





一个新颖的半监督LiDAR点云分割框架,有效地利用了LiDAR传感器和自动驾驶场景中的结构先验(spatial prior)对分割模型进行一致性约束,在主流的自动驾驶数据集(nuScenes ,SemanticKITTI ,ScribbleKITTI )上实现了优异的分割性能。
论文:https://arxiv.org/abs/2207.00026
主页:https://ldkong.com/LaserMix
代码:https://github.com/ldkong1205/LaserMix
得益于实时、精细且结构化的感知能力,激光雷达(LiDAR)近乎成为了自动驾驶感知模块的标配。随着学术机构和自动驾驶大厂不断推出大规模的LiDAR数据集(如KITTI , nuScenes , Waymo Open 等),利用深度学习技术对由LiDAR收集得到的点云进行感知(如分割、检测、跟踪等)已经成为当下研究的热点之一。然而,从真实世界中收集得到的数据往往具有极高的复杂度和多样性;同一个街道的路况在一天中的不同时刻尚且复杂多变,更不用说不同街道甚至不同城市的街道间呈现出的变化。因此,收集并标注一个能涵盖各种情境的真实世界数据集是极其困难的。

雨天条件下的城市道路情况

和常见的图像或语音数据类似,LiDAR点云的收集(相对于标注)是较为方便的。对于一个基于学习的问题而言,昂贵的数据标注往往是制约模型泛化能力的关键因素。这样一个问题在LiDAR点云上尤为突出:一个由64线LiDAR传感器收集得到的场景点云往往包含超过10万个点 ,而给收集到的每个点云都打上语义标签(semantic label)所需要的人力和经济成本是及其巨大的。
在上述前提条件的驱动下,这个工作开始探究基于半监督学习(semi-supervised learning)的LiDAR点云感知,即:在充分利用到现有的已标注数据的基础上,结合便于收集的大量无标注数据,训练泛化能力优异的模型。经典的半监督学习框架(如Mean Teacher ,MixMatch ,CPS 等)主要为图像识别等任务所设计;它们在LiDAR点云分割任务下没有展现出具有竞争力的性能。
