






1. N 阶乘末尾0的个数。
输入描述:
输入为一行,n(1 ≤ n ≤ 1000)输出描述:
输出一个整数,即题目所求
解法:要判断末尾有几个0就是判断可以整除几次10。10的因子有5和2,而在0~9之间5的倍数只有一个,2的倍数相对较多,所以本题也就转换成了求N阶乘中有几个5的倍数。
也就是每多出来一个5,阶乘末尾就会多出来一个0,这样n / 5就能统计完第一层5的个数,依次处理,就能统计出来所有5的个数。同一个思想两种写法。public class Main {
public int calcuZero(int n) {
int count = 0;
for (int i = 1; i <= n; i++) {
int cur = i;
//如果因数中有一个5那么乘积中就会有一个0,所以计算每一个i中因数5的个数
while (cur % 5 == 0) {
count++;
cur /= 5;
}
}
return count;
}
public static void main(String[] args) {
System.out.println(new Main().calcuZero(30));
}
}
#include<iostream>
using namespace std;
int main()
{
int n;
cin>>n;
int count = 0;
while(n)
{
n /= 5; //算出当前数字中可以匹配5(5和5的倍数)的个数
count += n; //累加之
}
cout<<count;
return 0;
}
2. 判断一颗二叉树是否为镜像对称
解法:判断一个数是否为镜像对称:先判断根,在判断左右子树。如果左右子树都为空那就是,如果左右子树不是同时为空那就不是
当左右子树都存在的时候,判断他们的值是否相等,如果相等那么久递归的对他们的字节点判断(左边的左=右边的右;左边的右==右边的左)
/**
* Definition for binary tree
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool isSymmetric(TreeNode *root) {
if (!root)
return true;
return Symmetric(root->left, root->right);
}
bool Symmetric(TreeNode *left, TreeNode *right){
if (!left && !right)
return true;
if (!left || !right)
return false;
if (left->val == right->val){
return (Symmetric(left->left, right->right) && Symmetric(right->left, left->right));
}
return false;
}
};
3. 给定数组,从数组中取出n个不复用的数的和为sum
深搜,
void findd(vector<int>&vr,int pos,int sum,int m,int& res){
if(sum==m){
res++;
return;
}
else if(sum>m){
return;
}else{
if(pos<vr.size()){
sum+=vr[pos];
findd(vr,pos+1,sum,m,res);
sum-=vr[pos];
findd(vr,pos+1,sum,m,res);
}
}
}
DP
int main(){
int n=0;
int m=0;
while(cin>>n>>m){
vector<int> vr(n);
for(int i=0;i<n;++i){
cin>>vr[i];
}
sort(vr.begin(),vr.end(),greater<int>());
vector<vector<long long int>>dp(n,vector<long long int>(m+1,0));
for(int i=0;i<n;++i){
dp[i][0]=1;
}
for(int i=1;i<=m;i++){
if(vr[0]>m)//过滤
break;
if(vr[0]==i)
dp[0][i]=1;
else
dp[0][i]=0;
}
for(int i=1;i<n;++i){
if(vr[i]>m) //过滤
continue;
for(int j=1;j<=m;++j){
if(j-vr[i]>=0)
dp[i][j]=dp[i-1][j]+dp[i-1][j-vr[i]];
else
dp[i][j]=dp[i-1][j];
}
}
cout<<dp[n-1][m]<<endl;
}
return 0;
}
4. 给定一个二叉树和其中一个节点,如何找出中序遍历顺序的下一个节点?树中的节点除了有两个分别指向左右子节点的指针以外,还有一个指向父节点的指针.
解法:如果一个节点有右子树,那么它的下一个节点就是它的右子树中的最左子节点。
如果没有右子树,且它是父节点的左子节点,那么它的下一个节点就是它的父节点。
如果一个节点即没有右子树,并且它还是父节点的右子节点,这种情况比较复杂。我们可以沿着指向父节点的指针一直向上遍历,直到找到一个是它父节点的左子节点的节点。如果这样的节点存在,那么这个节点的父节点就是我们要找的下一个节点。
如果一个节点不满足上述所有情况,那么它应该就是中序遍历的最后一个节点。所以返回NULL
struct BinaryTreeNode {
int val;
BinaryTreeNode* parent;
BinaryTreeNode* left;
BinaryTreeNode* right;
};
BinaryTreeNode* GetNext(BinaryTreeNode* root) {
if (root == NULL) return NULL;
BinaryTreeNode* next_node = NULL;
//如果节点有右子树,那么它的下一个节点就是它的右子树中最左边的节点
if (root->right != NULL) {
next_node = root->right;
while (next_node->left != NULL)
next_node = next_node->left;
return next_node;
}
if (root->parent != NULL) {
if (root == root->parent->left) {//当前节点是父节点的左子节点
return root->parent;
} else {
BinaryTreeNode* parent_node = root->parent;
BinaryTreeNode* current_node = root;
while (parent_node != NULL && current_node == parent_node->left) {
current_node = parent_node;
parent_node = parent_node->parent;
}
return parent_node;
}
}
return NULL;
}
5. 求一个无序数组的中位数
求一个无序数组的中位数。
如:{2,5,4,9,3,6,8,7,1}的中位数为5,{2,5,4,9,3,6,8,7,1,0}的中位数为4和5。
解法:利用快排的思想。任意挑一个元素,以改元素为支点,划分集合为两部分,如果左侧集合长度恰为 (n-1)/2,那么支点恰为中位数。如果左侧长度<(n-1)/2, 那么中位点在右侧,反之,中位数在左侧。 进入相应的一侧继续寻找中位点。
//快排方法,分治思想
int PartSort(int arr[], int left,int right)
{
int key = arr[right];
while (left < right)
{
//key右边,先从左找比key值大
while (left < right && arr[left] <= key)
++left;
if (left < right)
{
arr[right] = arr[left];
--right;
}
//从右找比key小
while (left < right && arr[right] >= key)
--right;
if (left < right)
{
arr[left] = arr[right];
++left;
}
}
arr[left] = key;
return left;
}
void GetMid3(int arr[],int size)
{
int left = 0;
int right = size - 1;
int mid = size / 2;
int div = PartSort(arr, left, right);
while (div != mid)
{
if (div < mid)//右半区间
div = PartSort(arr, div + 1, right);
else
div = PartSort(arr, left, div - 1);
}
cout << "中位数" << arr[div] << endl;
}
6. 有序的数组中找到某一目标值首次出现的下标
给定一个升序的数组,这个数组中可能含有相同的元素,并且给定一个目标值。要求找出目标值在数组中首次出现的下标。
思想:题目给出有序数组,应该想到利用二分查找来做。找到左邻居,使其值加一。利用二分查找,算法复杂度为O(logn)
#include<iostream>
using namespace std;
int findsearch(int *p, int length, int target)
{
int left = 0;
int right = length-1 ;
if (p[right - 1] < target&&length<0&&p==NULL)
return - 1;
while (left < right)
{
int mid = (left + right) / 2;
if (p[mid] < target)
left = mid + 1;
else
right = mid;
}
if (p[left] == target)
return left;
else
return -1;
}
int main()
{
int p[] = { 4,6,6,6,6 };
int length = 5;
int target =6;
int index = findsearch(p, length, target);
cout << index << endl;
}
