






通过搭建和运行example,我们初步认识了spark。
大概是这么一个流程
------------------------------ ---------------------- ----------------------
| Application(spark shell) | <=> | Spark Master | <=> | Spark Slavers |
------------------------------ ---------------------- ----------------------
application 发送任务到master,master 接受任务,把上下文分解成一堆task list,把task下发给 Slavers去完成,
slavers完成之后,把结果上报给master,master汇总所有slavers的执行结果,返回给Application。
这里Application,可以是我们自己编写的进程(里面包含要进行分布式计算的数据位置,数据挖掘的算法等)。
但是我们可以看到官方的框架跟我们运行的几个进程好像对不上。
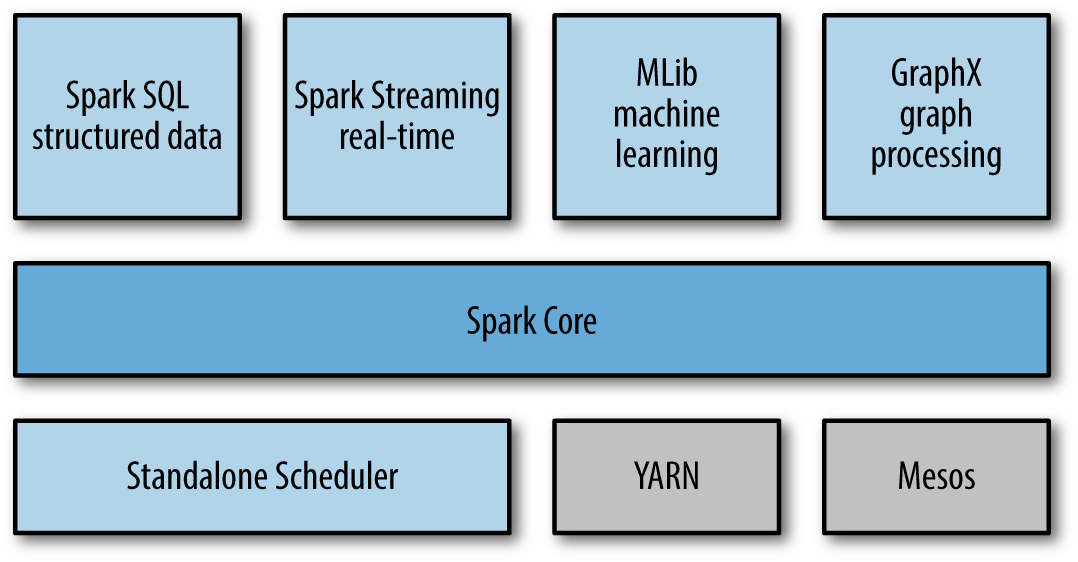
从图里面看到,spark跟mahout一样,更像是一个框架,提供核心功能,然后在核心基础上,又提供很多插件或者说库。
我们之前运行的standalone模式,由Standalone Scheduler来进行集群管理的,这个spark自带的, 看到它使跟Mesos,YARN放在一个层面的,YARN和Mesos怎么管理集群,不清楚,
但清楚的是,spark和它们兼容,可以运行在其之上。
Cluster Managers Under the hood, Spark is designed to efficiently scale up from one to many thousands of compute nodes. To achieve this while maximizing flexibility, Spark can run over a variety of cluster managers, including Hadoop YARN, Apache Mesos, and a simple cluster manager included in Spark itself called the Standalone Scheduler. If you are just installing Spark on an empty set of machines, the Standalone Scheduler provides an easy way to get started; if you already have a Hadoop YARN or Mesos cluster, however, Spark’s support for these cluster managers allows your applications to also run on them. Chapter 7 explores the different options and how to choose the correct cluster manager.
Spark SQL、Spark Streaming、MLlib等,是在spark core基础上的插件,方便开发者使用sql、支持stream流式数据(疑问:这个跟storm处理是否一样?),机器学习等。
这里最关键的就是spark core了,实现了基本的函数、任务调度、内存管理、容灾等。其中RDDS提供大部分API来跟spark master和其他插件进行交互。
Spark Core Spark Core contains the basic functionality of Spark, including components for task scheduling, memory management, fault recovery, interacting with storage systems, and more. Spark Core is also home to the API that defines resilient distributed datasets (RDDs), which are Spark’s main programming abstraction. RDDs represent a collection of items distributed across many compute nodes that can be manipulated in parallel. Spark Core provides many APIs for building and manipulating these collections.
回过头来,看看我们启动的几个进程:
//spark shell root 3074 0.2 6.2 5099472 519196 s000 S+ 5:29下午 0:21.81 /usr/bin/java -cp :/private/var/spark/conf:/private/var/spark/lib/spark-assembly-1.3.0-hadoop2.4.0.jar:/private/var/spark/lib/datanucleus-api-jdo-3.2.6.jar:/private/var/spark/lib/datanucleus-core-3.2.10.jar:/private/var/spark/lib/datanucleus-rdbms-3.2.9.jar -Dscala.usejavacp=true -Xms1g -Xmx1g org.apache.spark.deploy.SparkSubmit
--class org.apache.spark.repl.Main spark-shell
//spark master and worker root 6368 0.8 12.7 1378592 260736 pts/11 Sl 13:53 1:44 java -cp :/var/spark/sbin/../conf:/var/spark/lib/spark-assembly-1.3.0-hadoop2.4.0.jar -XX:MaxPermSize=128m -Dspark.akka.logLifecycleEvents=true -Xms512m -Xmx512m
org.apache.spark.deploy.master.Master --ip qp-zhang --port 7077 --webui-port 8080 root 9327 0.9 11.3 1370228 232076 ? Sl 15:35 1:07 java -cp :/var/spark/sbin/../conf:/var/spark/lib/spark-assembly-1.3.0-hadoop2.4.0.jar -XX:MaxPermSize=128m -Dspark.akka.logLifecycleEvents=true -Xms512m -Xmx512m
org.apache.spark.deploy.worker.Worker spark://qp-zhang:7077
是由不同的class基于spark core 和其他组件实现的。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









