






之前介绍的StringIndexer是针对单个类别型特征进行转换,倘若所有特征都已经被组织在一个向量中
,又想对其中某些单个分量进行处理时,Spark ML提供了VectorIndexer类来解决向量数据集中的类别
性特征转换。通过为其提供maxCategories超参数,它可以自动识别哪些特征是类别型的,并且将原始
值转换为类别索引。它基于不同特征值的数量来识别哪些特征需要被类别化,那些取值可能性最多不超
过maxCategories的特征需要会被认为是类别型的。在下面的例子中,我们读入一个数据集,然后使用
VectorIndexer训练出模型,来决定哪些特征需要被作为类别特征,将类别特征转换为索引,这里设置
maxCategories为10,即只有种类小10的特征才被认为是类别型特征,否则被认为是连续型特征:
#导入相关的类库
from pyspark.ml.feature import VectorIndexer
from pyspark.sql import SparkSession
#创建SparkSession对象,配置spark
spark = SparkSession.builder.master('local').appName('VectorIndexerDemo').getOrCreate()
#读入数据集
data = spark.read.format('libsvm').load('file:///usr/local/spark/data/mllib/sample_libsvm_data.txt')
#创建VectorIndexer对象,
indexer = VectorIndexer(inputCol='features', outputCol='indexed',maxCategories=10)
#生成训练模型,训练数据
indexerModel = indexer.fit(data)
categoricalFeatures = indexerModel.categoryMaps
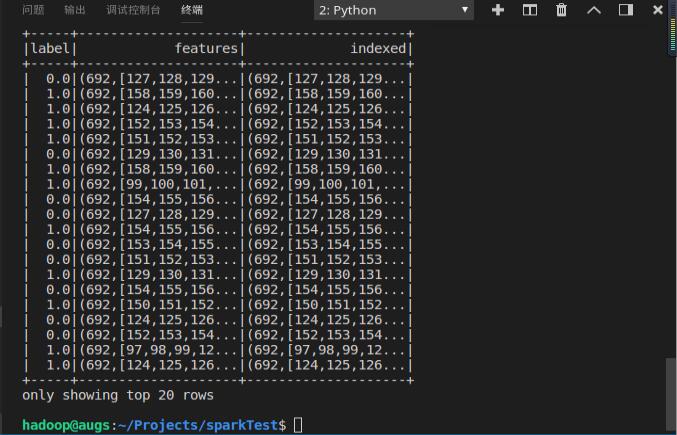
indexerData = indexerModel.transform(data)
indexerData.show()















 929
929











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