找到有序数组中某一目标值在数组中的开始下标以及终止下标以及目标值出现的次数。也可以用下面的方法:
#include <iostream>
using namespace std;
//查找指定数字在有序数组中出现的次数,isLeft标记最左和最右
int FindCntofNum(int a[], int len, int num, bool isLeft)
{
int left = 0, right = len - 1;
int pos, mid;
while (left <= right)//二分查找
{
mid = (left + right) / 2;
if (a[mid] < num)
left = mid + 1;
else if (a[mid] > num)
right = mid - 1;
else
{
pos = mid;
if (isLeft)//查找最左值
right = mid - 1;
else//查找最右值
left = mid + 1;
}
}
return pos;//返回最终查找到的位置
}
int main()
{
int a[7] = { 1, 2, 3, 4, 4, 5 ,6};
int left, right, dst;
left = FindCntofNum(a, 7, 4, true);
right = FindCntofNum(a, 7, 4, false);
dst = right - left + 1;
cout<< dst<<endl;
return 0;
}
7. 给两个链表,每个节点存储一个数字,实现两个节点之间的数字相加,返回相加后的数字链表
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
public class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode l3 = new ListNode(0);
ListNode res = l3;
int value = 0;
int flag = 0;
while (l1 != null || l2 != null || flag == 1) {
int sum = flag;
sum += (l1 != null ? l1.val : 0) + (l2 != null ? l2.val : 0);
l1 = (l1 != null ? l1.next : null);
l2 = (l2 != null ? l2.next : null);
l3.next = new ListNode(sum % 10);
flag = sum / 10;
l3 = l3.next;
}
return res.next;
}
}
8. 全排列
#include <iostream>
#include <cstdio>
#include <cstring>
#include <cmath>
#include <algorithm>
using namespace std;
typedef long long LL;
const int maxn=1000005;
int n,m;
int a[maxn];
void perm(int s,int e)
{
if(s==e)
{
for(int i=0;i<=e;i++)
printf("%d ",a[i]);
printf("\n");
}
else
{
for(int i=s;i<=e;i++)
{
swap(a[i],a[s]);
perm(s+1,e);
swap(a[i],a[s]);
}
}
}
int main()
{
scanf("%d",&n);
for(int i=0;i<n;i++)
scanf("%d",&a[i]);
perm(0,n-1);
return 0;
}
9. 最大连续和
#include <iostream>
#include <cstdio>
using namespace std;
int a[9]={-2,1,-3,4,-1,2,1,-5,4};
int l,r;
int maxsum(int l,int r)
{
int ans;
if(r==l)
return a[l];
int mid=(l+r)/2;
ans=max(maxsum(l,mid),maxsum(mid+1,r));
int templ=a[mid],t=0;
for(int i=mid;i>=l;i--)
templ=max(templ,t+=a[i]);
int tempr=a[mid+1];t=0;
for(int i=mid+1;i<=r;i++)
tempr=max(tempr,t+=a[i]);
return max(ans,templ+tempr);
}
int main()
{
scanf("%d %d",&l,&r);
printf("%d\n",maxsum(l,r));
return 0;
}
10. 无重复字符的最长子串
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
解法参考:https://www.cnblogs.com/jkzr/p/10595113.html
11. 最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入: ["flower","flow","flight"]
输出: "fl"
示例 2:
输入: ["dog","racecar","car"]
输出: ""
解释: 输入不存在公共前缀。
说明:
所有输入只包含小写字母 a-z 。
解法:按照题匹配就可以了。
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
string ans;
if(strs.empty())
return ans;
for(int i=0;i<strs[0].size();i++)
{
char c=strs[0][i];
for(int j=1;j<strs.size();j++)
{
if(i>=strs[j].size() || strs[j][i]!=c)
return ans;
}
ans+=c;
}
return ans;
}
};
12. 字符串相乘
给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。
示例 1:
输入: num1 = "2", num2 = "3"
输出: "6"
示例 2:
输入: num1 = "123", num2 = "456"
输出: "56088"
说明:
num1和num2的长度小于110。num1和num2只包含数字0-9。num1和num2均不以零开头,除非是数字 0 本身。- 不能使用任何标准库的大数类型(比如 BigInteger)或直接将输入转换为整数来处理。
解法参考:https://www.cnblogs.com/jkzr/p/10621843.html
13. 翻转字符串里的单词
给定一个字符串,逐个翻转字符串中的每个单词。
示例 1:
输入: "the sky is blue"
输出: "blue is sky the"
示例 2:
输入: " hello world! "
输出: "world! hello"
解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
示例 3:
输入: "a good example"
输出: "example good a"
解释: 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
解法:遍历这个字符串,按照题意我们采用stack 来存储这些字符串然后输出即可。
class Solution {
public:
string reverseWords(string s) {
stack<string> str;
string s0 = "";
if(s.empty())
{
s = "";
return s;
}
for(int i=0;i<s.length();i++)
{
if(s[i]!=' ')
{
s0+=s[i];
continue;
} //得到字符组成字符串。
else if(!s0.empty())
{
str.push(s0);
s0="";
}
}
if(!s0.empty())
{
str.push(s0);
s0="";
}
while(!str.empty())
{
s0+=str.top();
str.pop();
s0+=" ";
}
if(s0.empty())
{
s = "";
return s;
}
s0.erase(s0.end()-1);
s = s0;
return s;
}
};
14. 简化路径
以 Unix 风格给出一个文件的绝对路径,你需要简化它。或者换句话说,将其转换为规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。更多信息请参阅:Linux / Unix中的绝对路径 vs 相对路径
请注意,返回的规范路径必须始终以斜杠 / 开头,并且两个目录名之间必须只有一个斜杠 /。最后一个目录名(如果存在)不能以 / 结尾。此外,规范路径必须是表示绝对路径的最短字符串。
示例 1:
输入:"/home/"
输出:"/home"
解释:注意,最后一个目录名后面没有斜杠。
示例 2:
输入:"/../"
输出:"/"
解释:从根目录向上一级是不可行的,因为根是你可以到达的最高级。
示例 3:
输入:"/home//foo/"
输出:"/home/foo"
解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。
示例 4:
输入:"/a/./b/../../c/"
输出:"/c"
class Solution {
public:
string simplifyPath(string path) {
vector<string> v;
int i = 0;
while (i < path.size()) {
while (path[i] == '/' && i < path.size()) ++i;
if (i == path.size()) break;
int start = i;
while (path[i] != '/' && i < path.size()) ++i;
int end = i - 1;
string s = path.substr(start, end - start + 1);
if (s == "..") {
if (!v.empty()) v.pop_back();
} else if (s != ".") {
