






在看完下面的细节之后,就会发现,spark的开发,只需要hdfs加上带有scala的IDEA环境即可。
当run运行程序时,很快就可以运行结束。
为了可以看4040界面,需要将程序加上暂定程序,然后再去4040上看程序的执行。
新建的两种方式,第一种是当时老师教的,现在感觉有些土,但是毕竟是以前写的,不再删除,就自己在后面添加了第二种新建方式。
一:通过maven命令行命令创建一个最初步的scala开发环境
1.打开cmd
通过maven命令创建一个最初步的scala开发环境。
mvn archetype:generate -DarchetypeGroupId=org.scala-tools.archetypes -DarchetypeArtifactId=scala-archetype-simple -DremoteRepositories=http://scala-tools.org/repo-releases -DgroupId=com.ibeifeng.bigdata.spark.app -DartifactId=logs-analyzer -Dversion=1.0
分两个部分,前面是scala项目需要的插件,后面是确定一个maven工程。
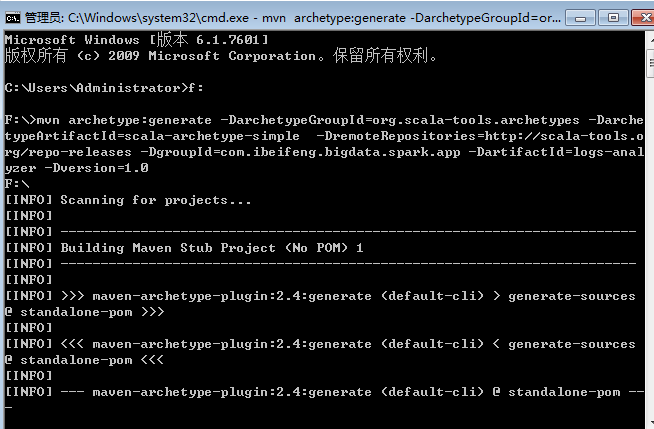
2.等待创建
这样就表示创建成功。
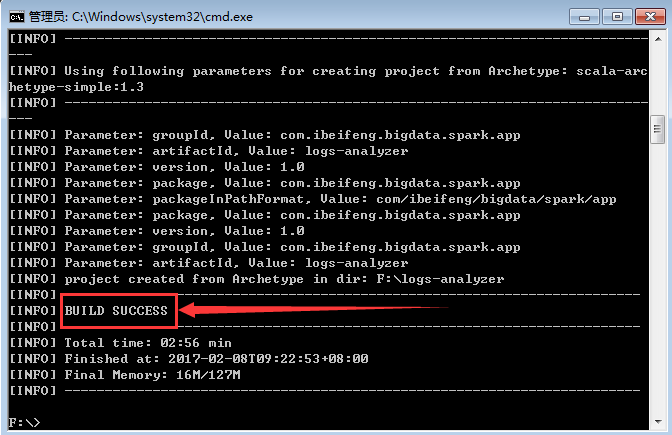
3.生成的项目在F盘
因为在cmd的时候,进入的是F盘。
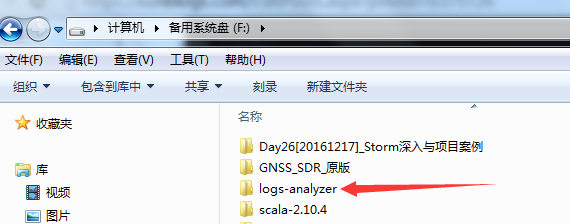
4.使用open导入
一种IDEA的使用打开方式。
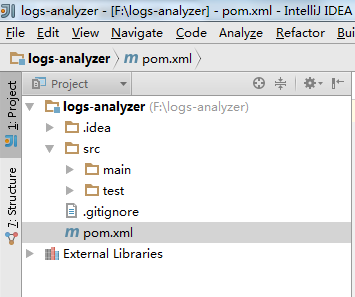
5.在pom.xml中添加dependency
HDFS ,Spark core ,Spark SQL ,Spark Streaming
这个里面重要的部分是有scala的插件。
1 <?xml version="1.0" encoding="UTF-8"?> 2 <project xmlns="http://maven.apache.org/POM/4.0.0" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 5 <modelVersion>4.0.0</modelVersion> 6 7 <groupId>sacla</groupId> 8 <artifactId>scalaTest</artifactId> 9 <version>1.0-SNAPSHOT</version> 10 11 <properties> 12 <maven.compiler.source>1.5</maven.compiler.source> 13 <maven.compiler.target>1.5</maven.compiler.target> 14 <encoding>UTF-8</encoding> 15 <spark.version>1.6.1</spark.version> 16 <hadoop.version>2.5.0</hadoop.version> 17 </properties> 18 19 <dependencies> 20 <!-- Spark Core --> 21 <dependency> 22 <groupId>org.apache.spark</groupId> 23 <artifactId>spark-core_2.10</artifactId> 24 <version>${spark.version}</version> 25 <scope>compile</scope> 26 </dependency> 27 <!