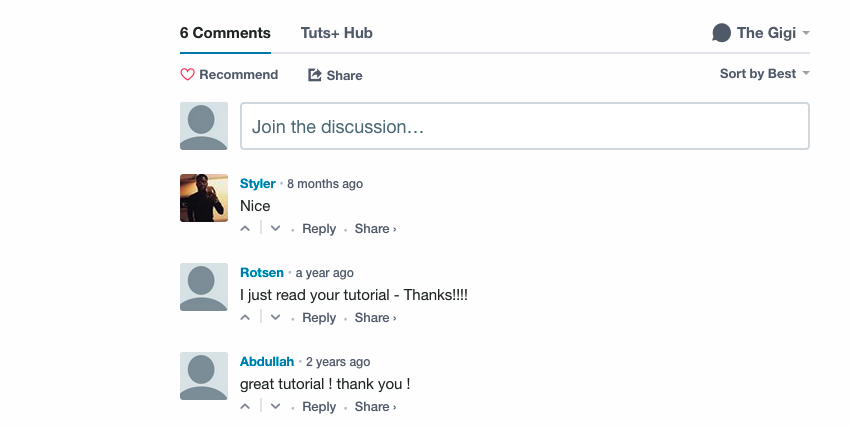
为了抓取这些评论,我们需要先在页面上找到它们。
查看页面源代码
自从1990年代初以来,每个浏览器都支持查看当前页面HTML的功能。 这是Vagrant简介的视图源中的摘录,该摘录以大量与文章本身无关的缩小和丑陋JavaScript开头。 这只是其中的一小部分:
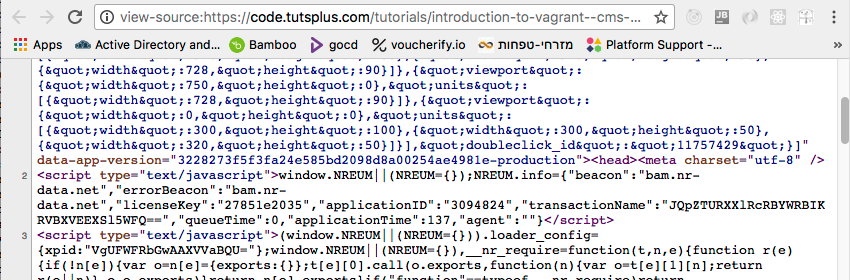
这是页面中的一些实际HTML:
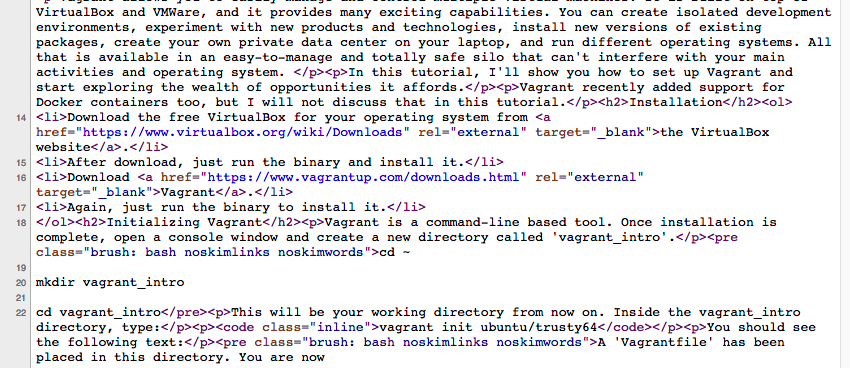
这看起来很混乱,但是令人惊讶的是,您在页面源中找不到“ Disqus”注释。
强大的嵌入式框架
事实证明,该页面是一个mashup,并且Disqus注释被嵌入为iframe(嵌入式框架)元素。 您可以通过右键单击注释区域来找到它,然后您将看到其中包含框架信息和来源:
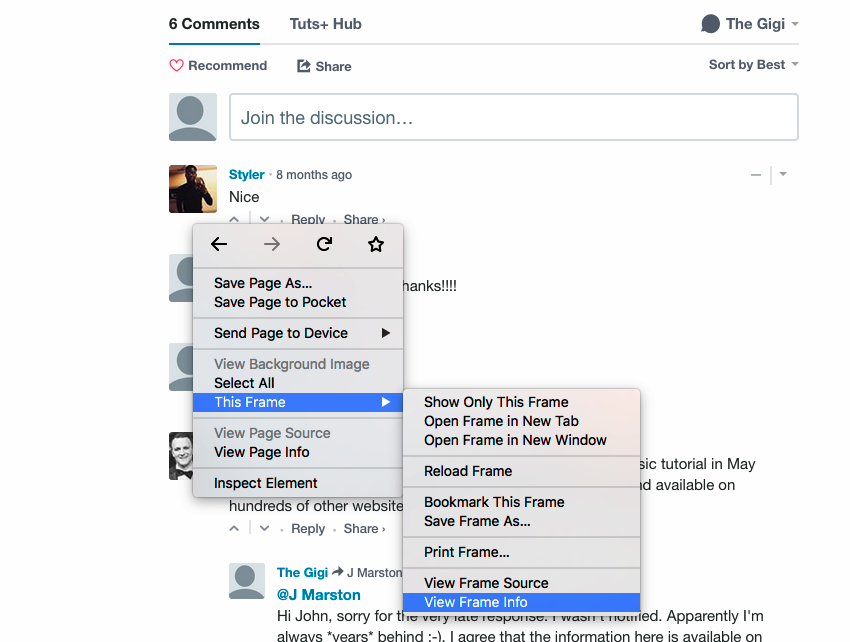
这就说得通了。 将第三方内容嵌入为iframe是使用iframe的主要原因之一。 让我们在主页源代码中找到<iframe>标记。 再次骗了! 主页源中没有<iframe>标签。
JavaScript生成的标记
省略的原因是view page source向您显示了从服务器获取的内容。 但是,由浏览器呈现的最终DOM(文档对象模型)可能非常不同。 JavaScript发挥作用,可以随意操作DOM。 无法找到iframe,因为从服务器检索页面时该iframe不存在。
静态抓取与动态抓取
静态抓取会忽略JavaScript。 它无需浏览器即可从服务器获取网页。 您将获得与在“查看页面源代码”中看到的完全一样的内容,然后将其切块并切成小方块。 如果您要查找的内容可用,则无需执行任何操作。 但是,如果内容类似于Disqus评论iframe之类的内容,则需要动态抓取。
动态抓取使用实际的浏览器(或无头浏览器),并让JavaScript完成其工作。 然后,它查询DOM以提取其要查找的内容。 有时您需要通过模拟用户来获取所需内容来使浏览器自动化。
带有请求和BeautifulSoup的静态报废
让我们看看如何使用两个很棒的Python软件包进行静态抓取:用于获取网页的请求和用于解析HTML页面的BeautifulSoup 。
安装请求和BeautifulSoup
首先安装pipenv ,然后再pipenv install requests beautifulsoup4 : pipenv install requests beautifulsoup4
这也将为您创建一个虚拟环境。 如果您使用的是gitlab中的代码,则只需pipenv install 。
提取页面
用请求来获取页面是一个衬里: r = requests.get(url)
响应对象具有很多属性。 最重要的是ok和content 。 如果请求失败,则r.ok将为False,而r.content将包含错误。 内容是字节流。 处理文本时,通常最好将其解码为utf-8:
>>> r = requests.get('http://www.c2.com/no-such-page')
>>> r.ok
False
>>> print(r.content.decode('utf-8'))
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>404 Not Found</title>
</head><body>
<h1>Not Found</h1>
<p>The requested URL /ggg was not found on this server.</p>
<hr>
<address>
Apache/2.0.52 (CentOS) Server at www.c2.com Port 80
</address>
</body></html> 如果一切正常,则r.content将包含请求的网页(与查看页面源相同)。
用BeautifulSoup查找元素
下面的get_page()函数通过URL获取网页,将其解码为UTF-8,然后使用HTML解析器将其解析为BeautifulSoup对象。
def get_page(url):
r = requests.get(url)
content = r.content.decode('utf-8')