v.push_back(s);
}
}
if (v.empty()) return "/";
string res;
for (int i = 0; i < v.size(); ++i) {
res += '/' + v[i];
}
return res;
}
};
15. 给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。
示例:
输入: "25525511135"
输出: ["255.255.11.135", "255.255.111.35"]
public class Solution {
public List<String> restoreIpAddresses(String s) {
List<String> res = new ArrayList<String>();
for (int a = 1; a < 4; ++a)
for (int b = 1; b < 4; ++b)
for (int c = 1; c < 4; ++c)
for (int d = 1; d < 4; ++d)
if (a + b + c + d == s.length()) {
int A = Integer.parseInt(s.substring(0, a));
int B = Integer.parseInt(s.substring(a, a + b));
int C = Integer.parseInt(s.substring(a + b, a + b + c));
int D = Integer.parseInt(s.substring(a + b + c));
if (A <= 255 && B <= 255 && C <= 255 && D <= 255) {
String t = String.valueOf(A) + "." + String.valueOf(B) + "." + String.valueOf(C) + "." + String.valueOf(D);
if (t.length() == s.length() + 3) res.add(t);
}
}
return res;
}
}
class Solution {
public:
vector<string> restoreIpAddresses(string s) {
vector<string> res;
restore(s, 4, "", res);
return res;
}
void restore(string s, int k, string out, vector<string> &res) {
if (k == 0) {
if (s.empty()) res.push_back(out);
}
else {
for (int i = 1; i <= 3; ++i) {
if (s.size() >= i && isValid(s.substr(0, i))) {
if (k == 1) restore(s.substr(i), k - 1, out + s.substr(0, i), res);
else restore(s.substr(i), k - 1, out + s.substr(0, i) + ".", res);
}
}
}
}
bool isValid(string s) {
if (s.empty() || s.size() > 3 || (s.size() > 1 && s[0] == '0')) return false;
int res = atoi(s.c_str());
return res <= 255 && res >= 0;
}
};
16. 两数之和
Given an array of integers, return indices of the two numbers such that they add up to a specific target.
You may assume that each input would have exactly one solution, and you may not use the same element twice.
Example:
Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0, 1].
解法:用线性的时间复杂度来解决问题,那么就是说只能遍历一个数字,那么另一个数字呢,我们可以事先将其存储起来,使用一个HashMap,来建立数字和其坐标位置之间的映射,我们都知道HashMap是常数级的查找效率,这样,我们在遍历数组的时候,用target减去遍历到的数字,就是另一个需要的数字了,直接在HashMap中查找其是否存在即可。
public class Solution {
public int[] twoSum(int[] nums, int target) {
HashMap<Integer, Integer> m = new HashMap<Integer, Integer>();
int[] res = new int[2];
for (int i = 0; i < nums.length; ++i) {
m.put(nums[i], i);
}
for (int i = 0; i < nums.length; ++i) {
int t = target - nums[i];
if (m.containsKey(t) && m.get(t) != i) {
res[0] = i;
res[1] = m.get(t);
break;
}
}
return res;
}
}
17. 三数之和
给定一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?找出所有满足条件且不重复的三元组。
注意:答案中不可以包含重复的三元组。
例如, 给定数组 nums = [-1, 0, 1, 2, -1, -4],
满足要求的三元组集合为:
[
[-1, 0, 1],
[-1, -1, 2]
]
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
vector<vector<int>> res;
sort(nums.begin(), nums.end());
if (nums.empty() || nums.back() < 0 || nums.front() > 0) return {};
for (int k = 0; k < nums.size(); ++k) {
if (nums[k] > 0) break;
if (k > 0 && nums[k] == nums[k - 1]) continue;
int target = 0 - nums[k];
int i = k + 1, j = nums.size() - 1;
while (i < j) {
if (nums[i] + nums[j] == target) {
res.push_back({nums[k], nums[i], nums[j]});
while (i < j && nums[i] == nums[i + 1]) ++i;
while (i < j && nums[j] == nums[j - 1]) --j;
++i; --j;
} else if (nums[i] + nums[j] < target) ++i;
else --j;
}
}
return res;
}
};
18. 四数之和
Given an array S of n integers, are there elements a, b, c, and d in S such that a + b + c + d = target? Find all unique quadruplets in the array which gives the sum of target.
Note:
- Elements in a quadruplet (a,b,c,d) must be in non-descending order. (ie, a ≤ b ≤ c ≤ d)
- The solution set must not contain duplicate quadruplets.
For example, given array S = {1 0 -1 0 -2 2}, and target = 0.
A solution set is:
(-1, 0, 0, 1)
(-2, -1, 1, 2)
(-2, 0, 0, 2)
class Solution {
public:
vector<vector<int>> fourSum(vector<int> &nums, int target) {
set<vector<int>> res;
sort(nums.begin(), nums.end());
for (int i = 0; i < int(nums.size() - 3); ++i) {
for (int j = i + 1; j < int(nums.size() - 2); ++j) {
if (j > i + 1 && nums[j] == nums[j - 1]) continue;
int left = j + 1, right = nums.size() - 1;
while (left < right) {
int sum = nums[i] + nums[j] + nums[left] + nums[right];
if (sum == target) {
vector<int> out{nums[i], nums[j], nums[left], nums[right]};
res.insert(out);
++left; --right;
} else if (sum < target) ++left;
else --right;
}
}
}
return vector<vector<int>>(res.begin(), res.end());
}
};
19. 最近三数之和
Given an array S of n integers, find three integers in S such that the sum is closest to a given number, target. Return the sum of the three integers. You may assume that each input would have exactly one solution.
For example, given array S = {-1 2 1 -4}, and target = 1.