由于LiDAR点云是从真实世界中收集而来的,其自然而然地包含了真实场景下的结构先验(spatial prior)。举例来说,一个复杂的自动驾驶场景往往包括丰富的静态(static)类别(如road,sidewalk,building,vegetation等)和动态(dynamic)类别(如car,pedestrian,cyclist等)。前者往往是构成一个场景点云的主要部分,而后者由于较小的体积(如pedestrian类,每个样例仅包含少量的点)和较低的出现频率(如motorcyclist类,仅在少量场景中出现)等因素,仅占场景中的一小部分(如下图所示)。
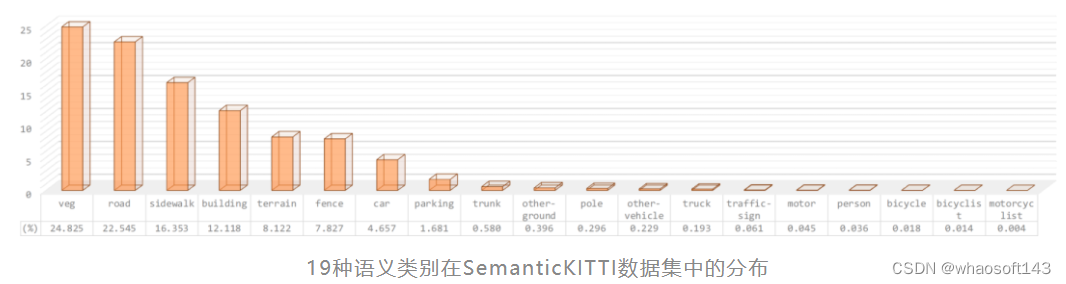
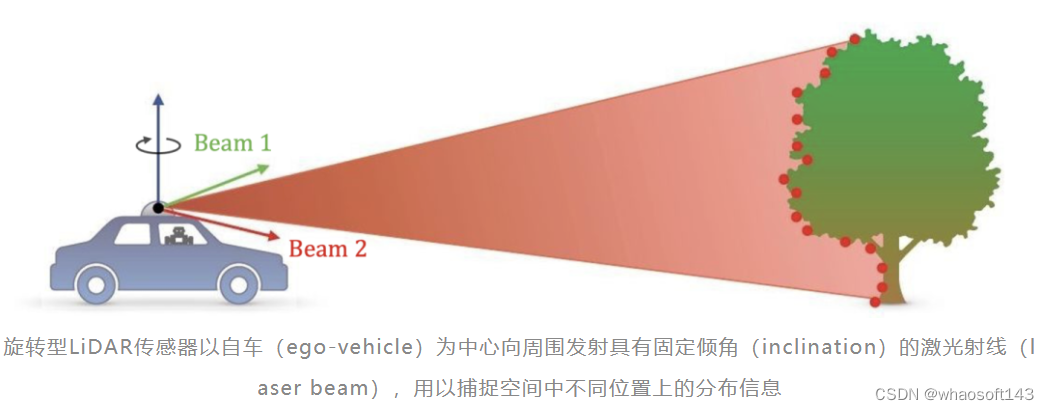
这个工作观察到,无论是静态类别还是动态类别,都在LiDAR点云场景中表现出很强的结构先验(spatial prior)。这样一种先验可以很好地由LiDAR传感器的激光束(laser beam)所表征。以最常见的旋转型LiDAR传感器为例,其以自车为中心向周围各向同性地(isotropically)发射具有固定倾角(inclination)的激光射线。如下图中的简单例子所示,两条射线(Beam 1和Beam 2)分别按照各自预定的倾角由LiDAR传感器发出,探测并返回所捕捉的空间信息。由于不同类别本身具有特殊的分布,由激光射线探测并返回的点便能够较为精准地捕捉到这些不同类别所蕴藏的结构化信息。
如下图(a)所示,对于一个自动驾驶场景(通常为涵盖[-50m, +50m]的大型场景)而言,LiDAR传感器发射出的不同激光射线准确地记录下了各个语义类别的分布情况:road类在靠近自车周围的区域中大量分布,主要由位于下部的射线所收集;vegetation类分布在远离自车的区域,主要由位于上部的具有较大正向倾角(inclination)的射线所收集;而car类主要分布在LiDAR点云场景的中部区域,主要由中间的射线所收集。
