






最近由于项目需要,要对tensorflow构造的模型中部分变量冻结,然后继续训练,因此研究了一下tf中冻结变量的方法,目前找到三种,各有优缺点,记录如下:
1.名词解释
冻结变量,指的是在训练模型时,对某些可训练变量不更新,即仅参与前向loss计算,不参与后向传播,一般用于模型的finetuning等场景。例如:我们在其他数据上训练了一个resnet152模型,然后希望在目前数据上做finetuning,一般来讲,网络的前几层卷积是用来提取底层图像特征的,因此可以对前3个卷积层进行冻结,不改变其weight和bias的数值。
2.方法介绍
目前我找到了三种tf冻结变量的方法,各有优缺点,具体如下:
2.1 trainable=False
一切tf.Variable或tf.Variable的子类,在创建时,都有一个trainable参数,在tf官方文档(https://www.tensorflow.org/api_docs/python/tf/Variable)中有对这个参数的定义,
![]()
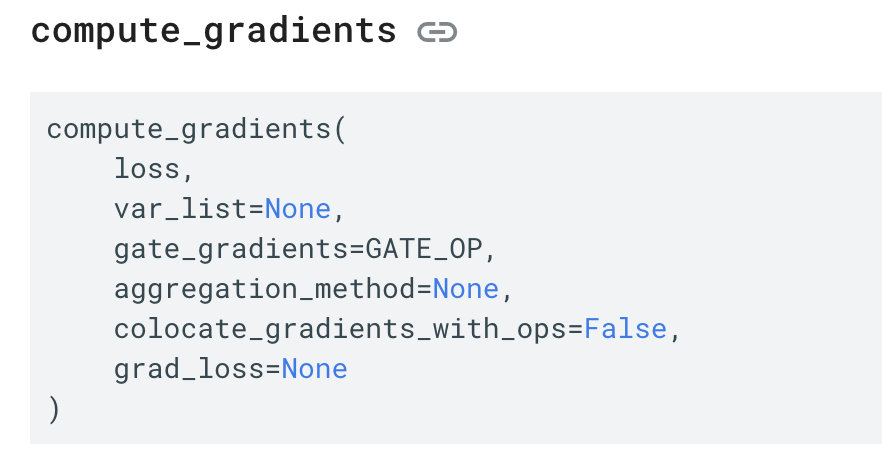
意思是,如果trainable设置为True,就会把变量添加到GraphKeys.TRAINABLE_VARIABLES集合中,如果是False,则不添加。而在计算梯度进行后向传播时,我们一般会使用一个optimizer,然后调用该optimizer的compute_gradients方法。在compute_gradients中,第二个参数var_list如果不传入,则默认为GraphKeys.TRAINABLE_VARIABLES。
总结下,trainable=False冻结变量的逻辑:trainable=False → 该变量不会放入GraphKeys.TRAINABLE_VARIABLES → 调用optimizer.compute_gradients方法时默认变量列表为GraphKeys.TRAINABLE_VARIABLES,该变量不在其中,因此不参与后向传播,值不进行更新,达到冻结变量效果。
优点:操作简单,只要在你创建变量时设置trainable=False即可
缺点:不知道大家发现没有,我上面的总结中,optimizer.compute_gradients方法默认变量列表是GraphKeys.TRAINABLE_VARIABLES,这句话还意味着,如果我不想用默认变量列表,而使用自定义变量列表,那么即使设置了trainable=False,只要把该变量加入到自定义变量列表中,变量还是会参与后向传播的,值也会更新。另外,tf.layers、tf.contrib.rnn等一些高度封装的API是不支持这个参数的,没法用该方法冻结变量。最后,如果我们在使用Saver保存ckpt时,一般调动tf.trainable_variables()方法只保存可训练参数,这时返回的变量列表,也有上面的问题,即设置了trainable=False的变量不会在里面。
2.2 tf.stop_gradient()
我们还可以通过在某个变量外面包裹一层tf.stop_gradient()函数来达到冻结变量的目的。例如我们想冻结w1,可以写成这样:
w1 = tf.stop_gradient(w1)
在后向传播时,w1的值就不会更新。下面说下优缺点。
优点:操作简单,针对想冻结的变量,添加上面这一行即可,而且相比于上一个方法,设置了tf.stop_gradient()的变量,不会从GraphKeys.TRAINABLE_VARIABLES集合中去除,因此不会影响梯度计算和保存模型
缺点:和上一个方法类似,tf.stop_gradient()的输入是Tensor,tf.layers、tf.contrib.rnn等一些高度封装的API的返回值没法作为参数传入,即不能用该方法冻结
2.3 optimizer.compute_gradients(loss,var_list=no_freeze_vars)
optimizer.compute_gradients在2.1中提到过,其实我们只需要在计算梯度时,指定变量列表,把希望冻结的变量去除,即可完成冻结变量。但这么做有一个前提,我们必须知道所有可训练变量的名字,并根据一些规则去除变量。获取所有可训练变量名字调用tf.trainable_variables()方法即可,但去除变量则需要我们在构建网络的时候,合理利用tf.variable_scope,对不同变量做区分。例如,我们如果想把可训练变量中所有卷积层变量冻结,可以这么写:
trainable_vars = tf.trainable_variables() freeze_conv_var_list = [t for t in trainable_vars if not t.name.startswith(u'conv')] grads = opt.compute_gradients(loss, var_list=freeze_conv_var_list)
下面总结下优缺点,
优点:没有2.1和2.2的缺点,是一种适用范围更加广泛的方法
缺点:相对2.1,2.2使用起来比较复杂,需要自己去除冻结变量,并且variable_scope不能随意改动,因为可能使去除变量的过滤操作无效化。例如:如果把原来'cnn' scope改为'vgg',那么上面的代码就无效了
3.总结
tf对于一些常用操作,往往会提供多种方法,但每种方法一般都是有区别的,并且操作原理和后面的逻辑也会有不同,要谨慎使用














 6885
6885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