The sum that is closest to the target is 2. (-1 + 2 + 1 = 2).
class Solution {
public:
int threeSumClosest(vector<int>& nums, int target) {
int closest = nums[0] + nums[1] + nums[2];
int diff = abs(closest - target);
sort(nums.begin(), nums.end());
for (int i = 0; i < nums.size() - 2; ++i) {
int left = i + 1, right = nums.size() - 1;
while (left < right) {
int sum = nums[i] + nums[left] + nums[right];
int newDiff = abs(sum - target);
if (diff > newDiff) {
diff = newDiff;
closest = sum;
}
if (sum < target) ++left;
else --right;
}
}
return closest;
}
};
20. 三数之和较小值
Given an array of n integers nums and a target, find the number of index triplets i, j, k with 0 <= i < j < k < n that satisfy the condition nums[i] + nums[j] + nums[k] < target.
For example, given nums = [-2, 0, 1, 3], and target = 2.
Return 2. Because there are two triplets which sums are less than 2:
[-2, 0, 1]
[-2, 0, 3]
Follow up:
Could you solve it in O(n2) runtime?
// O(n^2)
class Solution {
public:
int threeSumSmaller(vector<int>& nums, int target) {
if (nums.size() < 3) return 0;
int res = 0, n = nums.size();
sort(nums.begin(), nums.end());
for (int i = 0; i < n - 2; ++i) {
int left = i + 1, right = n - 1;
while (left < right) {
if (nums[i] + nums[left] + nums[right] < target) {
res += right - left;
++left;
} else {
--right;
}
}
}
return res;
}
};
21. 岛屿的最大面积
给定一个包含了一些 0 和 1的非空二维数组 grid , 一个 岛屿 是由四个方向 (水平或垂直) 的 1 (代表土地) 构成的组合。你可以假设二维矩阵的四个边缘都被水包围着。
找到给定的二维数组中最大的岛屿面积。(如果没有岛屿,则返回面积为0。)
示例 1:
[[0,0,1,0,0,0,0,1,0,0,0,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,1,1,0,1,0,0,0,0,0,0,0,0],
[0,1,0,0,1,1,0,0,1,0,1,0,0],
[0,1,0,0,1,1,0,0,1,1,1,0,0],
[0,0,0,0,0,0,0,0,0,0,1,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,0,0,0,0,0,0,1,1,0,0,0,0]]
对于上面这个给定矩阵应返回 6。注意答案不应该是11,因为岛屿只能包含水平或垂直的四个方向的‘1’。
示例 2:
[[0,0,0,0,0,0,0,0]]
对于上面这个给定的矩阵, 返回 0。
注意: 给定的矩阵grid 的长度和宽度都不超过 50。
解法:https://www.cnblogs.com/jkzr/p/10594833.html
22. 搜索旋转排序数组
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
搜索一个给定的目标值,如果数组中存在这个目标值,则返回它的索引,否则返回 -1 。
你可以假设数组中不存在重复的元素。
你的算法时间复杂度必须是 O(log n) 级别。
示例 1:
输入: nums = [4,5,6,7,0,1,2], target = 0
输出: 4
示例 2:
输入: nums = [4,5,6,7,0,1,2], target = 3
输出: -1
解法:二分搜索法的关键在于获得了中间数后,判断下面要搜索左半段还是右半段,我们观察上面红色加粗的数字都是升序的,由此我们可以观察出规律,如果中间的数小于最右边的数,则右半段是有序的,若中间数大于最右边数,则左半段是有序的,我们只要在有序的半段里用首尾两个数组来判断目标值是否在这一区域内,这样就可以确定保留哪半边了。
class Solution {
public:
int search(int A[], int n, int target) {
if (n == 0) return -1;
int left = 0, right = n - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (A[mid] == target) return mid;
else if (A[mid] < A[right]) {
if (A[mid] < target && A[right] >= target) left = mid + 1;
else right = mid - 1;
} else {
if (A[left] <= target && A[mid] > target) right = mid - 1;
else left = mid + 1;
}
}
return -1;
}
};
23. 最长连续递增序列
给定一个未经排序的整数数组,找到最长且连续的的递增序列。
示例 1:
输入: [1,3,5,4,7]
输出: 3
解释: 最长连续递增序列是 [1,3,5], 长度为3。
尽管 [1,3,5,7] 也是升序的子序列, 但它不是连续的,因为5和7在原数组里被4隔开。
示例 2:
输入: [2,2,2,2,2]
输出: 1
解释: 最长连续递增序列是 [2], 长度为1。
解法:https://www.cnblogs.com/jkzr/p/10594859.html
24. 数组中的第K个最大元素
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例 1:
输入: [3,2,1,5,6,4] 和 k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
输出: 4
说明:
你可以假设 k 总是有效的,且 1 ≤ k ≤ 数组的长度
解法:https://www.cnblogs.com/jkzr/p/10594868.html
25. 最长连续序列
给定一个未排序的整数数组,找出最长连续序列的长度。
要求算法的时间复杂度为 O(n)。
示例:
输入: [100, 4, 200, 1, 3, 2]
输出: 4
解释: 最长连续序列是 [1, 2, 3, 4]。它的长度为 4。
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
int si=nums.size();
if(si==0)
return 0;
if(si==1)
return 1;
sort(nums.begin(),nums.end());
nums.erase(unique(nums.begin(),nums.end()),nums.end());
int ans=1,temp=1;
for(int i=1;i<si;i++)
{
while(i<si&&nums[i]==nums[i-1]+1)
{
temp++;
i++;
}
ans=ans<temp?temp:ans;
temp=1;
}
return ans;
}
};
26. 第k个排列
给出集合 [1,2,3,…,n],其所有元素共有 n! 种排列。
按大小顺序列出所有排列情况,并一一标记,当 n = 3 时, 所有排列如下:
"123""132""213""231""312""321"
给定 n 和 k,返回第 k 个排列。
说明:
- 给定 n 的范围是 [1, 9]。
- 给定 k 的范围是[1, n!]。
示例 1:
输入: n = 3, k = 3
输出: "213"
示例 2:
输入: n = 4, k = 9
输出: "2314"
class Solution {
public:
string getPermutation(int n, int k) {
string ans;
string num="123456789";
vector<int>f(n, 1);
for (int i = 1; i<n;++i)
f[i]=f[i-1] * i;
--k;
for (int i = n; i >= 1; --i)
{
int j = k / f[i - 1];
k %= f[i - 1];
ans.push_back(num[j]);
num.erase(j, 1);
}
return ans;
}
};
class Solution {
public String getPermutation(int n, int k) {
int nums[]=new int[n];
for (int i = 0; i < n; i++) {
nums[i]=i+1;
}
for (int i = 0; i < k-1; i++) {
nextPermutation(nums);
}
StringBuffer sb = new StringBuffer();
for (int i : nums) {
sb.append(i);
}
return sb.toString();
}
private void nextPermutation(int[] nums) {
int j = 0, i = 0, temp = 0;
labelb: for (i = nums.length - 2; i>= 0; i--) {
for (j= nums.length - 1; j>i; j--) {
if (nums[i] < nums[j]) {
temp = nums[j];
nums[j] = nums[i];
nums[i] = temp;
break labelb;
}
}
}
Arrays.sort(nums, i+1, nums.length);
}
}
27. 朋友圈
班上有 N 名学生。其中有些人是朋友,有些则不是。他们的友谊具有是传递性。如果已知 A 是 B 的朋友,B 是 C 的朋友,那么我们可以认为 A 也是 C 的朋友。所谓的朋友圈,是指所有朋友的集合。
