






Spark和Mysql(JdbcRDD)整合开发
Spark的功能非常强大,我们讨论了《Spark和Hbase整合》、《Spark和Flume-ng整合》以及《Hive的整合》。我们今天的主题是聊聊Spark与Mysql的组合开发。

图1
在Spark中提供了一个JdbcRDD类,该RDD就是读取JDBC中的数据并转换成RDD,之后我们就可以对该RDD进行各种的操作。我们先看看该类的构造函数,如图2所示:
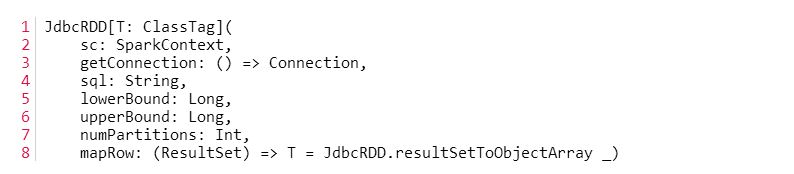 图2
图2
这个类带了很多参数,关于这个函数的各个参数的含义,我觉得直接看英文就可以很好的理解,如下面所示:
 图3
图3
我来翻译一下。1、getConnection 返回一个已经打开的结构化数据库连接,JdbcRDD会自动维护关闭。
2、sql 是查询语句,此查询语句必须包含两处占位符?来作为分割数据库ResulSet的参数,比如:"select title, author from books where ? < = id and id <= ?"
3、lowerBound, upperBound, numPartitions 分别为第一、第二占位符,partition的个数。比如,给出lowebound 1,upperbound 20, numpartitions 2,则查询分别为(1, 10)与(11, 20)
4、mapRow 为转换函数,将返回的ResultSet转成RDD需用的单行数据,在此处可以选择Array或其他,也可以是自定义的case class。默认的是将ResultSet 转换成一个Object数组。
下面我们说明如何使用该类,请参考下图的代码。
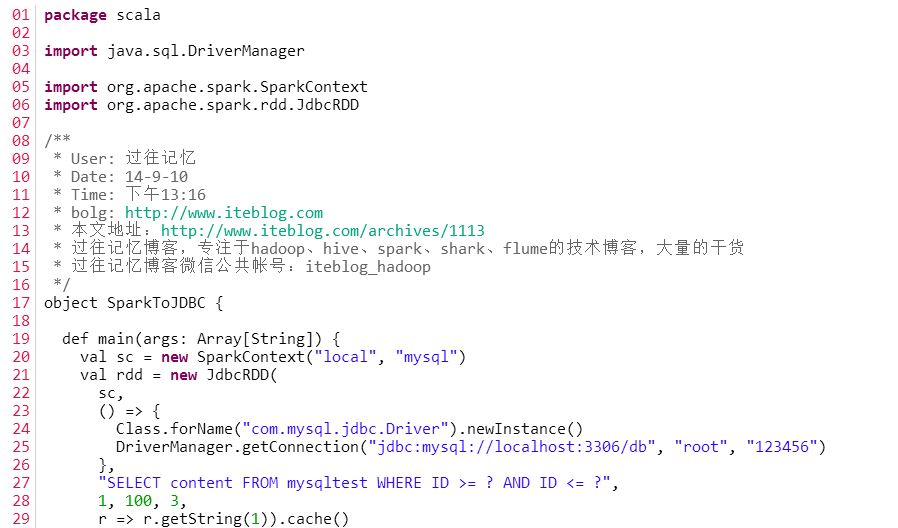

