






Coherent Comment Generation for Chinese Articles with a Graph-to-Sequence Model
摘要
自动文章评论有助于鼓励用户参与和在线新闻平台上的互动。然而,对于传统的基于encoder-decoder的模型来说,新闻文档通常太长,这往往会导致一般性和不相关的评论。在本文中,我们提出使用一个Graph-to-Sequence的模型来生成评论,该模型将输入的新闻建模为一个主题交互图。通过将文章组织成图结构,我们的模型可以更好地理解文章的内部结构和主题之间的联系,这使得它能够更好地理解故事。我们从中国流行的在线新闻平台Tencent Kuaibao上收集并发布了一个大规模的新闻评论语料库。广泛的实验结果表明,与几个强大的baseline模型相比,我们的模型可以产生更多的连贯性和信息丰富性的评论。
关系提取方法
三元组提取
case1: 无监督。需要领域专家知识手工编写规则、模式,例如用“A work for B”来描述雇佣关系,然后将这样的规则、模式应用入句子,来挖掘出具体的三元组。
case2: 半监督。人工给出种子实例(Seed instances),例如”(John,HuaWei),(Alice,Apple)“。然后交给机器,学习出这类种子实例中所包含的模式 (Pattern) ——“A work for B”,接着利用该模式挖掘新的符合该模式的实例,再将这些新的实例加入种子实例中。所以,上述过程是一个bootstrap的过程。在这个过程中,还可以引入人工互动。例如对机器学习到的模式,可以进行人工的筛选。对新学习到的三元组实例可以标注正负例。
case3: 无监督。将句子中符合一定语法规则的动词作为关系,将该动词左右的名词作为实体。更多抽取方法
详见这里,一些关于关系抽取的具体实现。
图形序列模型
在本节中,我们将介绍所提出的图形序列模型(如图1所示)。我们的模型遵循编码器 - 解码器框架。编码器必须将作为交互图表呈现的文章文本编码成一组隐藏向量,解码器基于该隐藏向量生成评论序列。
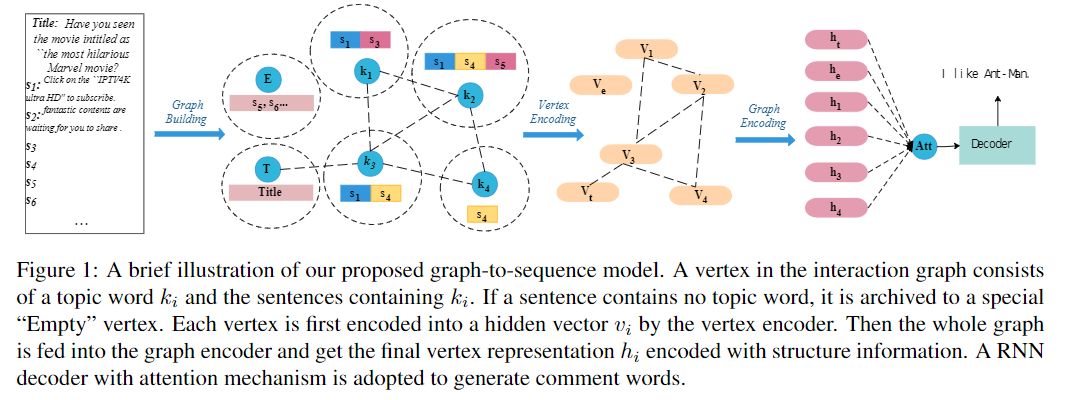
图形构造
首先,我们提取作为新闻主题的文章的关键词。这些关键词是理解文章故事的最重要的词汇,其中大部分都是命名实体。由于关键字检测不是本文的重点,因此我们不会详细介绍提取过程。
对于新闻文章D,我们首先使用Stanford CoreNLP等现成的工具对新闻文章进行分词和命名实体识别。由于单独的命名实体可能不足以涵盖文档的主要焦点,我们进一步应用TextRank等关键字提取算法来获取其他关键字。
在我们得到新闻的关键字κ之后,我们将文档的每个句子与其对应的关键词相关联。我们采用一种简单的策略,如果k出现在句子中,则将句子s分配给关键字k。请注意,一个句子可以与多个关键字相关联,这隐含地表示两个主题之间的关联。不包含任何关键字的句子被放入一个名为“Empty”的特殊顶点。因为文章的标题对理解新闻至关重要,所以我们还添加了一个名为“Title”的特殊顶点,其中包含文章的标题句子。
如果顶点\(v_i\)和\(v_j\)共享至少一个句子,我们在它们之间添加边缘\(e_ij\),其权重由共享句子的数量计算。这种设计背后的直觉是,将两个关键词组合在一起的句子越多,这两个关键词越接近。还可以使用基于内容的方法,例如\(v_i\)和\(v_j\)的内容之间的tf-idf相似性。
顶点编码器
为了将图中的每个顶点编码为一个隐藏向量v,我们建议使用基于顶点编码器的多头自注意。顶点编码器由两个模块组成,第一个是嵌入模块,第二个是自注意模块。对于单词序列中的第i个单词\(w_i\),我们首先查找单词\(e_i\)的单词嵌入。请注意,文章中的关键字和常规字共享相同的嵌入表。“常规词”是指关键词以外的词。为了表示每个单词的位置信息,将位置嵌入\(p_i\)添加到单词中。顶点的关键字k放在单词序列的前面。因此,所有插入的关键字的位置嵌入共享相同的嵌入\(p_0\),这表示关键字的特殊作用。单词嵌入和位置嵌入都被设置为可学习的向量。字\(w_i\)的最终嵌入\(ε_i\)是原始字嵌入\(e_i\)和位置嵌入\(p_i\)的总和,然后我们将\(ε_i\)提供给自我关注模块并获取每个单词的隐藏向量\(a_i\)。该模块用于对单词之间的交互进行建模,以使该层中的每个隐藏向量包含顶点的上下文信息。自我关注模块包含多层多头自我关注。图编码器
在我们得到图中每个顶点的隐藏向量之后,我们将它们提供给图形编码器以利用构造的主题交互图的图结构。我们建议使用基于谱的图卷积模型(GCN)。谱方法与图的谱表示一起工作。我们选择这种架构是因为GCN既可以对顶点的内容进行建模,也可以利用图的结构信息。由于新闻标题仍然是重要信息,我们使用图编码器的标题顶点的隐藏输出作为解码器的初始状态\(t_0\)。还可以使用其他池化方法,例如最大池化或平均池化。解码器
对于解码器,我们采用具有注意机制的递归神经网络(RNN)解码器。给定初始状态\(t_0\)和GCN(\(g_0,g_1,...,g_n\)) 的输出,解码器必然会生成一系列注释令牌\(y_1,y_2,...,y_m\)。在每个解码步骤,通过关注GCN的输出来计算上下文向量\(c_i\),由于主题词(顶点的名称)κ是文章的重要信息并且可能出现在评论中,我们通过将预测的单词标记概率分布与注意分布合并来采用复制机制。从主题词复制的概率是用解码隐藏状态\(t_i\)和上下文向量\(c_i\)动态计算的。















 4619
4619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









