






针对3D open-vocabulary场景理解问题,腾讯优图实验室提出了一个新的统一模态的架构UniM-OV3D,将3D场景的四个模态数据point、image、text和depth map统一到了一个模型中。通过深入挖掘点云本身的特征,对各个模态做细粒度特征的表示,并进行四个模态的对齐,所提出的方法在包含室内、室外场景的四个数据集ScanNet, ScanNet200, S3IDS and nuScenes上均达到了SOTA的效果。
题目:UniM-OV3D: Uni-Modality Open-Vocabulary 3D Scene Understanding with Fine-Grained Feature Representation
论文:https://arxiv.org/abs/2401.11395
代码:https://github.com/hithqd/UniM-OV3D
背景
现有的方法在3D open-vocabulary场景理解问题上要么从2D图像中进行知识蒸馏,再映射到3D空间,要么只使用点云数据进行特征学习和表示。这种缺乏对其他更多模态的表示和对齐阻碍了他们有效处理细粒度点云对象实例的能力,如下图所示。考虑到3D场景的属性,深度信息是深度不变特征聚合的关键模态,但常常被忽视。尽管有一些方法进行了深度信息的探索,但是他们采用的是投影或者是渲染,而且仅仅是和一个模态进行对齐,这并不能充分发挥深度模态的作用。而考虑到点云信息本身的探索, 针对点云的caption learning是很多工作的方向所在,但是现有的工作都聚焦于以2D图像作为桥梁来生成3D点云的caption,这种及间接的caption生成方式并不是真正意义的点云caption learning,而且他们对于点云特征的提取也往往采用单一的冻结的3D提取器。
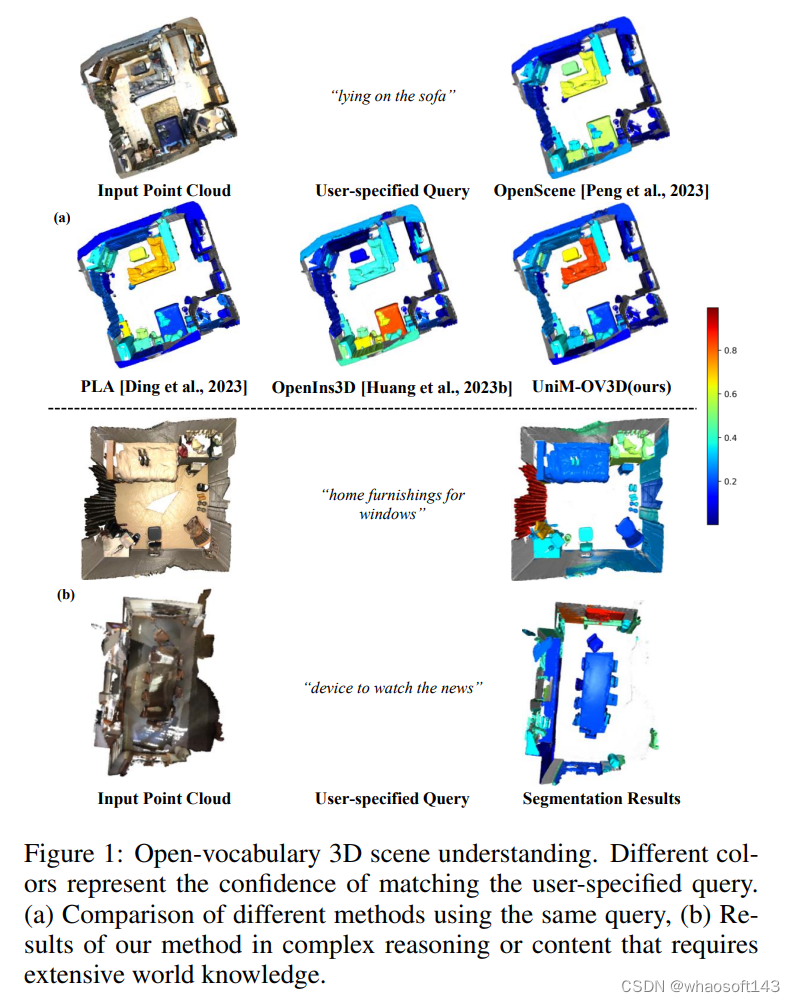
因此,为了充分利用各种模态的协同优势,本文提出了一个新的多模态对齐方法,将 3D 点云、image、depth map和text共同对齐到统一的特征空间中,以实现更精确的3D open vocabulary 场景理解 。
方法
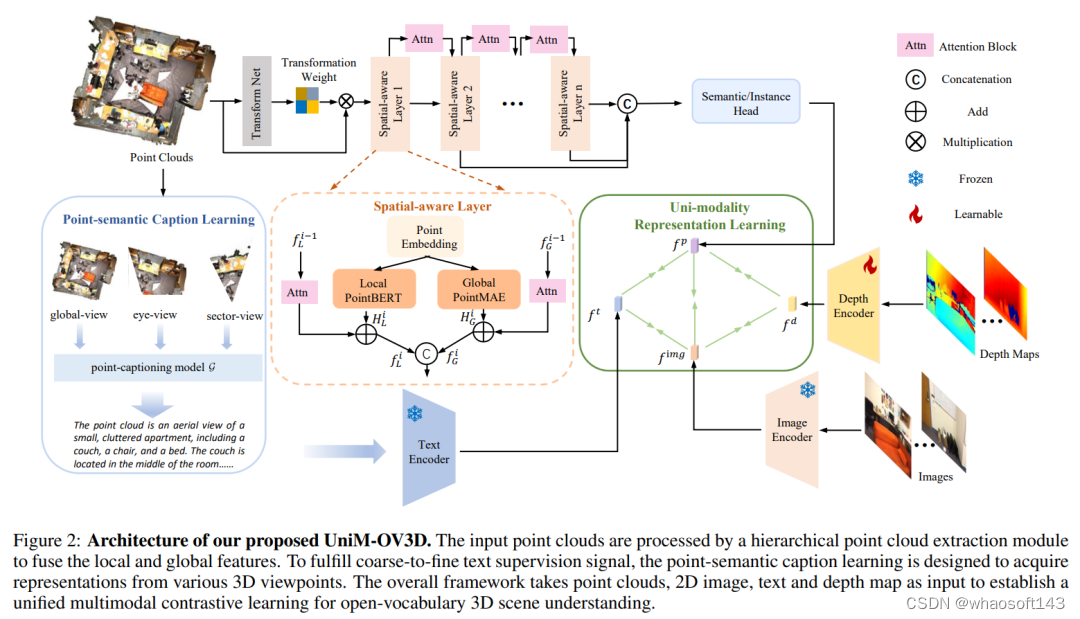
UniM-OV3D的整体架构如上图所示,点云数据由层次化点云特征提取模块处理以融合局部和全局特征。为了实现coarse-to-fine的文本监督信号,point-semantic caption learning被设计为从各种 3D 视角获取点云的文本表示。整体框架以点云、2D图像、文本和深度图作为输入,为3D open-vocabulary场景理解建立统一的多模态对比学习。
