







上一节较为详细的讨论了 linux 中的系统调用,接下来几节将学习 linux 内核中的基本数据结构的设计和实现。本节先来看看 linux 内核中的链表。
链表和数组有些相似
链表是基于 C语言指针的,看了我《C语言入门》系列文章的朋友应该记得这张图:
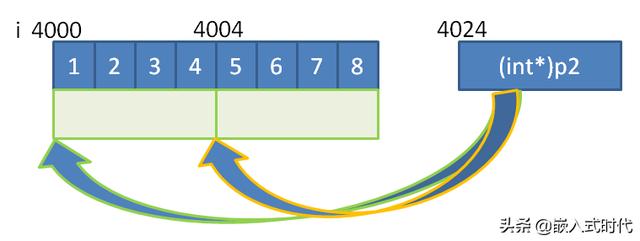
指针 p2 指向一块内存,可以通过 p2 修改该内存里保存的数值。链表其实也是类似的,只不过链表是一个挨一个“串起来”的:
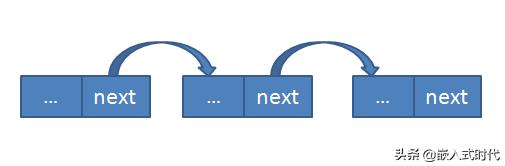
这种形式的数据结构和静态数组有些相似,不过链表包含的元素都是动态创建插入的,编译的时候并不需要知道要创建多少元素,而且链表的每个元素创建时间可能差异比较大,所以各个链表元素在内存中往往也不是连续的。
也正是因为链表的各个元素在内存中不像数组元素那样连续,所以链表才需要额外的“连接方式”将这些元素连接起来,指针正是一种非常合适的“连接方式”。
使用C语言定义链表
如果使用基本数据类型定义链表,例如:
int* a;int* b;int* c;a = b;b = c;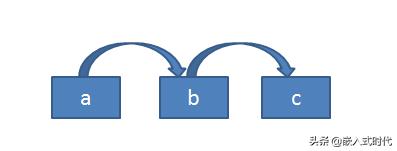
这样的确定义了一个链表,但是却没有任何意义,因为它真的只是一个链表,无法存储任何额外的信息。所以,链表一般都是用复合数据类型定义,常用的是结构体数据类型
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2185
2185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