给定一个 N * N 的矩阵 M,表示班级中学生之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个学生互为朋友关系,否则为不知道。你必须输出所有学生中的已知的朋友圈总数。
示例 1:
输入:
[[1,1,0],
[1,1,0],
[0,0,1]]
输出: 2
说明:已知学生0和学生1互为朋友,他们在一个朋友圈。
第2个学生自己在一个朋友圈。所以返回2。
示例 2:
输入:
[[1,1,0],
[1,1,1],
[0,1,1]]
输出: 1
说明:已知学生0和学生1互为朋友,学生1和学生2互为朋友,所以学生0和学生2也是朋友,所以他们三个在一个朋友圈,返回1。
注意:
- N 在[1,200]的范围内。
- 对于所有学生,有M[i][i] = 1。
- 如果有M[i][j] = 1,则有M[j][i] = 1。
解法:https://www.cnblogs.com/jkzr/p/10594892.html
28. 合并区间
给出一个区间的集合,请合并所有重叠的区间。
示例 1:
输入: [[1,3],[2,6],[8,10],[15,18]]
输出: [[1,6],[8,10],[15,18]]
解释: 区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入: [[1,4],[4,5]]
输出: [[1,5]]
解释: 区间 [1,4] 和 [4,5] 可被视为重叠区间。
/**
* Definition for an interval.
* struct Interval {
* int start;
* int end;
* Interval() : start(0), end(0) {}
* Interval(int s, int e) : start(s), end(e) {}
* };
*/
class Solution {
public:
vector<Interval> merge(vector<Interval>& intervals) {
sort(intervals.begin(),intervals.end(),cmp);
int si=intervals.size();
if(si==1)
return intervals;
vector<Interval>ans;
int i=0;
Interval temp;
while(i<si)
{
int s=intervals[i].start,e=intervals[i].end;
int j=i+1;
while(j<si && intervals[j].start<=e)
{
if(e<intervals[j].end)
e=intervals[j].end;
j++;
}
temp.start=s;temp.end=e;
ans.push_back(temp);
i=j;
}
return ans;
}
static bool cmp(Interval a,Interval b)
{
if(a.start==b.start)
return a.end<b.end;
else
return a.start<b.start;
}
};
29. 接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
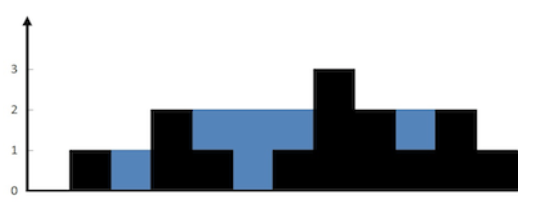

上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。 感谢 Marcos 贡献此图。
示例:
输入: [0,1,0,2,1,0,1,3,2,1,2,1]
输出: 6
class Solution {
public:
int trap(vector<int>& height) {
int n=height.size();
if(n<=2)
return 0;
int maxx=-1;int id;
for(int i=0;i<n;i++)
{
if(height[i]>maxx)
{
maxx=height[i];
id=i;
}
}
int ans=0;int t=height[0];
for(int i=0;i<id;i++)
{
if(t<height[i])
t=height[i];
else
ans+=(t-height[i]);
}
t=height[n-1];
for(int i=n-1;i>id;i--)
{
if(t<height[i])
t=height[i];
else
ans+=(t-height[i]);
}
return ans;
}
};
30. 买卖股票的最佳时机
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
如果你最多只允许完成一笔交易(即买入和卖出一支股票),设计一个算法来计算你所能获取的最大利润。
注意你不能在买入股票前卖出股票。
示例 1:
输入: [7,1,5,3,6,4]
输出: 5
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格。
示例 2:
输入: [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
解法:https://www.cnblogs.com/jkzr/p/10610073.html
31. 买卖股票的最佳时机 II
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入: [7,1,5,3,6,4]
输出: 7
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
解法:https://www.cnblogs.com/jkzr/p/10610082.html
32. 最大正方形
在一个由 0 和 1 组成的二维矩阵内,找到只包含 1 的最大正方形,并返回其面积。
示例:
输入:
1 0 1 0 0
1 0 1 1 1
1 1 1 1 1
1 0 0 1 0
输出: 4
解法:https://www.cnblogs.com/jkzr/p/10610105.html
33. 最大子序和
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
输入: [-2,1,-3,4,-1,2,1,-5,4],
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
进阶:
如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的分治法求解。
解法:https://www.cnblogs.com/jkzr/p/10610175.html
34. 三角形最小路径和
给定一个三角形,找出自顶向下的最小路径和。每一步只能移动到下一行中相邻的结点上。
例如,给定三角形:
[
[2],
[3,4],
[6,5,7],
[4,1,8,3]
]
自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
说明:
如果你可以只使用 O(n) 的额外空间(n 为三角形的总行数)来解决这个问题,那么你的算法会很加分。
解法:https://www.cnblogs.com/jkzr/p/10610187.html
35. 俄罗斯套娃信封问题
给定一些标记了宽度和高度的信封,宽度和高度以整数对形式 (w, h) 出现。当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。
请计算最多能有多少个信封能组成一组“俄罗斯套娃”信封(即可以把一个信封放到另一个信封里面)。
说明:
不允许旋转信封。
示例:
输入: envelopes = [[5,4],[6,4],[6,7],[2,3]]
输出: 3
解释: 最多信封的个数为 3, 组合为: [2,3] => [5,4] => [6,7]。
解法:
class Solution {
public:
int maxEnvelopes(vector<pair<int, int>>& envelopes) {
int res = 0, n = envelopes.size();
vector<int> dp(n, 1);
sort(envelopes.begin(), envelopes.end());
for (int i = 0; i < n; ++i) {
for (int j = 0; j < i; ++j) {
if (envelopes[i].first > envelopes[j].first && envelopes[i].second > envelopes[j].second) {
dp[i] = max(dp[i], dp[j] + 1);
}
}
res = max(res, dp[i]);
}
return res;
}
};
public static int maxEnvelopes(int[][] envelopes) {
if (envelopes == null || envelopes.length == 0)
return 0;
Arrays.sort(envelopes, new Comparator<int[]>() {
public int compare(int[] a, int[] b) {
if (a[0] != b[0]) {
return a[0] - b[0]; // ascending order
} else {
return b[1] - a[1]; // descending order
}
}
});
ArrayList<Integer> list = new ArrayList<Integer>();
//遍历每个信封,相当于决定每个信封的位置
for (int i = 0; i < envelopes.length; i++) {
if (list.size() == 0 || list.get(list.size() - 1) < envelopes[i][1]) {
list.add(envelopes[i][1]);
continue;
}
//二分替换,使得加进来的每个信封的宽在List集合中是升序排序
int l = 0;
int r = list.size() - 1;
while (l < r) {
int m = (l + r) / 2;
if (list.get(m) < envelopes[i][1]) {
l = m + 1;
} else {
r = m;
}
}
list.set(r, envelopes[i][1]);
}
return list.size();
}
36. 最小栈
设计一个支持 push,pop,top 操作,并能在常数时间内检索到最小元素的栈。
- push(x) -- 将元素 x 推入栈中。
- pop() -- 删除栈顶的元素。
- top() -- 获取栈顶元素。
- getMin() -- 检索栈中的最小元素。
示例:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.getMin(); --> 返回 -3.