Hierarchical Feature Extractor
以稀疏点云作为输入,本文提出了一种可训练的层次化点云提取器来捕获细粒度的局部和全局特征,而不是仅仅利用冻结的 3D 提取器。输入被引导到transformer网络中,该网络采用基于注意力的层来回归 4×4 变换矩阵。该矩阵包含表示学习的仿射变换值的元素,这些元素用于对齐点云。对齐后,这些点被引入多个堆叠的空间感知层,这些层用于产生这些点的排列不变的特征。在这个结构中,使用PointBERT和PointMAE分别提取局部和全局的特征表示,并使用注意力模块充当两个相邻层之间的连接桥梁进行特征的传递。在通过基于注意力的层处理信息后,所有这些 N 维层的输出被连接起来。最后,可以添加分割头来输出点云的全局信息聚合,提供点云的全面表示。
Point-semantic Caption Learning
在生成点云的caption方面,本文首次尝试直接从点云生成相应的文本,而不是使用图像作为桥梁。我们构建了分层的点语义caption pairs,包括global、eye、sector三个层次的caption,它们可以提供细粒度的语言监督。
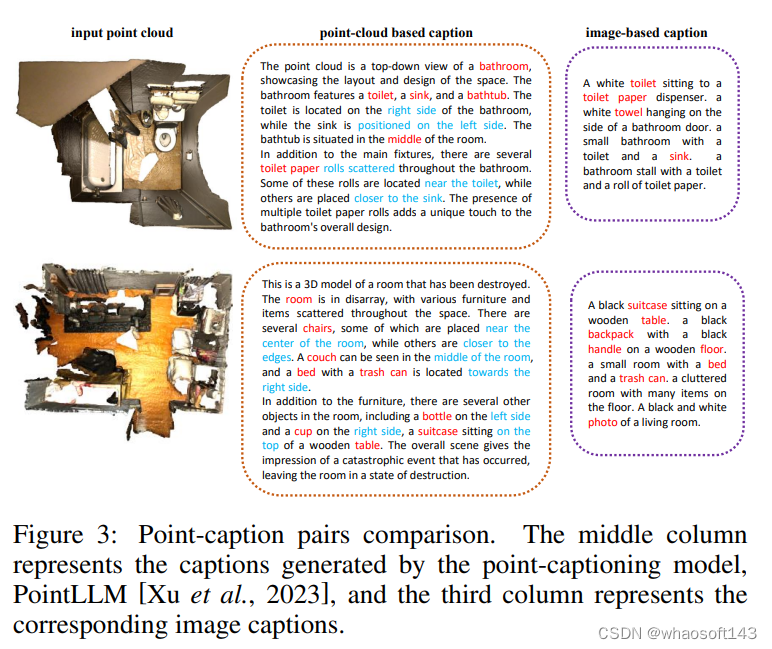
如上图所示,基于点云的不同层次生成的caption不仅提供了对场景的更精确和整体的描述,而且还更准确地表示了场景内目标的方向信息以及它们之间的相互关系。