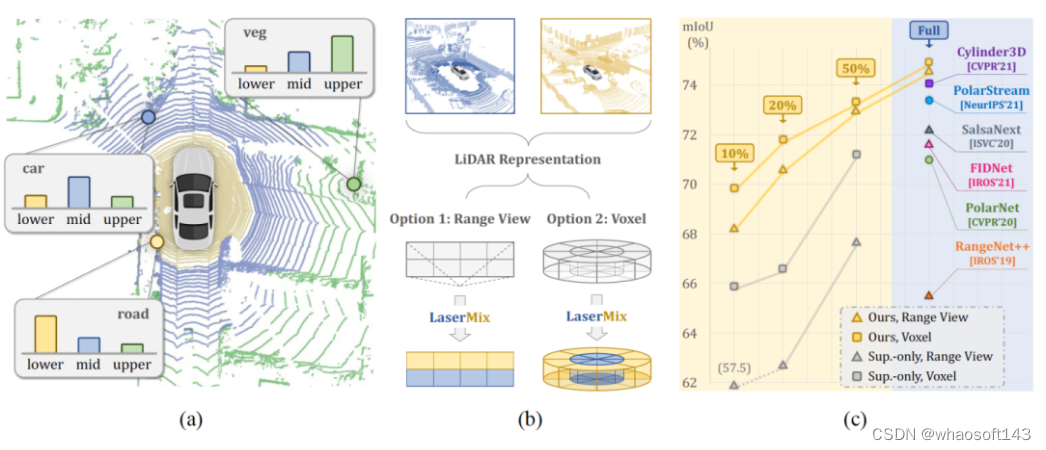
LaserMix框架概览。(a) LiDAR点云包含着很强的结构先验;环绕于自车周围的物体和背景在不同的laser beam(如上、中、下)上有着不同的分布表现。(b) 基于LaserMix的框架适用于各种流行的点云表征,如range view和voxel。(c) LaserMix在low-data和high-data条件下取得了超过各种SoTA方法的表现
基于上述发现,这个工作提出了一个简洁且高效的半监督LiDAR分割框架LaserMix。这个框架主要由以下三个部分组成:
- 点云划分(partition)。利用所观察到LiDAR点云结构化信息,提出了按照点的倾角(inclination)将LiDAR点云划分为“低变区域”(low-variation area)的策略;
- 点云混合(mixing)。将划分好的LiDAR点云依照交织(intertwine)的形式进行混合;
- 一致性约束(consistency regularization)。鼓励模型对不同混合下的同一区域(area)作出高置信度(confident)和高一致性(consistent)的预测。
这个框架具有以下三个重要特点:
- 通用(generic)。LaserMix直接对点进行操作,因此可以适用于绝大多数LiDAR点云表征框架,如range view , bird's eye view , raw points 和cylinder voxel ,等;
- 有统计依据(statistically grounded)。所提出的半监督学习框架具有理论解释,在这个工作对其进行了详尽的分析;
- 高效(effective)。充分的实验结果表明,LaserMix能有效提升半监督场景下的LiDAR分割性能。
基于先验的半监督学习
构建结构先验
