



 本文详细介绍了K-means聚类算法的基本原理,包括随机选择质心、计算样本距离并重新分配簇,以及如何衡量聚类效果的Inertia指标。通过Python的sklearn库实现了K-means建模和预测,并可视化了分类结果,是理解K-means算法的好材料。
本文详细介绍了K-means聚类算法的基本原理,包括随机选择质心、计算样本距离并重新分配簇,以及如何衡量聚类效果的Inertia指标。通过Python的sklearn库实现了K-means建模和预测,并可视化了分类结果,是理解K-means算法的好材料。

1. K-means 聚类算法的基本原理
Kmeans是无监督学习的代表,没有所谓的Y。主要目的是分类,分类的依据就是样本之间的距离。比如要分为K类。步骤是:
- 随机选取K个点。
- 计算每个点到K个质心的距离,分成K个簇。
- 计算K个簇样本的平均值作新的质心
- 循环2、3
- 位置不变,距离完成
2. 关于聚类的距离
Kmeans的基本原理是计算距离。一般有三种距离可选:
曼哈度距离:

欧式距离:

余弦距离:
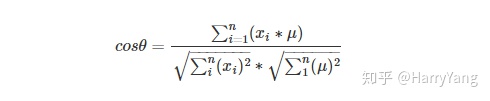
3. Inertia的概念
每个簇内到其质心的距离相加,叫inertia。各个簇的inertia相加的和越小,即簇内越相似。(但是k越大inertia越小,追求k越大对应用无益处)
4. 在sklearn中用实现代码
导入模拟数据,并绘图查看其分布
#导入数据
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X, y = make_blobs(n_samples=500, # 500个样本
n_features=2, # 每个样本2个特征
centers=4, # 4个中心
random_state=1 #控制随机性
)
#画出对应的图像位置
color = ['red', 'pink','orange','gray']
fig, axi1=plt.subplots(1)
for i in range(4):
axi1.scatter(X[y==i, 0], X[y==i,1],
marker='o',
s=8,
c=color[i]
)
plt.show()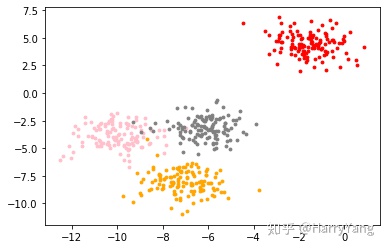
使用Sklearn中的K-means进行建模:
from sklearn.cluster import KMeans
n_clusters=4 #划分类别的数量
cluster = KMeans(n_clusters=n_clusters,random_state=0).fit(X)利用训练的模型进行预测:
y_pred=cluster.predict(X)
y_pred.shape#数字比较多,只查看其形状
(500,)查看质心及Inertia
centroid=cluster.cluster_centers_
centroid # 查看质心
array([[ -6.08459039, -3.17305983],
[ -1.54234022, 4.43517599],
[ -7.09306648, -8.10994454],
[-10.00969056, -3.84944007]])
inertia=cluster.inertia_
inertia
908.38556847606135. 通过绘图查看分类后的分布
color=['red','pink','orange','gray']
fig, axi1=plt.subplots(1)
for i in range(n_clusters):
axi1.scatter(X[y_pred==i, 0], X[y_pred==i, 1],
marker='o',
s=8,
c=color[i])
axi1.scatter(centroid[:,0],centroid[:,1],marker='x',s=100,c='black')
<matplotlib.collections.PathCollection at 0x8a50510>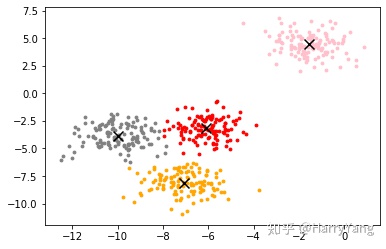
6. 总结
以上是本周对KMeans聚类算法的原来的初步讲解,并对通过代码来实现。


















 3109
3109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