minStack.pop();
minStack.top(); --> 返回 0.
minStack.getMin(); --> 返回 -2.
class MinStack {
public:
/** initialize your data structure here. */
MinStack() {}
void push(int x) {
s1.push(x);
if (s2.empty() || x <= s2.top()) s2.push(x);
}
void pop() {
if (s1.top() == s2.top()) s2.pop();
s1.pop();
}
int top() {
return s1.top();
}
int getMin() {
return s2.top();
}
private:
stack<int> s1, s2;
};
37. LRU缓存机制
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得密钥 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得密钥 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
class LRUCache {
Map<Integer,Integer> map ;
Stack<Integer> stack;
int size;
public LRUCache(int capacity) {
stack = new Stack<>();
map = new HashMap<>(capacity);
size = capacity;
}
public int get(int key) {
if(!stack.contains(key)){
return -1;
}
boolean flag = stack.remove(Integer.valueOf(key));
stack.push(key);
return map.get(key);
}
public void put(int key, int value) {
if(stack.contains(key)){
stack.remove(Integer.valueOf(key));
}else{
if(stack.size() == size){
int count = stack.remove(0);
map.remove(count);
}
}
stack.push(key);
map.put(key,value);
}
}
class LRUCache {
private:
int n;
list<pair<int,int> > lis;
unordered_map<int,list<pair<int,int>>::iterator> m;
public:
LRUCache(int capacity) {
n = capacity;
}
int get(int key) {
auto it = m.find(key);
int ans = -1;
if(it!=m.end())
{
ans = it->second->second;
lis.erase(it->second);
lis.push_front(make_pair(key,ans));
it->second = lis.begin();
}
return ans;
}
void put(int key, int value) {
auto it = m.find(key);
if(it!=m.end())
{
lis.erase(it->second);
lis.push_front(make_pair(key,value));
m[key] = lis.begin();
}
else if(m.size()<n)
{
lis.push_front(make_pair(key,value));
m[key] = lis.begin();
}
else
{
auto it = lis.end();
it--;
m.erase(it->first);
lis.erase(it);
lis.push_front(make_pair(key,value));
it = lis.begin();
m[key] = it;
}
}
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
38. x 的平方根
实现 int sqrt(int x) 函数。
计算并返回 x 的平方根,其中 x 是非负整数。
由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
示例 1:
输入: 4
输出: 2
示例 2:
输入: 8
输出: 2
说明: 8 的平方根是 2.82842...,
由于返回类型是整数,小数部分将被舍去。
我们能想到的方法就是算一个候选值的平方,然后和x比较大小,为了缩短查找时间,我们采用二分搜索法来找平方根。
class Solution {
public:
int mySqrt(int x) {
if (x <= 1) return x;
int left = 0, right = x;
while (left < right) {
int mid = left + (right - left) / 2;
if (x / mid >= mid) left = mid + 1;
else right = mid;
}
return right - 1;
}
};
39. 第二高的薪水
编写一个 SQL 查询,获取 Employee 表中第二高的薪水(Salary) 。
+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
例如上述 Employee 表,SQL查询应该返回 200 作为第二高的薪水。如果不存在第二高的薪水,那么查询应返回 null。
+---------------------+
| SecondHighestSalary |
+---------------------+
| 200 |
+---------------------+
select max(Salary) as SecondHighestSalary from Employee e1 where
(select max(Salary) from Employee e2 where e1.Salary<e2.Salary)
40. 合并两个有序链表
将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* pHead1, ListNode* pHead2) {
ListNode *pHead = new ListNode(0);
ListNode *p = pHead;
while(pHead1 != NULL && pHead2 != NULL)
{
if(pHead1->val < pHead2->val)
{
p->next = pHead1;
pHead1 = pHead1->next;
}
else
{
p->next = pHead2;
pHead2 = pHead2->next;
}
p = p->next;
}
if(pHead1 != NULL)
{
p->next = pHead1;
pHead1=pHead1->next;
p=p->next;
}
if(pHead2 != NULL)
{
p->next = pHead2;
pHead2=pHead2->next;
p=p->next;
}
return pHead->next;
}
};
41. 反转链表
反转一个单链表。
示例:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode *ans=NULL;
ListNode *pre=NULL;
ListNode *temp=head;
while(temp!=NULL)
{
ListNode *nextt=temp->next;
if(nextt==NULL)
ans=temp;
temp->next=pre;
pre=temp;
temp=nextt;
}
return ans;
}
};
42. 排序链表
在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序。
示例 1:
输入: 4->2->1->3
输出: 1->2->3->4
示例 2:
输入: -1->5->3->4->0
输出: -1->0->3->4->5
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* sortList(ListNode* head) {
if (head == NULL || head->next == NULL) {
return head;
}
return mergeSort(head);//去掉链表尾端的寻找
}
ListNode* mergeSort(ListNode* head) {
if (head == NULL || head ->next == NULL) {//这段链表只有一个节点
return head;
}
//快慢指针,定位链表中间
ListNode *slowPtr = head, *fastPtr = head->next;