真实世界场景下的物体(object)和背景(background)与在LiDAR点云中的空间位置之间展现出了很强的相关性(correlation)。在某一特定区域内,物体和背景遵从着较为相似的“模式”(pattern);举例来说,靠近自车的近距离(close-range)区域内主要包括road类,而远离自车的远距离(long-range)区域主要由building和vegetation等类别组成。


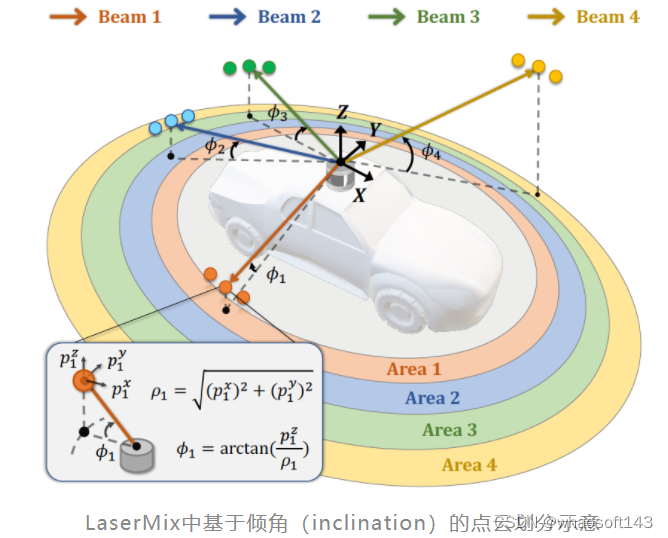
LiDAR点云划分与混合
划分(Partition)

由于LaserMix是直接在点上进行操作的,因此可以适用于各种LiDAR点云表征。这个工作以range view和cylinder voxel这两种表征为例,探究了LaserMix的有效性。其中range view是当前最高效的LiDAR表征方式,具有直观、低内存占用和高推理速度等特点,代表工作有:RangeNet++ ,SqueezeSeg系列 和SalsaNet 等;cylinder voxel是目前分割表现最好的表征,代表工作为Cylinder3D 。
设计理念

LaserMix框架总览
LaserMix的整体网络框架如下图所示。其共包含两个网络:一个学生网络(Student net)和一个教师网络(Teacher net)。
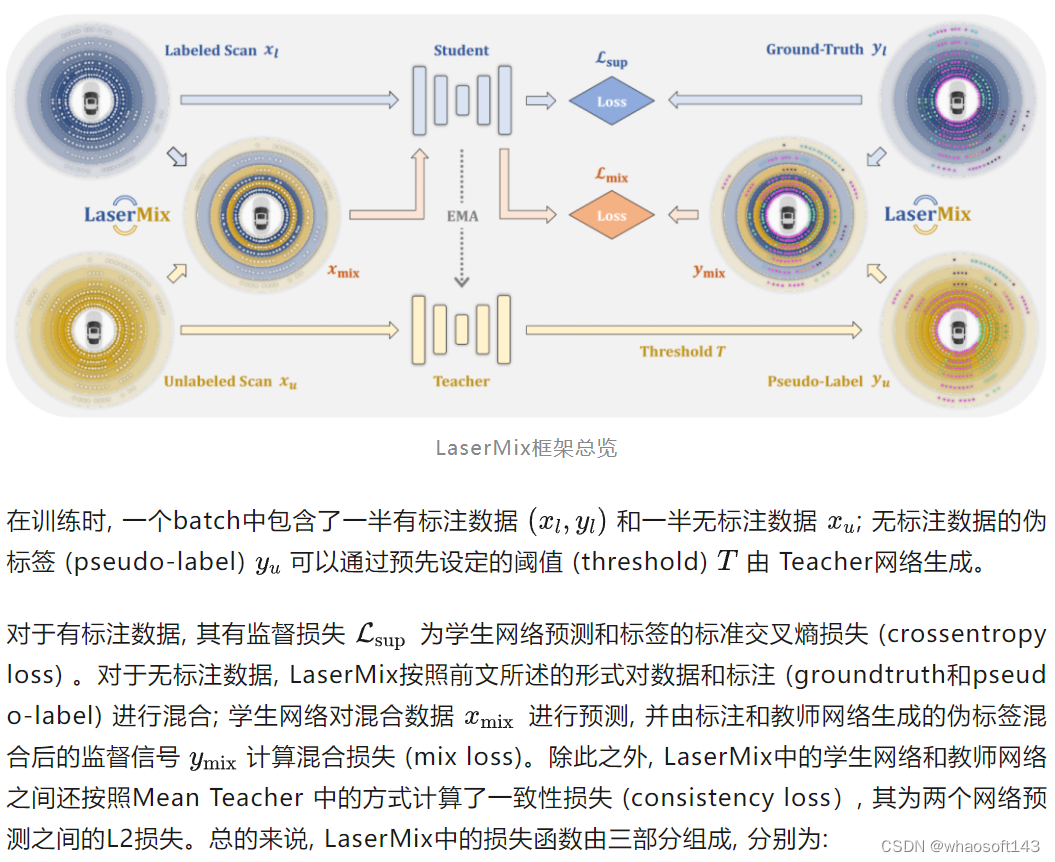

设计理念
LaserMix中提出的这样一个半监督学习框架的目标是最小化前一章节中所述的边缘熵(marginal entropy)。和往常的伪标签优化方法仅仅鼓励预测结果的高置信度(confident)不同,最小化边缘熵要求分割网络的预测兼具高置信度(confident)和高一致性(consistent)。因此,LaserMix以有标注数据和无标注数据为“锚”(anchor),通过结构化的混合来鼓励分割网络输出和监督信号可信且一致的预测。
实验结果
实验配置
数据集
