






4.3 应用服务器性能优化
应用服务器就是处理网站业务的服务器,网站的业务代码都部署在这里,是网站开发最复杂,变化最多的地方,优化手段主要有缓存、集群、异步等。
4.3.1 分布式缓存
网站性能优化第一定律:优先考虑使用缓存优化性能。
1、缓存的基本原理
缓存速度快,减少访问时间
缓存的数据是经过计算得到的,减少计算的时间
哈希取余数据长度
一致性哈希算法
缓存主要用来存放那些读写比很高、很少变化的数据
如商品的类目信息,热门词的搜索列表信息,热门商品信息等。
网站数据,80%的访问落在20%的数据上,因此利用Hash表和内存的告诉访问特性,将这20%的数据缓存起来,可很好地改善系统性能,提高数据读取数据,降低存储访问压力。
2、合理使用缓存
缓存滥用:过分依赖低可用的缓存系统,不恰当地使用缓存的数据访问特性等。
频繁修改的数据
数据读写比至少在2:1以上,缓存才有意义。
写入一次缓存,在数据更新前至少读取两次。
数据不一致与脏读
先更新数据,再删除缓存
缓存可用性
缓存承担系统大部分压力时,缓存的大量失效会导致,访问全部落到数据库,造成数据库宕机,乃至整个系统不可用,这种情况称为缓存雪崩。
缓存热备是一种方案,但是缓存根本就不该被当做一个可靠的数据源来使用。
通过分布式缓存服务器集群,将缓存数据分布到集群多台服务器上可在一定程度上改善缓存的可用性。
当一台缓存服务器宕机的时候,只有部分缓存数据失效,重新从数据库加载这部分数据不会对数据库产生很大影响。
产品在设计之初就需要一个明确的定位:什么是产品要实现的功能,什么不是产品提供的特性。
在产品漫长的生命周期中,会有形形色色的困难和诱惑来改变产品的发展方向,左右摇摆、什么都想做的产品,最后有可能成为一个失去生命力的四不像。
缓存预热
缓存中存放的是热点数据,热点数据又是缓存系统利用LRU对不断访问的数据筛选淘汰出来的,这个过程需要花费较长的时间。
新启动的系统,需要缓存预热,加载热点数据。
对于一些元数据如城市列表、类目信息,可以在启动时加载数据库中全部数据到缓存进行预热。
缓存穿透