-- Spark SQL --> 28 <dependency> 29 <groupId>org.apache.spark</groupId> 30 <artifactId>spark-sql_2.10</artifactId> 31 <version>${spark.version}</version> 32 <scope>compile</scope> 33 </dependency> 34 <!-- Spark Streaming --> 35 <dependency> 36 <groupId>org.apache.spark</groupId> 37 <artifactId>spark-streaming_2.10</artifactId> 38 <version>${spark.version}</version> 39 <scope>compile</scope> 40 </dependency> 41 <!-- HDFS Client --> 42 <dependency> 43 <groupId>org.apache.hadoop</groupId> 44 <artifactId>hadoop-client</artifactId> 45 <version>${hadoop.version}</version> 46 <scope>compile</scope> 47 </dependency> 48 49 <!-- Test --> 50 <dependency> 51 <groupId>junit</groupId> 52 <artifactId>junit</artifactId> 53 <version>4.8.1</version> 54 <scope>test</scope> 55 </dependency> 56 57 </dependencies> 58 59 <build> 60 <sourceDirectory>src/main/scala</sourceDirectory> 61 <plugins> 62 <plugin> 63 <groupId>org.scala-tools</groupId> 64 <artifactId>maven-scala-plugin</artifactId> 65 <version>2.15.0</version> 66 <executions> 67 <execution> 68 <goals> 69 <goal>compile</goal> 70 <goal>testCompile</goal> 71 </goals> 72 <configuration> 73 <args> 74 <arg>-make:transitive</arg> 75 <arg>-dependencyfile</arg> 76 <arg>${project.build.directory}/.scala_dependencies</arg> 77 </args> 78 </configuration> 79 </execution> 80 </executions> 81 </plugin> 82 <plugin> 83 <groupId>org.apache.maven.plugins</groupId> 84 <artifactId>maven-surefire-plugin</artifactId> 85 <version>2.6</version> 86 <configuration> 87 <useFile>false</useFile> 88 <disableXmlReport>true</disableXmlReport> 89 <!-- If you have classpath issue like NoDefClassError,... --> 90 <!-- useManifestOnlyJar>false</useManifestOnlyJar --> 91 <includes> 92 <include>**/*Test.*</include> 93 <include>**/*Suite.*</include> 94 </includes> 95 </configuration> 96 </plugin> 97 </plugins> 98 </build> 99 100 </project>