LaserMix在三个LiDAR分割数据集中进行了验证:nuScenes ,SemanticKITTI ,ScribbleKITTI 。其中,nuScenes 数据集中的LiDAR点云较为稀疏,由32线激光雷达所收集;SemanticKITTI 和ScribbleKITTI 中的LiDAR点云较密集,由64线激光雷达所收集。值得一提的是,ScribbleKITTI 采用了涂鸦(scribble)的形式对SemanticKITTI 中的点云进行了标注,其总体的语义标签仅为后者的8%左右。
LaserMix在这样三个特征各异的包含了真实世界数据的数据集上测试,验证了其方法出色的有效性和广泛的适用性。
分割网络
在LiDAR点云分割模型选取方面,LaserMix采用了LiDAR点云表征中最流行的range view和voxel两种形式。其中,range view网络使用了FIDNet ;而voxel网络为Cylinder3D 。这两种分割网络各具特色:range view网络将3D的LiDAR点云投影到2D的range image表征并作为分割网络的输入,其紧凑、结构化和较小的尺寸很好地节约了内存和提高了计算速度,并取得了不错的分割性能;而cylinder voxel网络以规整的网格体素作为分割网络的输入,取得了目前最好的分割结果。
LaserMix在这两种LiDAR点云表征上都进行了验证,体现出该方法的普适性和适配性。
对比实验
作者将上述三个数据集(nuScenes ,SemanticKITTI ,ScribbleKITTI )按照1%,10%,20%和50%的(有标注数据)比例进行了划分,并认为其余数据均为未标注数据。具体的半监督LiDAR点云分割结果如下表所示。其中Sup.-only代表仅使用有标注数据进行训练后的结果,可以理解为该任务的下界(lower bound)。
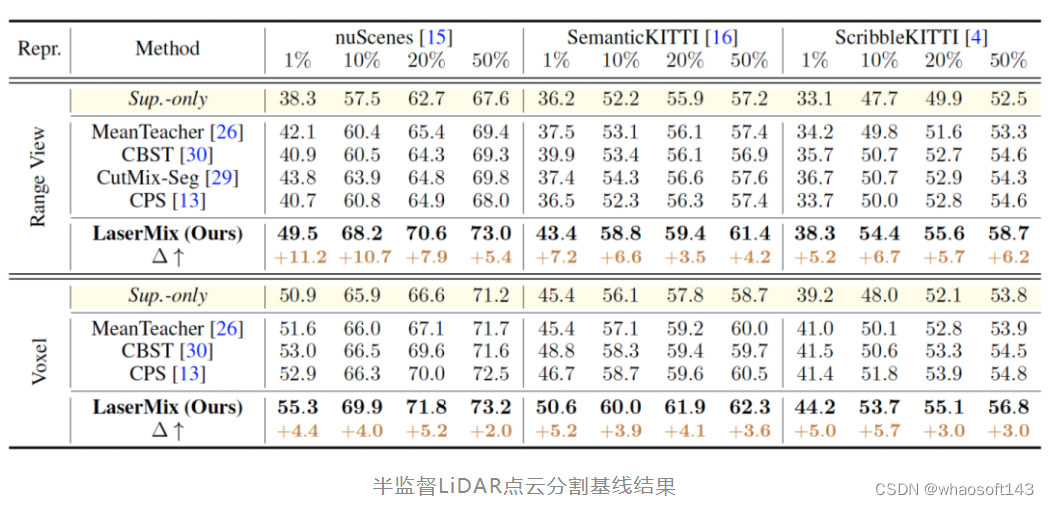