如果因为不恰当的业务、或者恶意攻击持续高并发地请求某个不存在的数据,由于缓存没有保存该数据,所有的请求都会落到数据库上,会对数据库造成很大压力,甚至崩溃。一个简单的对策是将不存在的数据也缓存起来(其value值为null)
3、分布式缓存架构
分布式缓存指缓存部署在多个服务器组成的集群中,以集群方式提供缓存服务,有两种架构:
JBoss Cache:需要更新同步的分布式缓存,不算真正的分布式,只能算法是集群热备。所有服务器保存相同的缓存数据,当某台服务器有缓存数据更新的时候,会通知集群中其他机器更新缓存数据或清除缓存数据。
缓存的数据受限于单一服务器的内存空间,不具有伸缩性。可以联系前面的软件架构要素分析。
缓存的数据量很大时,这种架构无法应对。
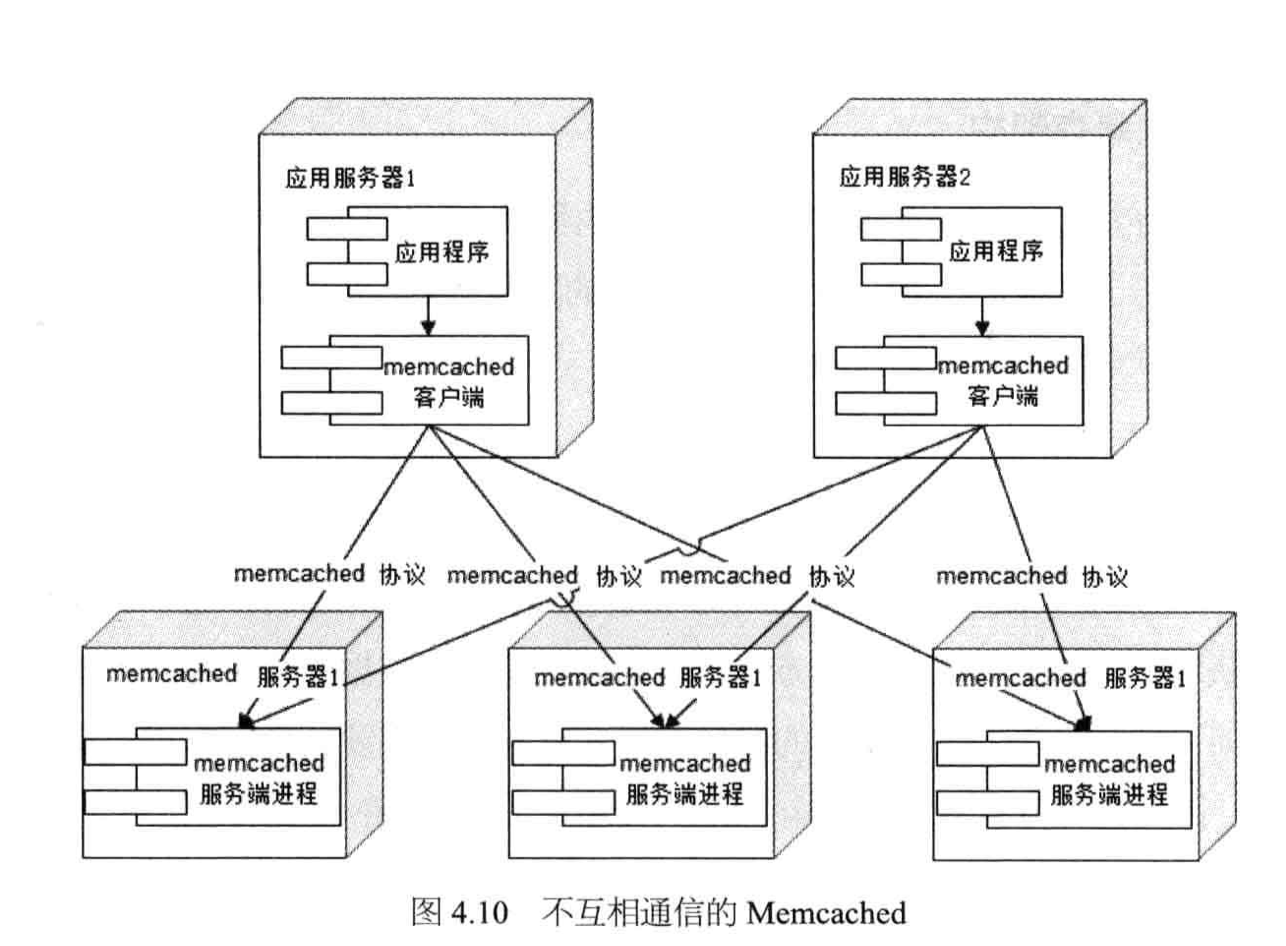
Memcached采用一种集中式的缓存集群管理,也被称为互不通信的分布式架构方式。
缓存和应用分离部署,应用程序通过一致性Hash等路由算法选择缓存服务器远程访问缓存数据,缓存服务器之间不通信,缓存集群的规模可以很容易地实现扩容,具有良好的可伸缩性。
4、Memcached
简单的通信协议
远程通信需要考虑两方面要素:
1、通信协议:TCP/UDP/HTTP
2、序列化协议:数据传输的两端,必须使用彼此可是别的数据序列化方式才能使通信得以完成,如XML、JSON等文本序列化协议,或者Google Protobuffer等二进制序列化协议。
Memcached使用TCP协议(UDP也支持)通信,其序列化协议则是一套基于文本的自定义协议,非常简单,以一个命令关键字开头,后面是一组命令操作数。例如读取一个数据的命令协议是get<key>。
丰富的客户端程序
高性能的网络通信,Memcached服务端通信模块基于Libevent,一个支持异步非阻塞,支持事件触发的网络通信库。稳定的长连接特性。
高效的内存管理
内存碎片化管理比较难,常用的方法比如压缩、复制等。
Memcached使用的是固定空间分配。
Memcached将内存空间分为一组slab,每个slab里又包含一组chunk,同一个slab里每个chunk的大小是固定的,拥有相同大小chunk的slab被组织在一起,叫做slab_class。
