






1.Concept
拉依达准侧(Pau’ta Criteron)是先假设一组数据中只含有随机误差,首先按照一定准侧计算标准偏差,按照一定概率确定一定区间,认为不在这个区间的为异常值。
使用数据类型:数据呈正太分布或者近似正太分布。
2.举例实验
该实验中使用正太分布函数确定区间,认为剩余误差超过3 σ
\sigmaσ为异常值。
python 代码实验:
# encoding:utf-8
'''
@Author:noodles
2020-7-25 17:00:48
'''
import math
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
def pdf(x, mu, sigma):
y = (1.0 / math.sqrt(2 * math.pi * sigma)) * np.exp(-(x - mu) ** 2 / (2 * sigma ** 2))
return y
if __name__ == '__main__':
# generate random num tested
src_data = np.random.randn(100)
src_data[99] = 5 # add one outliers
x = np.sort(src_data)
# step1: get mean
mu = x.mean()
# step2: get standard deviation
sigma = x.std()
# plot histgram of its distribution
y = pdf(x, mu, sigma)
# step3: residual error
RE = abs(x - mu)
# step4: remove outliers
good_x = []
outliers = []
for i, j in zip(RE, x):
if i < 3 * sigma:
good_x.append(j)
else:
outliers.append(j)
good_x = np.array(good_x)
good_mu = good_x.mean()
good_sigma = good_x.std()
good_y = pdf(good_x, good_mu, good_sigma)
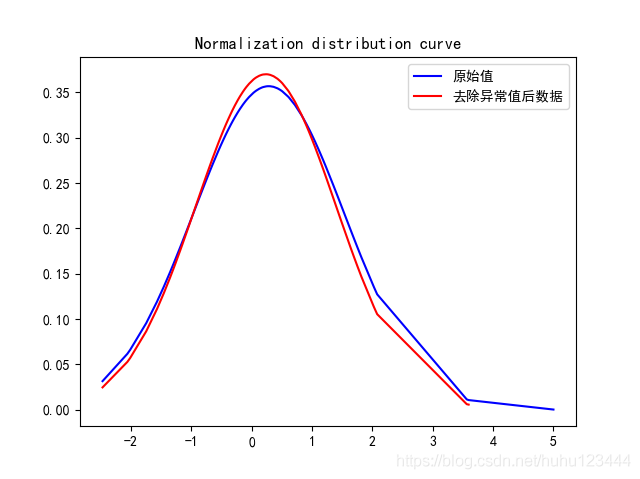
plt.plot(x, y, c='b', label=u'原始值')
plt.plot(good_x, good_y, c='r', label=u'去除异常值后数据')
plt.title('Normalization distribution curve')
plt.legend()
plt.show()
print('the outliers removed:',outliers)
实验结果:

3.Couclusion
使用Pauta准侧第一步你要能够确定你的数据符合正太分布,或者能够转化为正太分布,其次根据自己的需要合理选择不同的概率分布函数。
4.Reference
https://baike.baidu.com/item/%E6%8B%89%E4%BE%9D%E8%BE%BE%E5%87%86%E5%88%99/5678473?fr=aladdin
原文链接:https://blog.csdn.net/huhu123444/article/details/107581218
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