从表中结果可以看出,LaserMix极大地提升了半监督条件下的LiDAR分割结果。无论是在不同的数据集还是不同的LiDAR点云表征下,LaserMix的分割结果都明显地超过了Sup.-only和SoTA的半监督学习方法。
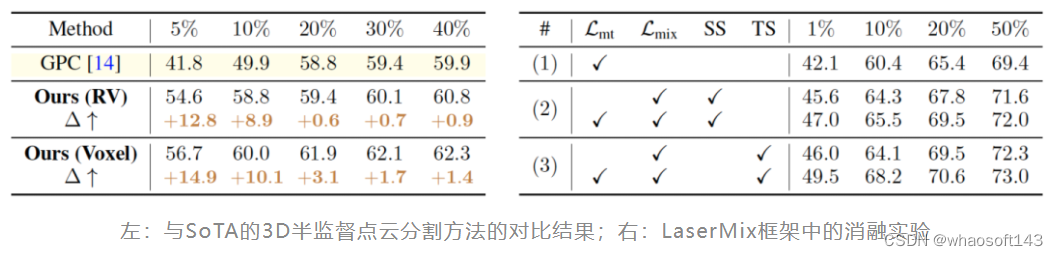
与当前的SoTA点云半监督学习方法GPC 对比(如下表左所示),LaserMix亦在多种半监督数据切分条件下取得了明显优异的性能,尤其是在极少有标注数据(如5%和10%)等场景下的提升尤为明显。
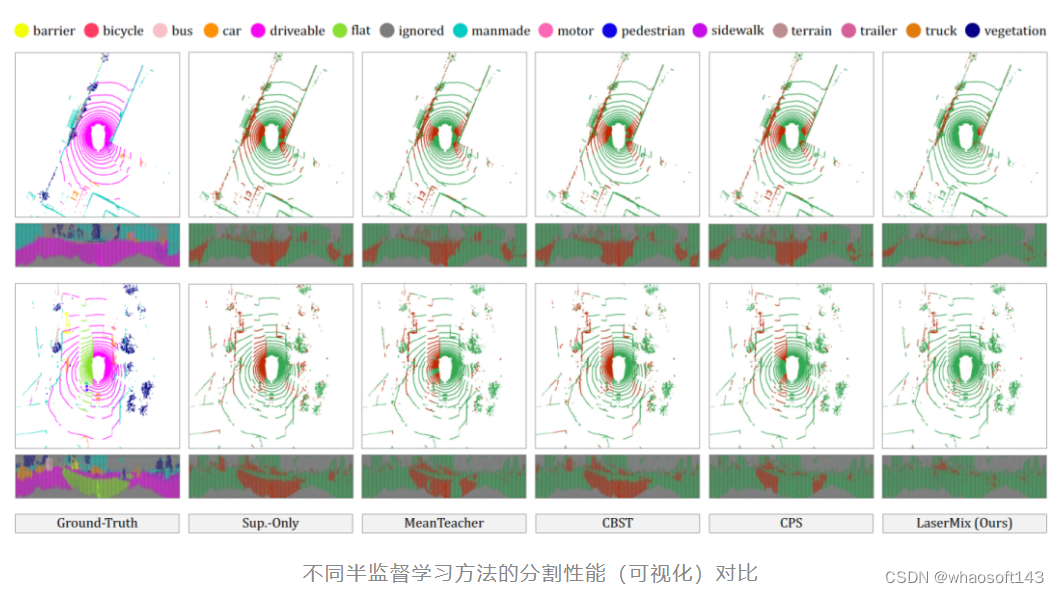
下图所示为不同半监督学习方法的定性结果(qualitative results)。可以看出,与其他方法仅能提升自车(ego-vehicle)周围特定区域的分割性能不同,LaserMix几乎提升绝大部分区域的分割结果。其鼓励混合数据具有高置信度(confident)和高一致性(consistent)预测的理念整体而有效地提升了半监督场景下的LiDAR点云分割性能。
消融实验
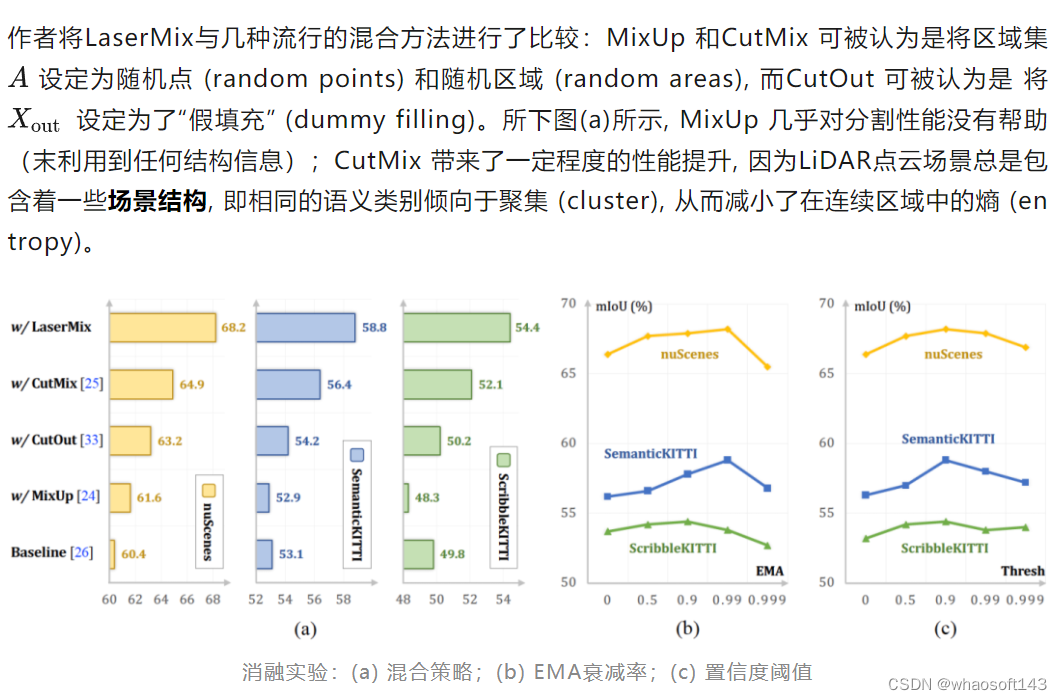
LaserMix提供了更加明显的性能提升:由于其很好地利用了LiDAR点云场景下的结构化的先验信息(即spatial prior),其用于最小化边缘熵(marginal entropy)的区域集 使得分割网络的预测更加的可信(confident)和一致(consistent)。
上图中的(b)和(c)分别探究了LaserMix中的EMA参数了置信度阈值。可以看出,这两组参数比较依赖于数据集本身,即dataset-dependent。总体上看,较高的EMA衰减率(decay rate),如0.9 ~ 0.99,能够较好的鼓励学生网络(Student net)和教师网络(Teacher net)之间的一致性(consistency)。而对置信度阈值 来说,稍高的值,如0.9左右,能够提供较高质量的伪标签(pseudo-label);过高的阈值将减小混合(mix)带来的性能提升(因为过多的预测被设定为了ignored label),而过低的阈值可能会引入较多错误的监督信号,从而对性能提升造成损伤。具体的参数选取依旧需要在目标数据集上进行一定的调参实验才能确定。

