






 博客讲述了配置supervisor时遇到Exited too quickly错误的解决过程。经查看program块配置,发现测试时运行命令sleep 1,而startsecs设为3,supervisor认为程序执行太快出错,将命令改成sleep 4后问题解决。
博客讲述了配置supervisor时遇到Exited too quickly错误的解决过程。经查看program块配置,发现测试时运行命令sleep 1,而startsecs设为3,supervisor认为程序执行太快出错,将命令改成sleep 4后问题解决。
在配置supervisor的时候,提示Exited too quickly (process log may have details),这个时候一脸懵逼,啥回事,执行太快了???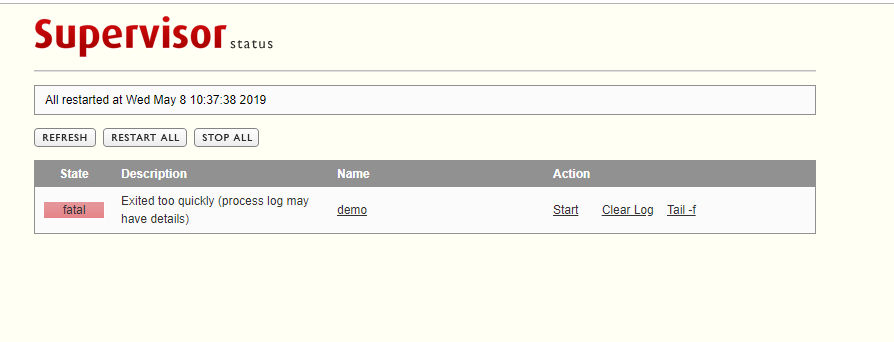
然后仔细看了program块的配置,发现由于自己是在测试,运行的命令是sleep 1,而startsecs设置为3,supervisor认为程序执行太快导致出错,把命令改成sleep 4就可以了
[program:demo]
command=sleep 1
directory=/
autostart=true
startsecs=3
autorestart=true
startretries=3
; user=root
priority=999
redirect_stderr=true
stdout_logfile_maxbytes=20MB
stdout_logfile_backups = 20
stdout_logfile=/tmp/supervisord/demo.log
stopasgroup=false
killasgroup=false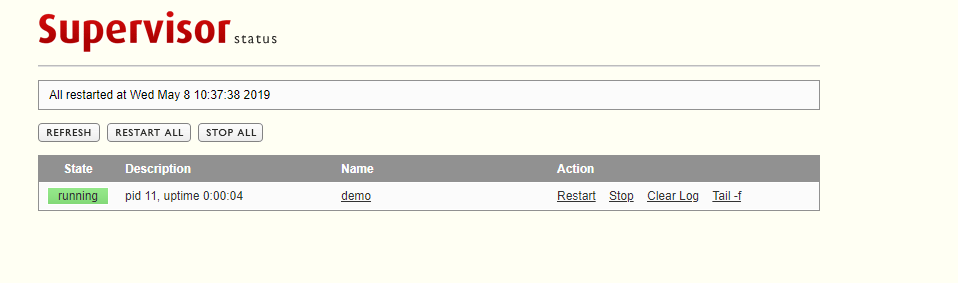

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