return BeautifulSoup(content, 'html.parser')一旦有了BeautifulSoup对象,就可以开始从页面中提取信息。 BeautifulSoup提供了许多查找功能,可在页面内定位元素并向下钻取深层嵌套的元素。
Tuts +作者页面包含多个教程。 这是我的作者页面 。 每个页面上最多有12个教程。 如果您有12个以上的教程,则可以导航到下一页。 每个文章HTML都包含在<article>标记中。 以下函数查找页面上的所有文章元素,向下钻取它们的链接,并提取href属性以获取教程的URL:
def get_page_articles(page):
elements = page.findAll('article')
articles = [e.a.attrs['href'] for e in elements]
return articles以下代码从我的页面获取所有文章并打印(不带公共前缀):
page = get_page('https://tutsplus.com/authors/gigi-sayfan')
articles = get_page_articles(page)
prefix = 'https://code.tutsplus.com/tutorials'
for a in articles:
print(a[len(prefix):])
Output:
building-games-with-python-3-and-pygame-part-5--cms-30085
building-games-with-python-3-and-pygame-part-4--cms-30084
building-games-with-python-3-and-pygame-part-3--cms-30083
building-games-with-python-3-and-pygame-part-2--cms-30082
building-games-with-python-3-and-pygame-part-1--cms-30081
mastering-the-react-lifecycle-methods--cms-29849
testing-data-intensive-code-with-go-part-5--cms-29852
testing-data-intensive-code-with-go-part-4--cms-29851
testing-data-intensive-code-with-go-part-3--cms-29850
testing-data-intensive-code-with-go-part-2--cms-29848
testing-data-intensive-code-with-go-part-1--cms-29847
make-your-go-programs-lightning-fast-with-profiling--cms-29809Selenium的动态报废
静态抓取足以获取文章列表,但是正如我们之前所看到的,Disqus注释已被JavaScript嵌入为iframe元素。 为了收集评论,我们将需要使浏览器自动化并与DOM进行交互。 最好的工具之一是Selenium 。
Selenium主要面向Web应用程序的自动化测试,但它作为通用的浏览器自动化工具非常有用。
安装Selenium
键入以下命令以安装Selenium: pipenv install selenium
选择您的网络驱动程序
Selenium需要一个Web驱动程序(它可以自动运行的浏览器)。 对于Web抓取,选择哪个驱动程序通常无关紧要。 我更喜欢Chrome驱动程序。 请遵循本Selenium指南中的说明。
Chrome与PhantomJS
在某些情况下,您可能更喜欢使用无头浏览器,这意味着不会显示任何UI。 从理论上讲,PhantomJS只是另一个Web驱动程序。 但是,在实践中,人们报告了Selenium与Chrome或Firefox正常工作,而PhantomJS有时无法工作的不兼容问题。 我更喜欢从方程式中删除此变量,并使用实际的浏览器Web驱动程序。
计数Disqus评论