的确,按照方位角α进行划分并未充分利用到LiDAR点云的结构化信息:与按照角度划分自车(ego-vehicle)周围360度范围相比,按照倾角ϕ(也即点至自车的空间距离)划分最能体现出LiDAR点云的场景信息。正如我们在开头讨论的那样,不同的语义类别(semantic class)在场景中有着独特的分布方式,如road类在靠近自车周围的区域大量分布,car类主要在中距离的区域分布,而building和vegetation等类别倾向于在远离自车的区域出现。
按照方位角α方向的划分没有充分利用到这样一种结构化信息(即所有的被划分区域中均包含了近、中、远距离上的类别),而仅仅是将自车周围不同的场景(如前视场景和后视场景)进行了拼接。这样一种策略更加接近”直觉“上的数据增强(data augmentation)。不同地,LaserMix按照倾角ϕ进行划分的策略很好地适配了LiDAR点云的场景分布,从而为前文所述的半监督学习框架构建了较优的低熵区域(low-entropy areas),整体地提升了半监督条件下的LiDAR点云分割性能。
结论与讨论
这个工作提出了一个名为LaserMix的用于半监督LiDAR点云分割的框架。该工作不仅为所提出的框架提供有统计依据(statistically grounded)的解释,还通过在不同数据集和不同LiDAR表征形式下的大量实验,进一步验证了其方法的有效性和强适用性。该工作中提出的LiDAR点云场景划分方法(即按照LiDAR传感器的倾角ϕ对点云进行划分)很好地适配了自动驾驶场景的结构化特征,为未来的LiDAR点云分割工作提供了一个有潜力的发展思路。















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









