







数据库概念
关系型数据库
关系数据库提供了一个通用接口,使用户可以使用使用 编写的命令或查询从数据库读取和写入数据。
关系数据库由一个或多个表格组成,表格由与电子表格相似的列和行组成。
以行列形式存储数据,行包含一个条目的所有信息,列是分离不同数据点的属性
架构固定,输入数据前要先锁定列
查询方式是SQL语句
支持垂直扩展属性
每一张表都有主键, 通过引用记录的主键,表中的一条记录可以与另一个表中的记录相关。这个指针或引用被称为外键。
关系数据库可以分为联机事务处理OLTP 和 联机分析处理OLAP,具体取决于表的组织方式以及应用程序如何使用关系数据库。
OLTP - 经常编写和更改数据(例如数据输入和 电子商务)的面向事务的应用程序,OLTP事务频繁发生但相对简单
OLAP - 应用于数据仓库的领域,指的是报告或分析大型数据集。OLAP事务 的发生频率要低得多,但要复杂得多
大型应用程序经常混合使用OLTP和OLAP数据库。一个数据库作为其OLTP事务的主生产 数据库,另一个数据库作为他们的数据仓库为OLAP。
数据库包括: MySQL,PostgreSQL,Microsoft SQL Server和Oracle
SQL 数据库的默认端口
Oracle: 1521
MS SQL : 1433
MySQL : 3306
DB2: 5000
数据仓库
数据仓库为可以来自一个或多个源的数据的中央储存库。
此数据存储库通常是专用类型的关系数据库,可用于通过OLAP进行报告和分析,组织通常使用数据仓库来编译报告并使用高度复杂 的查询搜索数据库。
NoSQL数据库
相比关系型数据库,NoSQL更加简单易用,更加灵活,
传统数据库在单台服务器外扩展成本极高,而NoSQL可以在商用硬件上实现水平伸缩性
使用众多模型(如键值对、文档和图表)中的一种来存储数据
数据结构
集合 Collection : 相当于表
文档 Document: 相当于行
键值 Key Value Pairs: 相当于列
动态的架构,行无需包含与每个列对应的数据
查询更关注文档集合
支持水平扩展属性
NoSQL的其他特性
对于某些应用程序可以替代关系型数据库
支持以高可用性处理大量数据
可以形成一个包含不同实施方案和数据模型的大类别
具备分布式容错的能力
NoSQL 可以提高灵活性、可用性、扩展性和高性能
主要的NoSQL数据库包括
EC2: Cassandra、Hbase、Redis、MongoDB、Couchbase、Riak
AWS托管:DynamoDB、ElastiCache(Redis)、Elastic Map Reduce(HBase)
NoSQL 数据库常用端口
MongoDB:27017
Redis:6379
Memcached:11211
采用NoSQL主要考虑几个限制
应用程序的事务支持
ACID合规(ACID=原子性、一致性、隔离性和持久性)
联接需求
SQL需求
常见场景:
排行榜、快速导入点击流或日志数据、购物车临时数据需求、热表、元数据或查找表、会话数据
数据库选择
将非关系型数据放在NoSQL中(如DynamoDB)
将技术与工作负载匹配,从各种关系型数据库, NoSQL数据库,数据仓库和其他针对搜索优化的数据存储中选择。
数据库选择要考虑的事项:
读取和写入要求
总存储容量
典型对象大小及其访问特性
持久性需求
延迟要求
同时支持的最大用户量
查询特性
所需完整性控制强度
Amazon RDS存储关系型数据
RDS综述
RDS是一个全托管的数据库
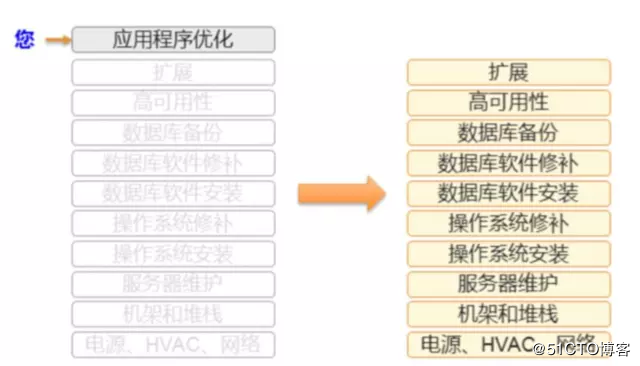
开发人员可以专注于查询结构和查询优化
减轻运维负担包括数据库迁移、备份和恢复、修补、软件升级、存储升级、频繁服务器升级、硬件故障处理
RDS可以通过公用的客户端软件连接并执行SQL操作,包括使用相同的工具来查询,分析,修改和管理数据库。例如,当前的提取,转换, 加载(ETL)工具和报告工具
RDS 数据库实例
数据库实例是云上专用网段中部署的隔离的数据库环境
每个实例运行了一个商业或者开源的数据库引擎,包括MySQL,PostgreSQL,MS SQL,Oracle,MariaDB以及AWS Aurora 六种。
可以通过API创建和管理RDS实例
可以利用AWS工具或者数据库引擎本身的工具将数据从本地迁移到AWS上
每个用户默认最多托管40个RDS数据库
每个实例上只能运行1个Oracle和30个MS SQL数据库,其余没有限制
RDS支持预留实例,且只支持区域预留,可用于多可用区部署和只读副本
使用Parameter Group 对数据库参数进行设置
存储选项
RDS构建在EBS上
通过预配置支持最大16TB (MSSQL) - 32TB,32000 IOPS - 40000 IOPS
支持HDD,通用SSD和预配置IOPS SSD 三种类型
备份与恢复
自动备份
备份存储在S3中
RDS备份整个数据库实例,为它创建存储卷快照
自动备份建期间IO会挂起3-5秒钟,但对高可用部署的数据库不受影响
自动备份默认开启且保留1天(API或CLI创建)或者7天(控制台创建),最大可保留35天,自动删除
自动备份支持时间点恢复功能,最小间隔为5分钟
删除实例时所有自动备份都会被删除
可以
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 832
832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