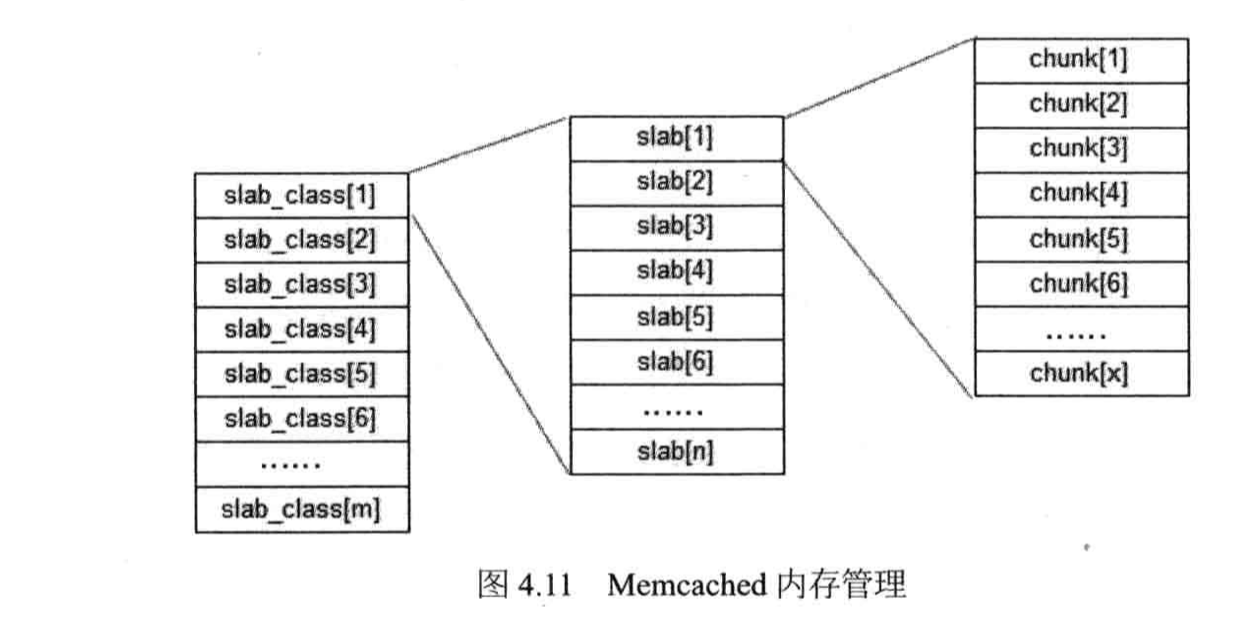
存储数据时,根据数据的Size大小,寻找一个大于Size的最小chunk将数据写入。
这种内存管理方式避免了内存碎片管理的问题,内存的分配和释放都是以chunk为单位的。
Memcached采用LRU算法释放最近最久未被访问的数据占用的空间,释放的chunk被标记为未用,等待下一个合适大小数据的写入。
这种方式会带来内存浪费的问题,即数据只能存入一个比它大的chunk里,而一个chunk只能存一个数据,其他空间被浪费了。
启动参数配置不合理,浪费会更加惊人,发现没有缓存多少数据,内存空间就用尽了。
互不通信的服务器集群架构
一致性哈希算法路由成为数据存储伸缩性架构设计的经典范式。
集群内服务器互不通信使得集群可以做到几乎无限制的线性伸缩。
4.3.2 异步操作
使用子消息队列将调用异步化,可改善网站的扩展性。还可以改善网站系统的性能。
使用消息队列后,用户请求的数据发送给消息队列后立即返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库。
由于消息队列服务器处理速度远快于数据库(消息队列服务器也比数据库具有更好的伸缩性),因此用户的响应延迟可得到有效改善。
消息队列具有很好的削峰作用——即通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期并发事务。
电商业务促销活动中,合理使用消息队列,可有效抵御促销活动刚开始大量涌入的订单对系统造成的冲击。

需要注意的是,由于数据写入消息队列后立即返回给用户,数据在后续的业务校验、写数据库等操作可能失败,因此在使用消息队列进行业务异步处理后,需要适当修改业务流程进行配合,如订单提交后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单,甚至商品出库后,再通过电子邮件或SMS消息通知用户订单成功,以免交易纠纷。
任何可以晚点做的事情都应该晚点再做。
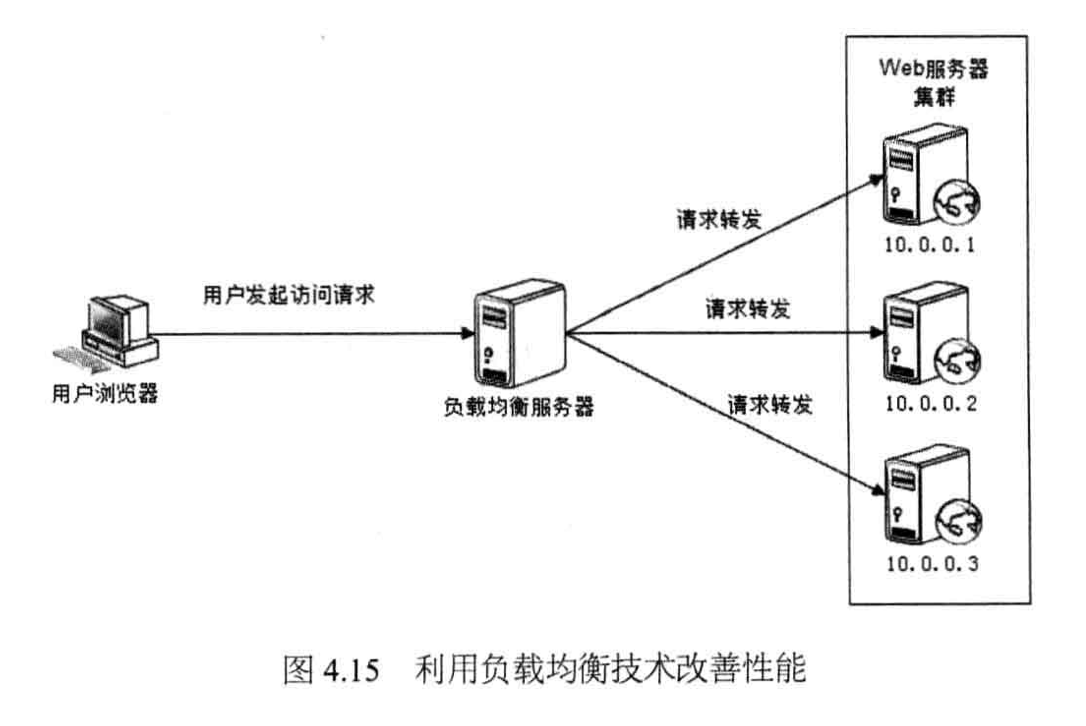
