






概念:
编码:在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,像a、b、c、d这样的52个字母(包括大写)、以及0、1等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套,这就是编码。
兼容:所谓兼容就是编码相同,如ISO-8859-1兼容ASCII ,表示ASCII中字符编码在ISO-8859-1编码是相同的,即如果ASCII编码的一个字符,用ISO-8859-1可以进行正确的解码。
一、ASCII
全称ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)。是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。占用一个Byte,用一个Byte(8 bit)的低7位表示,共128个。其中33为空制字符,95个为可打印字符。
在WEB应用中,URL就只支持ASCII字符集,但也不是支持ASCII中的全部字符集,RFC3986文档规定,Url中只允许包含英文字母(a-zA-Z)、数字(0-9)、-_.~4个特殊字符以及所有保留字符,对于ASCII中的33个控制字符也是不支持的,如果在 URL中传输中文及其它字符,必须进行转码。
二、ISO-8859-1
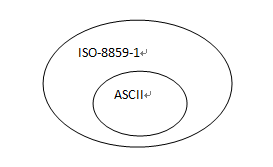
ISO-8859-1编码是单字节编码,向下兼容ASCII, 是ASCII的扩展,共256个。Latin1是ISO-8859-1的别名,有些环境下写作Latin-1。
ISO-8859-1与ASCII的兼容关系如下:
三、GB2312
GB2312码是中华人民共和国国家汉字信息交换用编码,全称《信息交换用汉字编码字符集--基本集》,由国家标准总局发布,1981年5月1日实施,通行于大陆。新加坡等地也使用此编码。
GB2312收录简化汉字及符号、字母、日文假名等共7445个图形字符,其中汉字占6763个。GB2312规定“对任意一个图形字符都采用两个字节表示.
GB2312与ASCII的关系:
其实在GB2312编码里,并不是所有的字符都会用两个字节来表示的,而GB2312编码,就是在ASCII编码的基础上进行扩充的,它规定了:ASCII的字符完整地包含在GB2312里,编码不变,仍然是以0开头,用一个字节来表示一个字符;对于ASCII没有的字符,就用1开头来区分,用两个字节合起来表示一个字符。
所以说GB2312兼容且包含了ASCII的所有字符。
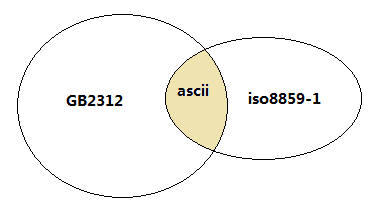
GB2312兼容且包含了ASCII所有编码及字符。
通过下面的代码也可以说明上面的问题:
public class Test { public static void main(String[] args) { String a="a"; try { byte[] b=a.getBytes("US-ASCII"); String c=new String(b,"GB2312"); System.out.println(c); byte[] d=a.getBytes("GB2312"); System.out.println(d.length); String f=new String(d,"US-ASCII"); System.out.println(f); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } } }
运行结果为 :
a
1
a
四、GBK
GBK全称《汉字内码扩展规范》(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称:Chinese Internal Code Specification),使用了双字节编码方案。 总共有23940个码位,他收录了21003个汉字,他的编码是和GB2312兼容的,也就是说用GB2312编码的汉字可以用GBK来解码,并且不会乱码。
GBK 向下与 GB 2312 编码兼容,向上支持 ISO 10646.1国际标准,是前者向后者过渡过程中的一个承上启下的产物。ISO 10646 是国际标准化组织 ISO 公布的一个编码标准,即 Universal Multilpe-Octet Coded Character Set(简称UCS),大陆译为《通用多八位编码字符集》,台湾译为《广用多八位元编码字元集》,它与 Unicode 组织的 Unicode 编码完全兼容。ISO 10646.1 是该标准的第一部分《体系结构与基本多文种平面》。我国 1993 年以 GB 13000.1 国家标准的形式予以认可(即 GB 13000.1 等同于 ISO 10646.1)。
GBK作为对GB2312的扩展,在现在的windows系统中仍然使用代码页CP936表示,但是同样的936的代码页跟一开始的936的代码页只支持GB2312编码不同,现在的936代码页支持GBK的编码。
在win7系统中查看系统默认的字符集,如下图:
GBK与GB2312、ASCII、BIG5(港台地区使用的繁体字字符集)的关系如下:
从字符包含角度分析如下:
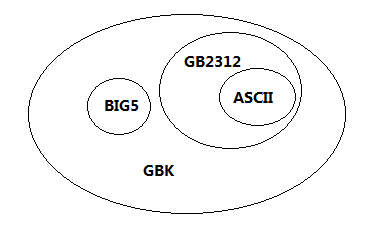
GBK包含了BIG5的所有繁体字
从编码兼容角度分析如下:
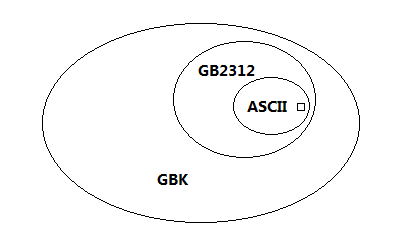
GBK与BIG5的编码相互之间并不兼容。
通过下面的代码也可以说明上面的问题:
public class Test { public static void main(String[] args) { String a = "中国國"; try { byte[] b = a.getBytes("GB2312"); String c = new String(b, "GBK"); System.out.println(c); byte[] d = a.getBytes("GBK"); String e = new String(d, "GB2312"); System.out.println(e); byte[] f= a.getBytes("BIG5"); String g = new String(f, "GBK"); System.out.println(g); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } } }
运行结果如下:
中国?
中国??
い?瓣
五、Unicode
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。
Unicode是为了解决传统的字符编码方案的局限而产生的,例如ISO 8859-1所定义的字符虽然在不同的国家中广泛地使用,可是在不同国家间却经常出现不兼容的情况。很多传统的编码方式都有一个共同的问题,即容许电脑处理双语环境(通常使用拉丁字母以及其本地语言),但却无法同时支持多语言环境(指可同时处理多种语言混合的情况)。
Unicode字符集涵盖了目前人类使用的所有字符,并为每个字符进行统一编号,分配唯一的字符码(Code Point)。Unicode字符集将所有字符按照使用上的频繁度划分为17个层面(Plane),每个层面上有216=65536个字符码空间。
在Unicode出现之前,所有的字符集都是和具体编码方案绑定在一起的,都是直接将字符和最终字节流绑定死了,例如ASCII编码系统规定使用7 比特来编码ASCII字符集;GB2312以及GBK字符集,限定了使用最多2个字节来编码所有字符,并且规定了字节序。这样的编码系统通常用简单的查 表,也就是通过代码页就可以直接将字符映射为存储设备上的字节流了。例如下面这个例子:

这种方式的缺点在于,字符和字节流之间耦合得太紧密了,从而限定了字符集的扩展能力。假设以后火星人入住地球了,要往现有字符集中加入火星文就变得很难甚至不可能了,而且很容易破坏现有的编码规则。
因此Unicode在设计上考虑到了这一点,将字符集和字符编码方案分离开。

也就是说,虽然每个字符在Unicode字符集中都能找到唯一确定的编号(字符码,又称Unicode码),但是决定最终字节流的却是具体的字符编码。例如同样是对Unicode字符“A”进行编码,UTF-8字符编码得到的字节流是0x41,而UTF-16(大端模式)得到的是0x00 0x41,但是他们通过一定的规则解码或转换后都能转换为该字符在unicode字符集中对应的字符的编码,即编码方式多种多样,但是最终都能映射到unicode字符集中对应的字符编码,达到了字符集和编码的分离。
在非Unicode环境下,由于不同国家和地区采用的字符集不一致,很可能出现无法正常显示所有字符的情况。微软公司使用了代码页(Codepage)转换表的技术来过渡性的部分解决这一问题,即通过指定的转换表将非Unicode的字符编码转换为同一字符对应的系统内部使用的Unicode编码。可以在“语言与区域设置”中选择一个代码页作为非Unicode编码所采用的默认编码方式,如936为简体中文GB码,950为繁体中文Big5(皆指PC上使用的)。在这种情况下,一些非英语的欧洲语言编写的软件和文档很可能出现乱码。而将代码页设置为相应语言中文处理又会出现问题,这一情况无法避免。只有完全采用统一编码才能彻底解决这些问题,但目前尚无法做到这一点。
六、UTF16
UTF-16是unicode具体编码实现的一种实现方式,UTF是"Unicode/UCS Transformation Format"的首字母缩写,即把Unicode字符转换为某种格式之意。采用1(16bit)个或者2(32bit)个16位长的码元(16bit位,理论上只能表示2^16=65536个字符,但是utf-16并不是只用16个bit位来表示,有些范围的字符将用32个bit位来表示,2^32足够表示unicode字符集了)来表示,因此这是一个变长表示,由于采用2个BYTE16个bit位,所以叫utf-16。
UTF-16比起UTF-8,好处在于大部分字符都以固定长度的字节(2字节)存储,但UTF-16却无法兼容于ASCII编码。如下面验证代码:
public class Test { public static void main(String[] args) { String a = "a"; try { byte[] b = a.getBytes("US-ASCII"); String c = new String(b, "UTF-16"); System.out.println(c); byte[] d = a.getBytes("UTF-16"); String e = new String(d, "US-ASCII"); System.out.println(e); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } } }
运行结果如下:
?
?? a
七、UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字的应用中,优先采用的编码
UTF-8采用了一种变长技术,每个编码区域有不同的字码长度,不同类型的字符可以有1到6个字节组成。
public class Test { public static void main(String[] args) { String a = "a"; try { byte[] b = a.getBytes("US-ASCII"); String c = new String(b, "UTF-8"); System.out.println(c); byte[] d = a.getBytes("UTF-8"); String e = new String(d, "US-ASCII"); System.out.println(e); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } } }
运行结果如下:
a
a
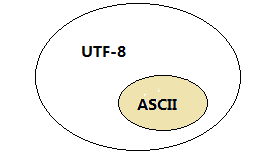
说明UTF-8在编码上是兼容ASCII的,不同于UTF-16不兼容ASCII,如下图
在微软公司Windows XP附带的记事本(Notepad)中,“另存为”对话框可以选择的四种编码方式除去非Unicode编码的ANSI(对于英文系统即ASCII编码,中文系统则为GB2312或Big5编码)外,其余三种为“Unicode”(对应UTF-16 LE)、“Unicode big endian”(对应UTF-16 BE)和“UTF-8”。
参考链接:
http://www.cnblogs.com/hua2015/p/4355431.html
https://zh.wikipedia.org/wiki/Unicode















 1604
1604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