代码比较简短,主要是读mysqltest 表中的数据,并统计ID>=1 && ID < = 100 && content.contains("success")的记录条数。我们从代码中可以看出JdbcRDD的sql参数要带有两个?的占位符,而这两个占位符是给参数lowerBound与参数upperBound定义where语句的上下边界的。从JdbcRDD类的构造函数我们可以知道,参数lowerBound与参数upperBound都只能是Long类型的,并不支持其他类型的比较,这个使得JdbcRDD使用场景比较有限。而且在使用过程中sql参数必须有类似 ID >= ? AND ID < = ?这样的where语句,若你写成下面所示的形式:
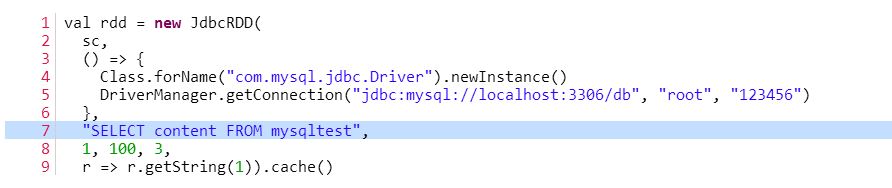 图4
图4
那在运行的时候会出现以下的错误:
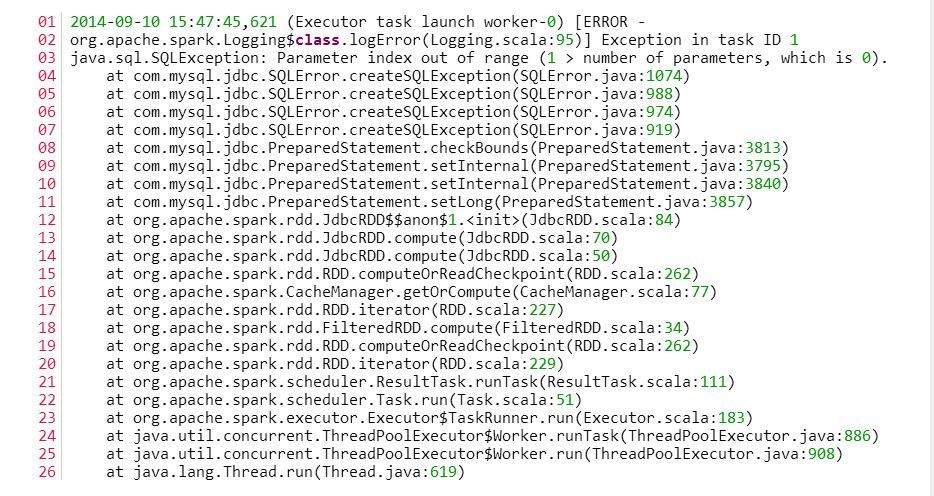 图5
图5
看下面JdbcRDD类的compute函数的实现就可以知道了:
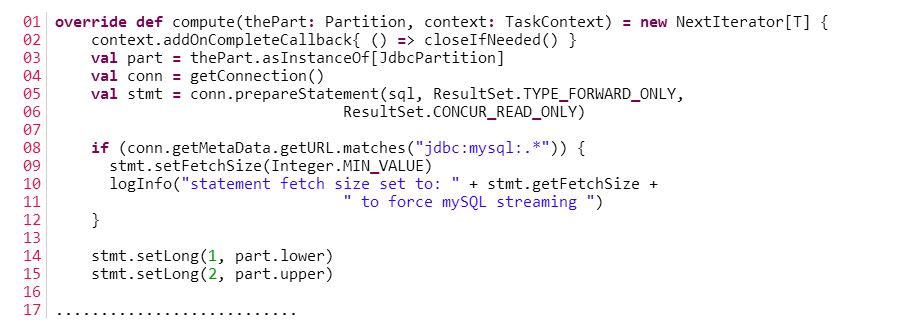 图6
图6
不过令人高兴的是,我们可以自定义一个JdbcRDD,修改上面的计算思路,这样就可以得到符合我们自己要求的JdbcRDD。
注: 在写本文的时候,本来我想提供一个JAVA例子,但是JdbcRDD类的最后一个参数很不好传,网上有个哥们是这么说的:
I don't think there is a completely Java-friendly version of this class. However you should be able to get away with passing something generic like "ClassTag.MODULE.apply(Object.class)" There's probably something even simpler.
下面的英文是我发邮件到Spark开发组询问如何在Java中使用JdbcRDD,Spark开发组的开发人员给我的回复信息如下:

所以我也只能放弃。若你知道怎么用Java实现,欢迎留言。















 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