统一模态的对齐
对于得到的四个模态细粒度的表示,本文采用点云和其他模态之间的对比学习损失:
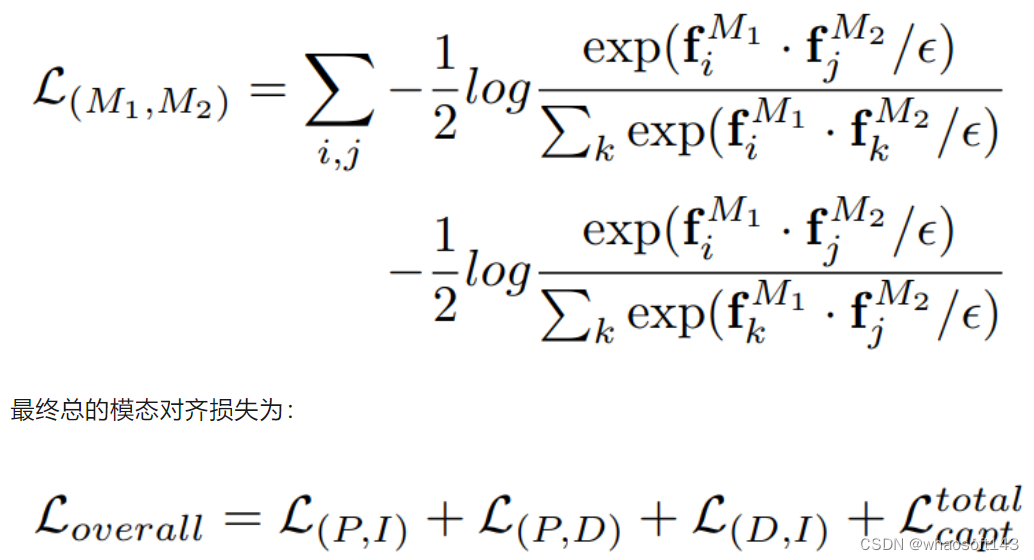
其中文本模态提供全面且可扩展的文本描述,而图像模态提供关于目标和上下文数据的准确指导。此外,深度和 3D 点云揭示了物体的重要结构细节。通过将这些模态统一在一个公共空间中,本文的方法可以最大限度地发挥它们之间的协同优势,从而获得突出的3D open-vocabulary场景理解性能。
实验结果
3D Semantic Segmentation
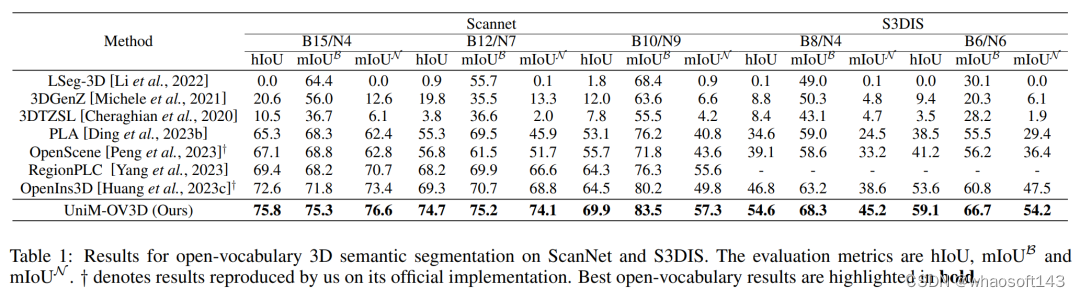
对于室内场景,在Scannet和S3DIS数据集上,本文的方法在不同的partition上对于hIoU指标的对比上比现有的sota方法分别高3.2%-5.4%,5.5%-7.8% 。
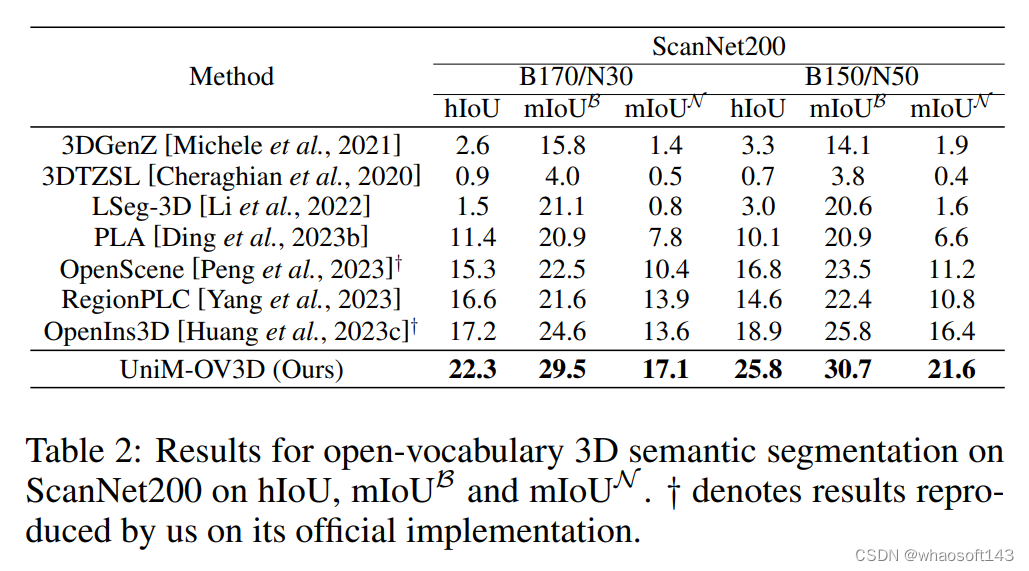
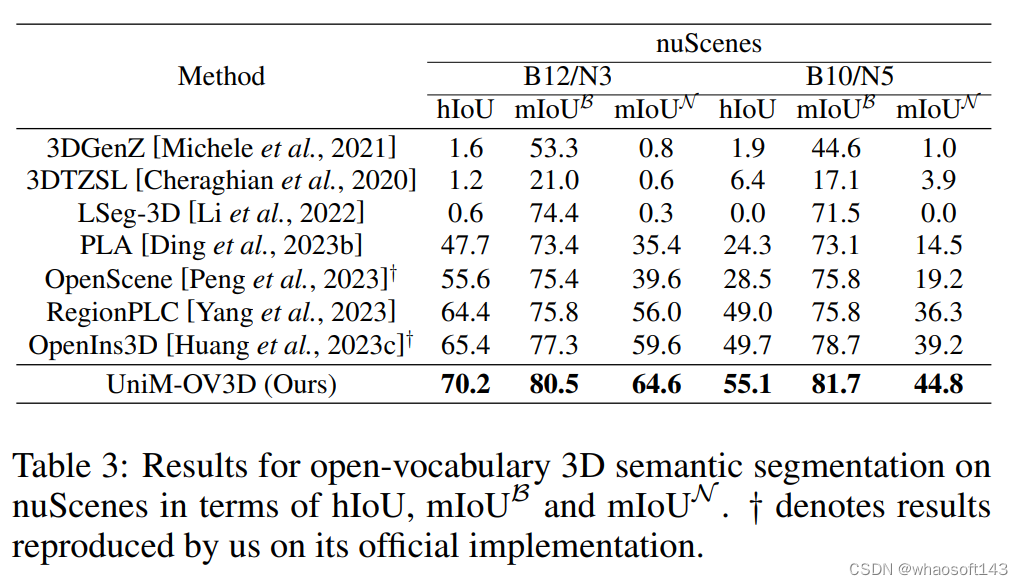
当面对ScanNet200中的长尾问题时,UniM-OV3D比现有最好的zero-shot方法在hIoU上高出5.1%-6.9% ,在mIoU上高出3.5%-5.2%。对于室外场景,UniM-OV3D在新类上比现有方法高4.8%-6.4% hIoU 和 5%-5.6% mIoU。
