






在开始介绍之前,先了解贝叶斯理论知识
https://www.cnblogs.com/zhoulujun/p/8893393.html
简单来说就是:贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
那么既然是朴素贝叶斯分类算法,它的核心算法又是什么呢?
贝叶斯公式如下:
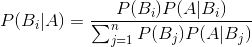
P(A|B)=P(B|A)P(A)/P(B)
可以概括为:

完整的代码如下:
#!/usr/bin/python # -*- coding: utf-8 -*- ######################################### # Bayes : 用来描述两个条件概率之间的关系 # 参数: inX: vector to compare to existing dataset (1xN) # dataSet: size m data set of known vectors (NxM) # labels: data set labels (1xM vector) # 公式:P(A|B)=P(B|A)P(A)/P(B) # 输出: 出错率 ######################################### import numpy as npy import os import time #P(B|A)=P(A|B)*P(A)/P(B) # 数据集目录 dataSetDir ='E:/digits/' class Bayes: def __init__(self): self.length=-1 self.labelrate=dict() self.vectorrate=dict() def fit(self,dataset:list,labels:list): print("训练开始") if len(dataset)!=len(labels): raise ValueError("输入测试数组和类别数组长度不一致") self.length=len(dataset[0])#训练数据特征值的长度 labelsnum=len(labels) #类别的数量 norlabels=set(labels) #不重复类别的数量 for item in norlabels: self.labelrate[item]=labels.count(item)/labelsnum #求当前类别占总类别的比例 for vector,label in zip(dataset,labels): if label not in self.vectorrate: self.vectorrate[label]=[] self.vectorrate[label].append(vector) print("训练结束") return self def btest(self,testdata,labelset): if self.length==-1: raise ValueError("未开始训练,先训练") #计算testdata分别为各个类别的概率 lbDict=dict() for thislb in labelset: p = 1 alllabel = self.labelrate[thislb] allvector = self.vectorrate[thislb] vnum=len(allvector) allvector=npy.array(allvector).T for index in range(0,len(testdata)): vector=list(allvector[index]) p*=vector.count(testdata[index])/vnum lbDict[thislb]=p * alllabel thislbabel=sorted(lbDict,key=lambda x:lbDict[x],reverse=True)[0] return thislbabel #加载数据 def datatoarray(fname): arr=[] fh=open(fname) for i in range(0,32): thisline=fh.readline() for j in range(0 , 32): arr.append(int(thisline[j])) return arr #建立一个函数取出labels def seplabel(fname): filestr=fname.split(".")[0] label=int(filestr.split("_")[0]) return label #建立训练数据 def traindata(): labels=[] trainfile=os.listdir(dataSetDir+"trainingDigits") # 加载测试数据 num=len(trainfile) trainarr=npy.zeros((num,1024)) for i in range(num): thisfname=trainfile[i] thislabel=seplabel(thisfname) labels.append(thislabel) trainarr[i,]=datatoarray(dataSetDir+"trainingDigits/"+thisfname) return trainarr,labels # 贝叶斯算法手写识别主流程 bys=Bayes() start = time.time() # # step 1: 训练数据集 train_data,labels=traindata() train_data=list(train_data) bys.fit(train_data,labels) # # step 2:测试数据集 thisdata=datatoarray(dataSetDir+"testDigits/8_90.txt") labelsall=[0,1,2,3,4,5,6,7,8,9] # # 识别单个手写体数字 # test=bys.btest(thisdata,labelsall) # print(test) # # 识别多个手写体数字(批量处理),并输出结果 testfile=os.listdir(dataSetDir+"testDigits") num=len(testfile) x=0 for i in range(num): thisfilename=testfile[i] thislabel=seplabel(thisfilename) thisdataarr=datatoarray(dataSetDir+"testDigits/"+thisfilename) label=bys.btest(thisdataarr,labelsall) print("测试数字是:"+str(thislabel)+" 识别出来的数字是:"+str(label)) if label!=thislabel: x+=1 print("识别出错") print(x) print("出错率:"+str(x/num)) end = time.time() running_time = end-start print('程序运行总耗时: %.5f sec' %running_time)
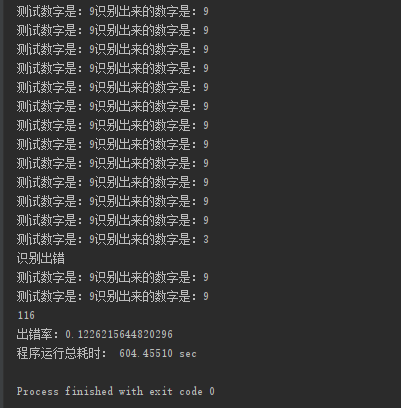
最后运行的结果:
贝叶斯Python代码及数据集下载地址:https://download.csdn.net/download/kongxiaoshuang509/11248193
需要源代码或者有问题的可以私信。















 9936
9936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