while (fastPtr != NULL && fastPtr->next != NULL) {
slowPtr = slowPtr->next;//慢指针走一步
fastPtr = fastPtr->next;//快指针走两步
if (fastPtr != NULL && fastPtr->next != NULL) {
fastPtr = fastPtr->next;//快指针走两步
}
}
//第一步 递归,排序右半
ListNode * rightList = mergeSort(slowPtr->next);
slowPtr->next = NULL;//将左右两部分切开
//第二步 递归,排序左半
ListNode * leftList = mergeSort(head);
//第三步 合并
ListNode *pHead = NULL, *pEnd = NULL;//合并链表的头、尾
if (rightList == NULL) {
return leftList;
}
//初始化头结点、尾节点
if (rightList->val > leftList->val) {
pEnd = pHead = leftList;
leftList = leftList->next;
}
else {
pEnd = pHead = rightList;
rightList = rightList->next;
}
//合并,每次将较小值放入新链表
while (rightList && leftList) {
if (rightList->val > leftList->val) {
pEnd->next = leftList;
pEnd = pEnd->next;
leftList = leftList->next;
}
else {
pEnd->next = rightList;
pEnd = pEnd->next;
rightList = rightList->next;
}
}
//可能某个链表有剩余
if (rightList == NULL) {
pEnd->next = leftList;
}
else {
pEnd->next = rightList;
}
return pHead;
}
};
43. 环形链表 II
给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
说明:不允许修改给定的链表。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:tail connects to node index 1
解释:链表中有一个环,其尾部连接到第二个节点。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
if(head == nullptr)
return nullptr;
ListNode * slow = head;
ListNode * fast = head;
ListNode * temp = nullptr;
int node = 1;
while(fast -> next != nullptr){
slow = slow -> next;
fast = fast -> next;
if(fast -> next != nullptr)
fast = fast -> next;
else return nullptr;
if(slow == fast){
temp = slow;
break;
}
}
if(temp != nullptr){
slow = head;
while(slow != fast){
slow = slow -> next;
fast = fast -> next;
}
return slow;
}
else return nullptr;
}
};
44. 相交链表
编写一个程序,找到两个单链表相交的起始节点。
如下面的两个链表:

在节点 c1 开始相交。
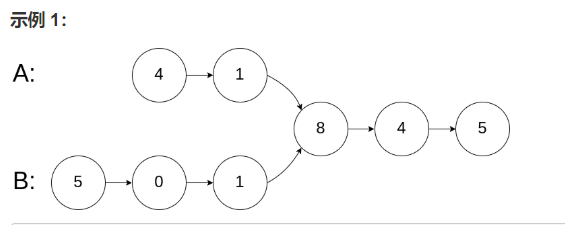
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Reference of the node with value = 8
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if(headA==NULL || headB==NULL)
return NULL;
ListNode *ans1=headA,*ans2=headB;
while(ans1!=ans2)
{
if(ans1==NULL)
ans1=headB;
else
ans1=ans1->next;
if(ans2==NULL)
ans2=headA;
else
ans2=ans2->next;
}
return ans1;
}
};
45. 合并K个排序链表
合并 k 个排序链表,返回合并后的排序链表。请分析和描述算法的复杂度。
示例:
输入:
[
1->4->5,
1->3->4,
2->6
]
输出: 1->1->2->3->4->4->5->6
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
if (lists.empty()) return NULL;
int n = lists.size();
while (n > 1) {
int k = (n + 1) / 2;
for (int i = 0; i < n / 2; ++i) {
lists[i] = mergeTwoLists(lists[i], lists[i + k]);
}
n = k;
}
return lists[0];
}
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
ListNode *dummy = new ListNode(-1), *cur = dummy;
while (l1 && l2) {
if (l1->val < l2->val) {
cur->next = l1;
l1 = l1->next;
} else {
cur->next = l2;
l2 = l2->next;
}
cur = cur->next;
}
if (l1) cur->next = l1;
if (l2) cur->next = l2;
return dummy->next;
}
};
46. 二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
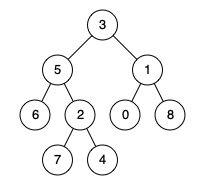
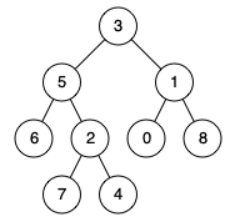
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
示例 1:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出: 3
解释: 节点 5 和节点 1 的最近公共祖先是节点 3。
示例 2:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出: 5
解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。
/*第一种情况:左子树和右子树均找没有p结点或者q结点;(这里特别需要注意,虽然题目上说了p结点和q结点必定都存在,但是递归的时候必须把所有情况都考虑进去,
因为题目给的条件是针对于整棵树,而递归会到局部,不一定都满足整体条件)
第二种情况:左子树上能找到,但是右子树上找不到,此时就应当直接返回左子树的查找结果;
第三种情况:右子树上能找到,但是左子树上找不到,此时就应当直接返回右子树的查找结果;
第四种情况:左右子树上均能找到,说明此时的p结点和q结点分居root结点两侧,此时就应当直接返回root结点*/
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(root==NULL) return root;
if(root==p||root==q) return root;
TreeNode *left=lowestCommonAncestor(root->left,p,q);
TreeNode *right=lowestCommonAncestor(root->right,p,q);
if(left!=NULL&&right!=NULL) return root;//如果p,q刚好在左右两个子树上
if(left==NULL) return right;//仅在右子树
if(right==NULL) return left;//仅在左子树
}
};
47. 二叉树的几种遍历
https://www.cnblogs.com/jkzr/p/10594783.html
48. 字符串的排列
给定两个字符串 s1 和 s2,写一个函数来判断 s2 是否包含 s1 的排列。
换句话说,第一个字符串的排列之一是第二个字符串的子串。
示例1:
输入: s1 = "ab" s2 = "eidbaooo"
输出: True
解释: s2 包含 s1 的排列之一 ("ba").
