






昇思MindSpore介绍
昇思MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行、全场景统一部署三大目标。
其中,易开发表现为API友好、调试难度低;高效执行包括计算效率、数据预处理效率和分布式训练效率;全场景则指框架同时支持云、边缘以及端侧场景。
设计理念
- 支持全场景统一部署
昇思MindSpore源于全产业的最佳实践,向数据科学家和算法工程师提供了统一的模型训练、推理和导出等接口,支持端、边、云等不同场景下的灵活部署,推动深度学习和科学计算等领域繁荣发展。
- 提供Python编程范式,简化AI编程
昇思MindSpore提供了Python编程范式,用户使用Python原生控制逻辑即可构建复杂的神经网络模型,AI编程变得简单。
- 提供动态图和静态图统一的编码方式
目前主流的深度学习框架的执行模式有两种,分别为静态图模式和动态图模式。静态图模式拥有较高的训练性能,但难以调试。动态图模式相较于静态图模式虽然易于调试,但难以高效执行。 昇思MindSpore提供了动态图和静态图统一的编码方式,大大增加了静态图和动态图的可兼容性,用户无需开发多套代码,仅变更一行代码便可切换动态图/静态图模式,用户可拥有更轻松的开发调试及性能体验。例如:
设置set_context(mode=PYNATIVE_MODE)可切换成动态图模式。
设置set_context(mode=GRAPH_MODE)可切换成静态图模式。
- 采用AI和科学计算融合编程,使用户聚焦于模型算法的数学原生表达
在友好支持AI模型训练推理编程的基础上,扩展支持灵活自动微分编程能力,支持对函数、控制流表达情况下的微分求导和各种如正向微分、高阶微分等高级微分能力的支持,用户可基于此实现科学计算常用的微分函数编程表达,从而支持AI和科学计算融合编程开发。
- 分布式训练原生
随着神经网络模型和数据集的规模不断增大,分布式并行训练成为了神经网络训练的常见做法,但分布式并行训练的策略选择和编写十分复杂,这严重制约着深度学习模型的训练效率,阻碍深度学习的发展。MindSpore统一了单机和分布式训练的编码方式,开发者无需编写复杂的分布式策略,在单机代码中添加少量代码即可实现分布式训练,提高神经网络训练效率,大大降低了AI开发门槛,使用户能够快速实现想要的模型。
例如设置set_auto_parallel_context(parallel_mode=ParallelMode.AUTO_PARALLEL)便可自动建立代价模型,为用户选择一种较优的并行模式。
入门
处理数据集
MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。在本教程中,我们使用Mnist数据集,自动下载完成后,使用mindspore.dataset提供的数据变换进行预处理。
本章节中的示例代码依赖
download,可使用命令pip install download安装。如本文档以Notebook运行时,完成安装后需要重启kernel才能执行后续代码。
打印数据集中包含的数据列名,用于dataset的预处理。
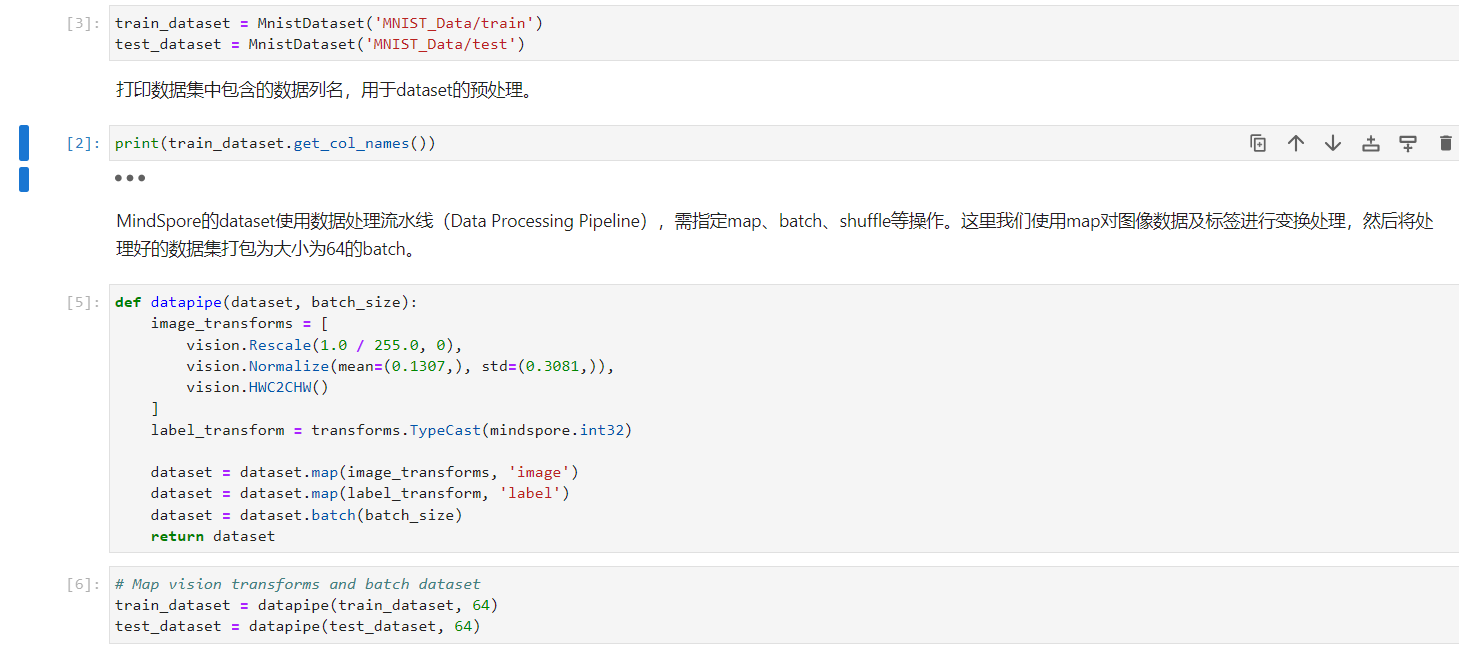
MindSpore的dataset使用数据处理流水线(Data Processing Pipeline),需指定map、batch、shuffle等操作。这里我们使用map对图像数据及标签进行变换处理,然后将处理好的数据集打包为大小为64的batch。
可使用create_tuple_iterator 或create_dict_iterator对数据集进行迭代访问,查看数据和标签的shape和datatype。
for image, label in test_dataset.create_tuple_iterator():
print(f"Shape of image [N, C, H, W]: {image.shape} {image.dtype}“)
print(f"Shape of label: {label.shape} {label.dtype}”)
break
Shape of image [N, C, H, W]: (64, 1, 28, 28) Float32
Shape of label: (64,) Int32
for data in test_dataset.create_dict_iterator():
print(f"Shape of image [N, C, H, W]: {data[‘image’].shape} {data[‘image’].dtype}“)
print(f"Shape of label: {data[‘label’].shape} {data[‘label’].dtype}”)
break
Shape of image [N, C, H, W]: (64, 1, 28, 28) Float32
Shape of label: (64,) Int32
更多细节详见数据集 Dataset与数据变换 Transforms。















 472
472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









