









背景
在应用机器学习算法前,我们一般都要进行特征的处理,VectorIndexer就是一种特征处理方法之一,其主要目的是识别离散数值特征和离散数值特征,目的是为了后面的线性回归或者决策树等算法可以有一个更好的预测性能
原理
VectorIndexer的原理很简单,这个函数的入参有一个MaxCategory参数,也就是最大不同的值的个数,简单理解就是这一列的不同值的个数(类似sql的distinct)是否超过MaxCategory个,如果是那么就把这些不同的值设置成0-MaxCategory-1中的一个,如果这一列中不同的值的大于MaxCategory个,那么这一列保存不变
实现
from pyspark import SparkConf
from pyspark.sql import SparkSession
import traceback
from pyspark.sql.types import IntegerType
appname = "test" # 任务名称
master = "local" # 单机模式设置
'''
local: 所有计算都运行在一个线程当中,没有任何并行计算,通常我们在本机执行一些测试代码,或者练手,就用这种模式。
local[K]: 指定使用几个线程来运行计算,比如local[4]就是运行4个worker线程。通常我们的cpu有几个core,就指定几个线程,最大化利用cpu的计算能力
local[*]: 这种模式直接帮你按照cpu最多cores来设置线程数了。
'''
# spark_driver_host = "10.0.0.248"
try:
# conf = SparkConf().setAppName(appname).setMaster(master).set("spark.driver.host", spark_driver_host) # 集群
conf = SparkConf().setAppName(appname).setMaster(master) # 本地
spark = SparkSession.builder.config(conf=conf).getOrCreate()
from pyspark.ml.linalg import Vectors
df = spark.createDataFrame([(Vectors.dense([2, 7.0]),),
(Vectors.dense([7, 1.0]),),
(Vectors.dense([7, 2.0]),)], ["feature"])
from pyspark.ml.feature import VectorIndexer
indexer = VectorIndexer(maxCategories=2, inputCol="feature", outputCol="indexed")
model = indexer.fit(df)
model.transform(df).show()
spark.stop()
print('计算成功!')
except:
traceback.print_exc() # 返回出错信息
print('连接出错!')
结果显式:
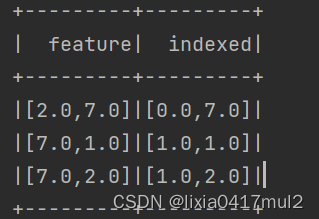
可以看到当设置最大MaxCategory=2时,第一列的值变成了[0,1],第二列的值保持不变
注意事项
需要注意到VectorIndexer的输入的Vector类型的向量,这个向量中的元素都是float浮点类型的数,里面的元素是不支持字符串类型,所以如果某个特征列一开始是字符串的列,那么首先需要使用StringIndexer等前置转换器把字符串的列转化成数值列,才能应用VectorIndexer进行随后的离散化数值操作















 2337
2337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