让我们进行一些动态抓取,并使用Selenium来计算Tuts +教程上的Disqus评论。 这是必要的进口。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.expected_conditions import (
presence_of_element_located)
from selenium.webdriver.support.wait import WebDriverWait get_comment_count()函数接受Selenium驱动程序和URL。 它使用驱动程序的get()方法来获取URL。 这类似于requests.get() ,但不同之处在于驱动程序对象管理DOM的实时表示。
然后,它获得了本教程的标题,并使用其父ID disqus_thread然后是iframe本身来定位Disqus iframe:
def get_comment_count(driver, url):
driver.get(url)
class_name = 'content-banner__title'
name = driver.find_element_by_class_name(class_name).text
e = driver.find_element_by_id('disqus_thread')
disqus_iframe = e.find_element_by_tag_name('iframe')
iframe_url = disqus_iframe.get_attribute('src') 下一步是获取iframe本身的内容。 请注意,我们等待comment-count元素出现,因为注释是动态加载的,并且不一定可用。
driver.get(iframe_url)
wait = WebDriverWait(driver, 5)
commentCountPresent = presence_of_element_located(
(By.CLASS_NAME, 'comment-count'))
wait.until(commentCountPresent)
comment_count_span = driver.find_element_by_class_name(
'comment-count')
comment_count = int(comment_count_span.text.split()[0])最后一部分是返回不是我发表的最后评论。 这样做的目的是发现我尚未回复的评论。
last_comment = {}
if comment_count > 0:
e = driver.find_elements_by_class_name('author')[-1]
last_author = e.find_element_by_tag_name('a')
last_author = e.get_attribute('data-username')
if last_author != 'the_gigi':
e = driver.find_elements_by_class_name('post-meta')
meta = e[-1].find_element_by_tag_name('a')
last_comment = dict(
author=last_author,
title=meta.get_attribute('title'),
when=meta.text)
return name, comment_count, last_comment结论
当可以通过不提供适当API的Web应用程序访问所需信息时,Web抓取是一种有用的做法。 从现代Web应用程序中提取数据需要花费一些不平凡的工作,但是成熟而精心设计的工具(例如请求,BeautifulSoup和Selenium)使其值得。
此外,不要犹豫,看看我们在Envato市场上有哪些可供出售和研究的物品 ,也不要犹豫,使用下面的提要来问任何问题并提供宝贵的反馈意见。
翻译自: https://code.tutsplus.com/tutorials/modern-web-scraping-with-beautifulsoup-and-selenium--cms-30486















 1463
1463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