3D Instance Segmentation
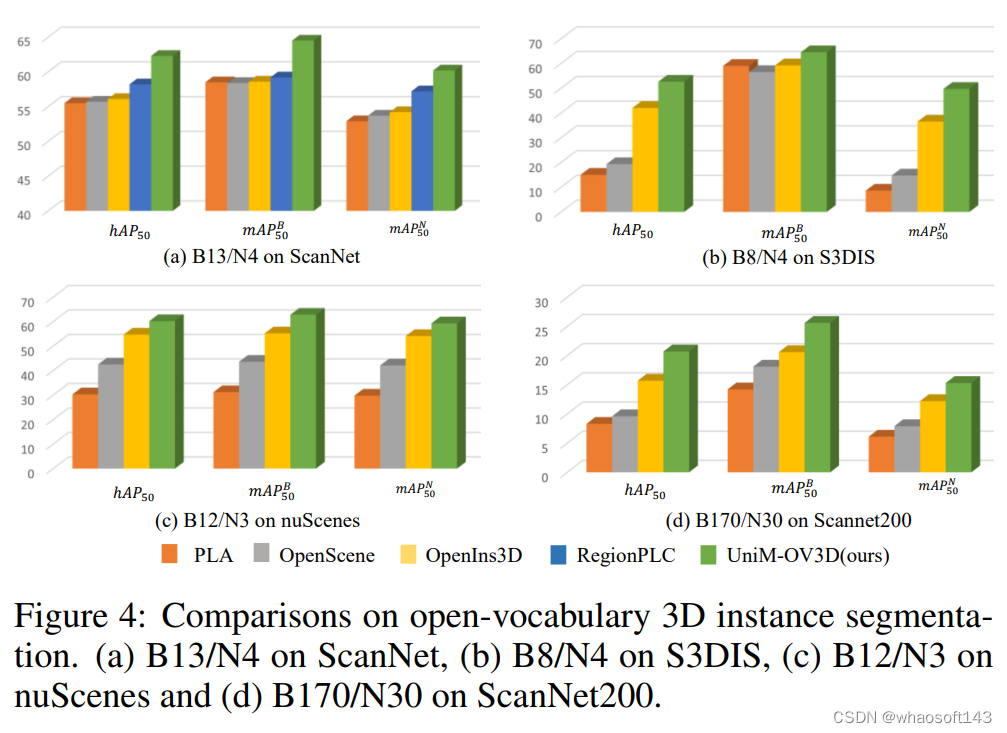
在实例分割任务中,UniM-OV3D 也hAP50、mAP 50指标上超过了现有的方法:5%-10.6% , 5%-5.3%、 3.1%-13.2% 。
总结
本文针对3D open-vocabulary场景理解问题提出了一个统一模态表示的新架构UniM-OV3D,做到了针对3D场景数据中point、image、text及depth map四个模态的融合。为了充分学习各个模态的细粒度特征表示,本文首先设计了层次化点云特征提取器,而对于点云的caption learning问题,本文首次构建了直接从点云生成相应的文本的caption learning机制。这种统一模态的架构可以充分利用各个模态的优势,这种设计也在室内室外的各个场景中证明了有效性。因此,UniM-OV3D为3D open-vocabulary场景理解提供了一个有效的解决方案。















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