示例2:
输入: s1= "ab" s2 = "eidboaoo" 输出: False
解法可参考:https://www.cnblogs.com/jkzr/p/10622052.html
49. Java实现中文数字转阿利伯数字
/**
* @param chineseNumber
* @return
*/
@SuppressWarnings("unused")
private static int chineseNumber2Int(String chineseNumber){
int result = 0;
int temp = 1;//存放一个单位的数字如:十万
int count = 0;//判断是否有chArr
char[] cnArr = new char[]{'一','二','三','四','五','六','七','八','九'};
char[] chArr = new char[]{'十','百','千','万','亿'};
for (int i = 0; i < chineseNumber.length(); i++) {
boolean b = true;//判断是否是chArr
char c = chineseNumber.charAt(i);
for (int j = 0; j < cnArr.length; j++) {//非单位,即数字
if (c == cnArr[j]) {
if(0 != count){//添加下一个单位之前,先把上一个单位值添加到结果中
result += temp;
temp = 1;
count = 0;
}
// 下标+1,就是对应的值
temp = j + 1;
b = false;
break;
}
}
if(b){//单位{'十','百','千','万','亿'}
for (int j = 0; j < chArr.length; j++) {
if (c == chArr[j]) {
switch (j) {
case 0:
temp *= 10;
break;
case 1:
temp *= 100;
break;
case 2:
temp *= 1000;
break;
case 3:
temp *= 10000;
break;
case 4:
temp *= 100000000;
break;
default:
break;
}
count++;
}
}
}
if (i == chineseNumber.length() - 1) {//遍历到最后一个字符
result += temp;
}
}
return result;
}
数字转中文
import java.io.Console;
import java.util.*;
public class FirstExample {
static String[] units = { "", "十", "百", "千", "万", "十万", "百万", "千万", "亿",
"十亿", "百亿", "千亿", "万亿" };
static char[] numArray = { '零', '一', '二', '三', '四', '五', '六', '七', '八', '九' };
public static void main(String[] args) {
int num = 233200040;
String numStr = foematInteger(num);
System.out.println("num= " + num + ", 转换结果: " + numStr);
}
private static String foematInteger(int num) {
char[] val = String.valueOf(num).toCharArray();
int len = val.length;
System.out.println("----" + len);
StringBuilder sb = new StringBuilder();
for (int i = 0; i < len; i++) {
String m = val[i] + "";
int n = Integer.valueOf(m);
boolean isZero = n == 0;
String unit = units[(len - 1) - i];
if (isZero) {
if ('0' == val[i - 1]) {
//当前val[i]的下一个值val[i-1]为0则不输出零
continue;
} else {
//只有当当前val[i]的下一个值val[i-1]不为0才输出零
sb.append(numArray[n]);
}
} else {
sb.append(numArray[n]);
sb.append(unit);
}
}
return sb.toString();
}
}
50. 二叉树中和为某一值的路径
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
vector<vector<int>> result;
vector<int> elem;
void dfs(TreeNode* root, int expectNumber){
elem.push_back(root->val);
if(root->val==expectNumber && root->left==NULL && root->right==NULL){//到达了叶子节点且从根节点到叶子节点的和等于整数
result.push_back(elem);
}else{ //否则如果不是叶子节点,继续dfs
if(root->left)
dfs(root->left, expectNumber-root->val);
if(root->right)
dfs(root->right, expectNumber-root->val);
}//如果是叶子节点,但是从根节点到叶子节点的和不等于expectNumber,则元素退栈,进行另一路径的判断
elem.pop_back();
}
vector<vector<int> > FindPath(TreeNode* root,int expectNumber) {
if(root)
dfs(root, expectNumber);
return result;
}
};
51. 在二叉搜索树查找第k大的结点
public static int KthSmallest(TreeNode root, int k)
{
Stack<TreeNode> s = new Stack<TreeNode>();
TreeNode p = root;
while (s.Count > 0 || p != null)
{
if (p != null)
{
s.Push(p);
p = p.Left;
}
else
{
p = s.Pop();
--k;
if (k == 0)
{
return p.value;
}
p = p.Right;
}
}
return -1;
}
52. 求数组中区间中最小数*区间所有数和的最大值
public class test {
public static int function(int[] arr) {
int len = arr.length;
int[] sum = new int[len];
int ans = 0;
for (int i = 0; i < len; i++) {
//右边界
sum[i] = arr[i];
for (int j = i+1; j < len; j++) {
if (arr[j] >= arr[i]) {
sum[i] += arr[j];
} else {
break;
}
}
//左边界
for (int j = i-1; j >= 0;j--) {
if (arr[j] >= arr[i]) {
sum[i] += arr[j];
} else {
break;
}
}
ans = Math.max(ans,sum[i]*arr[i]);
}
return ans;
}
}
import java.util.Scanner;
public class MaxRange {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
int arr[] = new int[n];
for (int i = 0; i < n; i++) {
arr[i] = in.nextInt();
}
in.close();
System.out.println(getMax(arr, 0, n - 1));
}
private static int getMax(int[] arr, int start, int end) {
if (arr == null || start > end) {
return 0;
}
int n = end - start + 1;
int[][] min = new int[n + 1][n + 1];
int[] sum = new int[n + 1];
sum[0] = 0;
// sum[i]即从第一个数加到第i个数的和,也就是arr[0]+...+arr[i-1]
for (int i = start + 1; i <= end + 1; i++) {
sum[i - start] = sum[i - start - 1] + arr[i - start - 1];
}
int max = -1;
for (int k = 0; k <= end - start; k++)
// 左右下标的差,k==0时,区间内有1个数
for (int i = 0; i <= end - start - k; i++) {
int j = i + k;
if (k == 0) {
min[i][j] = arr[i];
} else {
if (arr[j] < min[i][j - 1]) {
min[i][j] = arr[j];
} else {
min[i][j] = min[i][j - 1];
}
}
max = Math.max(max, min[i][j] * (sum[j + 1] - sum[i]));
}
return max;
}
}
53. 矩阵中的最长递增路径
class Solution {
private int[] row = {-1,1,0,0};
private int[] col = {0,0,-1,1};
public int longestIncreasingPath(int[][] matrix) {
if(matrix.length ==0 || matrix[0].length == 0)
return 0;
boolean[][] visited = new boolean[matrix.length][matrix[0].length];
int[][] len = new int[matrix.length][matrix[0].length];
int max = 0;
for(int i=0;i<matrix.length;i++){
for(int j=0;j<matrix[0].length;j++){
max = Math.max(max,find(matrix,visited,len,i,j));
}
}
return max;
}
private int find(int[][] matrix,boolean[][] visited,int[][] len,int x,int y){
if(visited[x][y])
return len[x][y];
len[x][y] = 1;
for(int i=0;i<4;i++){
int curX = x + row[i];
int curY = y + col[i];
if(curX >=0 && curX < matrix.length && curY >=0 && curY<matrix[0].length && matrix[curX][curY] < matrix[x][y]){
len[x][y] = Math.max(len[x][y],find(matrix,visited,len,curX,curY)+1);
}
}
visited[x][y] = true;
return len[x][y];
}
}















 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