二:第二种方式
这种方式,比较实用。
1.直接新建一个Maven工程
需要在pom中添加scala的插件。
2.新建scala文件夹
原本生成的maven项目只有java与resources。
在project Stucture中新建scala文件夹,然后将scala文件夹编程sources。
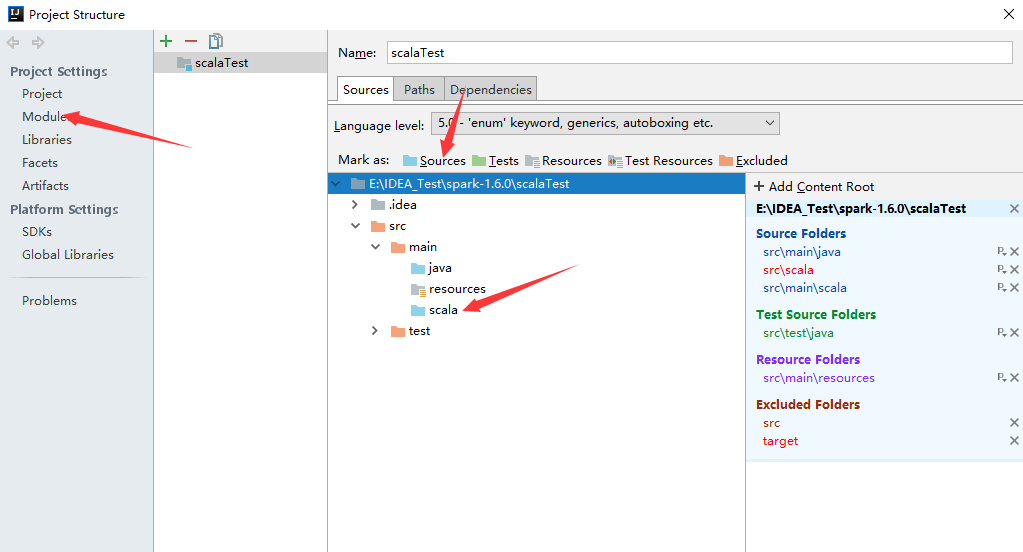
3.完成
这个截图还是第一种方式下的截图,但是意思没问题。

4.在resources中拷贝配置文件
需要连接到HDFS的配置文件。
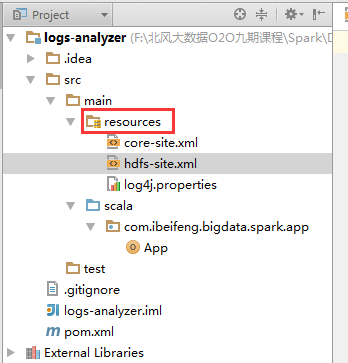
5.新建包
6.新建类
因为有了scala插件,就可以直接新建scala 的 object。
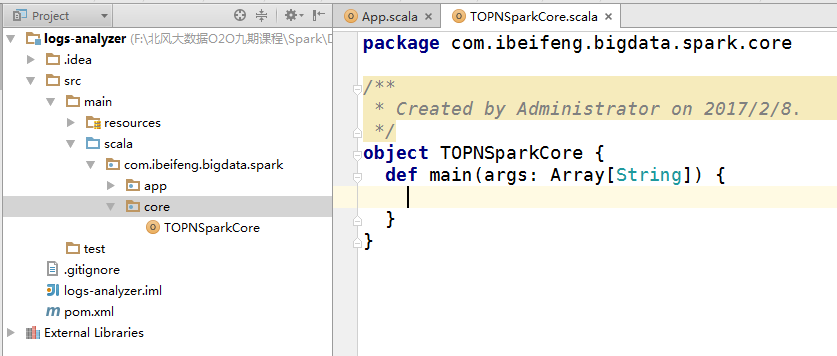
7.启动hdfs
因为需要hdfs上的文件,不建议使用本地的文件进行数据处理。
8.书写程序
这是一个简单的单词统计。
重点的地方有两个,一个是setMaster,一个是setAppName。如果没有设置,将会直接报错。
1 package com.scala.it 2 3 import org.apache.spark.{SparkConf, SparkContext} 4 5 object TopN { 6 def main(args: Array[String]): Unit = { 7 val conf=new SparkConf() 8 .setMaster("local[*]") 9 .setAppName("top3"); 10 val sc=new SparkContext(conf) 11 val path="/user/beifeng/mapreduce/wordcount/input/wc.input" 12 val rdd=sc.textFile(path) 13 val N=3 14 val topN=rdd 15 .filter(_.length>0) 16 .flatMap(_.split(" ").map((_,1))) 17 .reduceByKey((a,b)=>a+b) 18 .top(N)(ord = new Ordering[(String,Int)] { 19 override def compare(x: (String, Int), y: (String, Int)) : Int={ 20 val tmp=x._2.compareTo(y._2) 21 if (tmp==0)x._1.compareTo(y._1) 22 else tmp 23 } 24 }) 25 topN.foreach(println) 26 27 sc.stop() 28 29 } 30 }
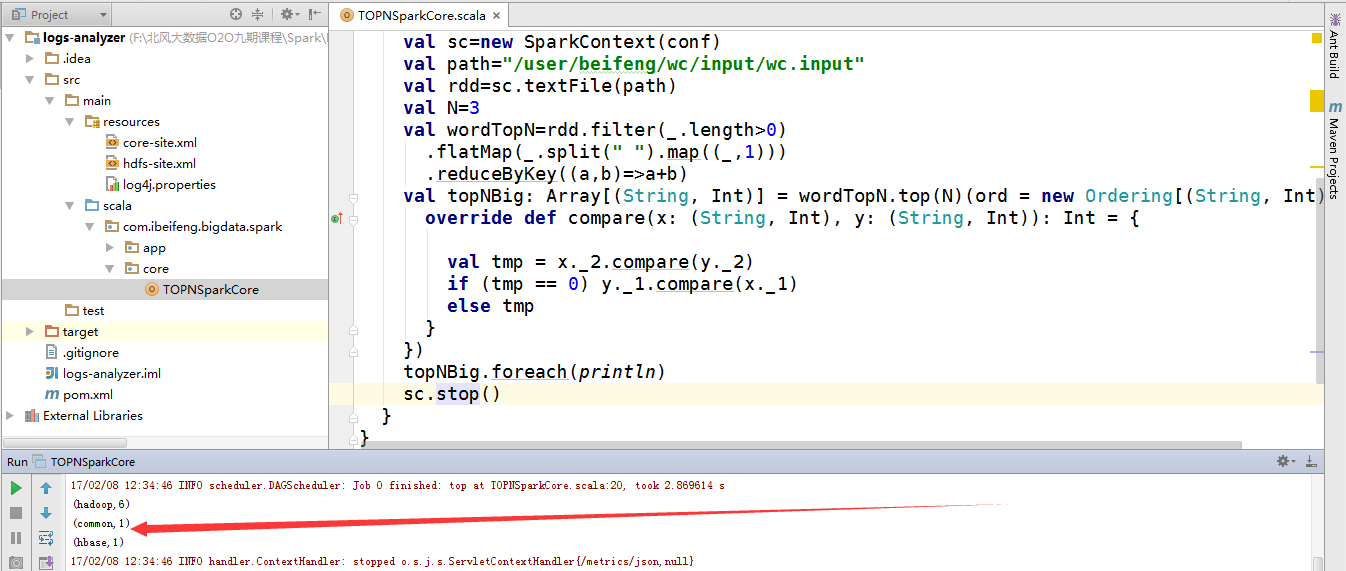
9.直接运行的结果
因为是local模式,所以不需要启动关于spark的服务。
又因为hdfs的服务已经启动。
所以,直接运行run即可。
二:注意的问题
1.path问题
程序中的path默认是hdfs路径。
当然,可以使用windows本地文件,例如在D盘下有abc.txt文件,这时候path="file:///D:/abc.txt"














 658
658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