4.3.3 使用集群
使用负载均衡技术为一个应用构建一个由多台服务器组成的服务器集群,将并发请求分发到多台服务器上处理,避免单一服务器因负载压力过大而响应缓慢,使用户请求具有更好的响应延迟特性
4.3.4 代码优化
1、多线程
从资源利用角度,使用多线程的原因主要有两个:IO阻塞与多CPU。
当前线程处理IO的时候,会被阻塞释放CPU以等待IO操作完成,由于IO操作需要时间较长,这时CPU可以调度其他线程进行处理。
另:使用现代操作系统提供的诸如epoll等系统调用,可以实现异步非阻塞IO,可以同时处理更多的IO请求
多CPU时代充分利用系统CPU资源
![]()
最佳启动线程数和CPU内核数量成正比,和IO阻塞时间成反比。
如果任务都是CPU计算型任务,那么线程数最多不超过CPU核数;
如果是IO密集型任务,等待磁盘操作,网络响应,那么多启动线程有助于提高任务并发度,提高系统吞吐能力,改善系统性能。
多线程编程需要注意线程安全问题,即多线程并发对某个资源进行修改,导致数据混乱。
对网站而言,不管有没有进行多线程编程,工程师写的每一行代码都会被多线程执行,因为用户请求是并发提交的,也就是说,所有的资源——对象、内存、文件、数据库,乃至另一个线程都可能被多线程并发访问。
编程上,解决线程安全的主要手段有如下几点:
将对象设计为无状态对象:
无状态是指对象本身不存储状态信息(对象无成员变量,或者成员变量也是无状态对象),这样多线程并发访问的时候就不会出现状态不一致,Java Web开发中常用的Servlet对象就设计为无状态对象,可以被应用服务器多线程并发调用处理用户请求。
而Web开发中常用的贫血模型对象都是些无状态对象。不过从面向对象设计的角度看,无状态对象是一种不良设计。
使用局部对象(使用局部变量,线程本地变量ThreadLocal)
方法内部创建的对象的生命周期是随着方法的进入退出,方法是线程线程私有的,除非对象在方法内部创建后,被有意识的传递给其他线程,否则不会出现对象被多线程并发访问的情形。
并发访问资源时使用锁
使用锁将并发操作转化为顺序操作,从而避免资源被并发修改。锁导致线程同步顺序执行,可能会对系统性能产生严重影响。
