






1 前提
梦中惊坐起,我还有个公众号,那就更新一下吧。
今天分享的是Levenshtein Distance(以下简称LD),中文叫莱文斯坦距离。他是干什么的呢?
2 遇见的问题
判断两个字符串是否相等:
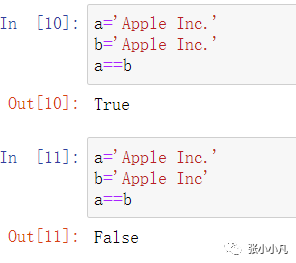 只少了一个点,结果变为False,那么这两个字符串的相似度是多少呢?就用到了
只少了一个点,结果变为False,那么这两个字符串的相似度是多少呢?就用到了Levenshtein Distance
3 公式介绍
Levenshtein Distance指两个字串之间,由一个转换成另一个所需的最少编辑操作次数,允许的编辑操作包括:
- 替换成另一个字符(Substitutions)
- 插入一个字符(Insertions)
- 删除一个字符(Deletions)
公式:

这个数学公式最终得出的数值就是LD的值。举个例子:
将kitten这个单词转成sitting的LD值为3:每个转换的代价都是1
kitten → sitten (k→s)
sitten → sittin (e→i)
sittin → sitting (insert a 'g')
4 计算
可以用一个二维数组动态规划来计算LD。(动态规划相对于递归的好处大家都懂得!)
举例(两个非等长字符串):doge和dog。首先初始化一个4X3的矩阵:
 然后根据公式往里面填数,最后结果为:
然后根据公式往里面填数,最后结果为:
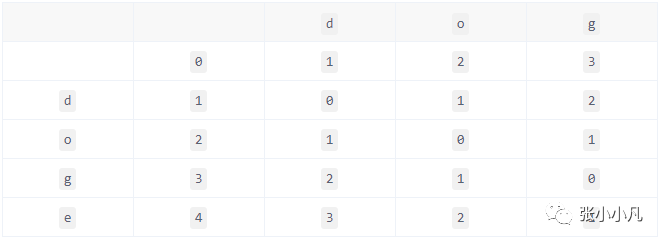 可以得知LD=1
可以得知LD=1
5 代码实现
import numpy as np
# 找最小编辑距离
def lev_distance(source,target):
source=source.upper()
target=target.upper()
rows=len(source)
columns=len(target)
np.zeros((rows+1,columns+1))
arr=np.zeros((rows+1,columns+1))
for i in range(1,rows+1):
for j in range(1,columns+1):
arr[i][0]=i
arr[0][j]=j
for i in range(1,rows+1):
for j in range(1,columns+1):
if target[j-1]==source[i-1]:
cost=0
else:
cost=1
arr[i,j]=min(arr[i-1,j]+1,arr[i,j-1]+1,arr[i-1,j-1]+cost)
return arr[i,j]
# 计算匹配度
def lev_rate(source,target):
distance=lev_distance(source,target)
rate=1-distance/max(len(source),len(target))
return rate
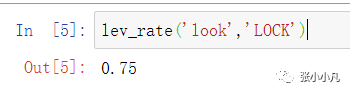
测试:
6 使用场景
- 字符串匹配
- DNA分析
- 论文查重
- 脱敏数据和明文数据匹配
例子:脱敏数据
| name | phone | id_number |
|---|---|---|
| 张*凡 | 123****89 | 130123213****5555 |
真实数据:
| name | phone | id_number |
|---|---|---|
| 张小凡 | 123456789 | 130123213xxxx5555 |
满足LD(name)=1 && LD(phone)=4 && LD(id_number)=4条件,可以进行脱敏和明文数据的匹配。

转载美三代 点赞富一生














 2293
2293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









