






原理与算法
朴素贝叶斯分类器是以贝叶斯定理为基础并且假设特征条件之间相互独立的简单概率分类器。朴素贝叶斯分类器是基于独立假设的,即假设样本每个特征与其他特征都不相关。



导入相关库
import numpy as np
import scipy.io as scio
from scipy import stats
from sklearn import preprocessing
from sklearn.decomposition import PCA
from sklearn.datasets import load_digits # 导入数据朴素贝叶斯的实现
def NaiveBayes_train(train_x, train_y):
Y_class = np.unique(train_y) #类别
nfeature = train_x.shape[1] #属性个数
count = train_y.size #训练集样本的个数
P_c = np.zeros(Y_class.size)
mu_ci = np.zeros((Y_class.size,nfeature))
var_ci = np.zeros((Y_class.size,nfeature))
for i in range(Y_class.size):
ci_count = train_y[train_y==Y_class[i]].size #第i类别的样本个数
P_c[i]=ci_count/count
for j in range(nfeature):
mu_ci[i,j] = np.mean(train_x[train_y==Y_class[i],j])
var_ci[i,j] = np.var(train_x[train_y==Y_class[i],j])
return P_c, mu_ci, var_ci, Y_class
def NaiveBayes_test(test_x, P_c, mu_ci, var_ci, Y_class):
pre_y = np.zeros(test_x.shape[0])
h = np.zeros(Y_class.size)
for t in range(pre_y.size):
for i in range(Y_class.size):
h[i]=P_c[i]
for j in range(test_x.shape[1]):
h[i]=h[i]*stats.norm.pdf(test_x[t,j],loc=mu_ci[i,j],scale=np.sqrt(var_ci[i,j]))
pre_y[t]=Y_class[np.argmax(h)]
return pre_y用于手写数字识别
# Load data
digits = load_digits()
data = digits.data
target = digits.target
#choose train sample:0--999
train_x=data[0:1000]
train_y=target[0:1000]
#choose test sample 1000--end
test_x=data[1000:]
test_y=target[1000:]
# Data normalize
scaler = preprocessing.StandardScaler().fit(train_x)
train_x = scaler.transform(train_x)
test_x = scaler.transform(test_x)
#PCA
pca = PCA(n_components=15)
train_x = pca.fit_transform(train_x)
test_x = pca.transform(test_x)
# Train
P_c, mu_ci, var_ci, Y_class = NaiveBayes_train(train_x, train_y)
# Test
pre_y = NaiveBayes_test(test_x, P_c, mu_ci, var_ci, Y_class)
# Calculate the correct rate of test data
correct = np.sum(pre_y == test_y)
correct_rate = correct / test_y.size
print('Correct rate is: %.2f%%' % (correct_rate*100))结果展示
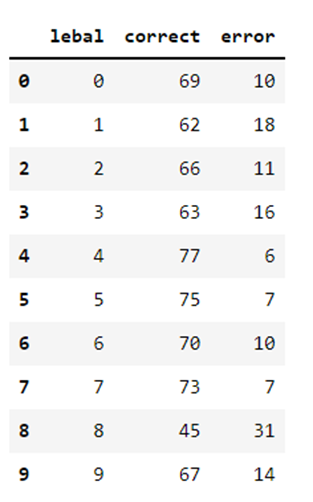
该模型预测的准确率为83.69%。通过pandas库的dataframe统计分类结果,如下图所示(其中‘correct’为预测正确的个数,‘error’为预测错误的个数):
通过pandas库的crosstab建立混淆矩阵,如下图所示:

对角线是预测正确的数字,我们发现:
真实值是“4”,被正确预测为“4”的项数有77项,预测准确率最高,最不容易混淆。真实值是“8”,被正确预测为“8”的项数有45项最低,也就是说最容易混淆。
其他非对角线的数字代表将某一个标签预测错误,成为另一个标签,我们发现:
真实值是“8”,但是预测值是“3” 的项数有11项;真实值是“1”,但是预测值是“9” 的项数有9项,这两种情况错误率相对较高。
朴素贝叶斯的优缺点
优点:
算法逻辑简单,易于实现
分类过程中时间和空间开销小
可调参数少
缺点:
朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
因为是通过先验和数据来决定后验的概率来决定分类的,所以分类决策存在一定的错误率。
对输入数据的表达形式很敏感。















 7480
7480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