2、资源复用
系统运行时,要尽量减少那些开销很大的系统资源的创建和销毁,比如数据库连接、网络通信连接、线程、复杂对象等。从编程角度,资源复用主要有两种模式:单例和对象池。
单例模式:
Spring的单例
对象池模式通过复用对象实例,减少对象创建和资源消耗。
数据库连接池对象
线程池对象
池管理方式:
3、数据结构
在不同场景中合理使用恰当的数据结构,灵活组合各种数据结构改善数据读写和计算特性可极大优化程序的性能。
什么场景使用什么数据结构,优化了哪些方面呢?上面这句话是捕捉不到这些信息的。
举个例子:缓存使用的数据结构是hash表,hash表的读写性能依赖HashCode的随机性,越随机冲突越少,读写性能越高。
time33算法+md5
4、垃圾回收
为什么要理解GC和调优?
因为Java Web应用运行在JVM等具有垃圾回收功能的环境中,垃圾回收对系统的性能产生巨大影响。理解垃圾回收机制有助于程序优化和参数调优,以及编写内存安全的代码。
JVM将内存划分为堆和栈。
栈用于存储线程上下文信息,如方法参数、局部变量
堆存储对象,对象的创建、释放垃圾收集都在堆上进行。
JVM的垃圾收集是分代收集,堆空间分为年轻代和老年代,年轻代分为Eden区、From区和To区。
对象创建都在Eden区,当Eden区满,就触发一次YGC,将还被使用的对象复制到From区,回收Eden区。
当Eden区再满了,再次触发YGC,将Eden区和From区还在被使用的对象复制到To区,下一次YGC则是将Eden区和To区还被使用的对象复制到From区。
经过多次YGC,某些对象会在From区和To区复制多次,如果超过某个阈值还未被释放,则将该对象复制到老年代。
如果老年代用完,就会触发Full GC,即所谓的全量回收,全量回收会对整个系统产生较大影响,因为应根据系统业务特点和对象生命周期,合理设置年轻代和老年代的大小,尽量减少Full GC。














 4587
4587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









