






在 SSAS 系列 - 实现第一个 Cube 以及角色扮演维度,度量值格式化和计算成员的创建 中主要是通过已存在的维度和事实数据创建了一个多维数据集,并同时解释了 Role-Playing Dimension 角色扮演维度,计算成员,计算成员格式化等内容。在这篇文章中主要是分析和理解在多维数据集设计过程中的聚合函数,对应不同类别的度量值根据需求的不同在聚合函数的选择上也会有所不同。
继续使用在上一篇 SSAS 文章中创建的示例,在 BIWORK_FirstCube 中能看到有两组度量值维度组和各个不同的度量值。
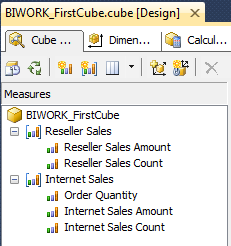
选中 Reseller Sales Amount 右键查看属性 AggregateFunction 聚合函数选择的是 SUM 聚合,很好理解就是一个求和的操作。
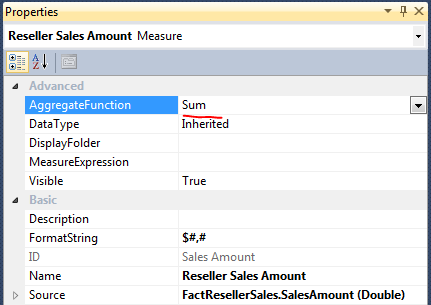
选中 Reseller Sales Count 右键查看属性,聚合函数选择的是 Count,这个是在创建多维数据集 Cube 的时候自动创建的。
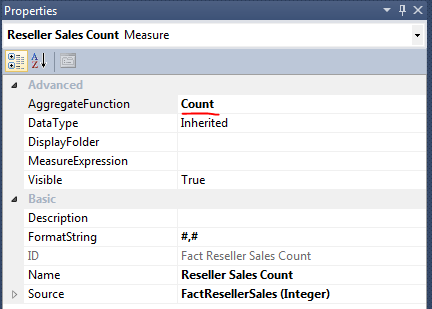
对比一下事实表 FactResellerSales 的结构和在创建 Reseller Sales 和 Internet Sales 度量值组时可供选择的度量值。所有的值类型的数据像 UnitPrice, ProductStandardCost, SalesAmount 这三个列在右侧创建度量值组 Fact Reseller Sales 都出现了,但是多了一个 Fact Reseller Sales Count ,包括在 Fact Internet Sales 下也多出了一个 Fact Internet Sales Count ,很明显是对事实表做了计数统计。因此在 Reseller Sales Count 度量值那里默认使用了 Count 聚合函数,而对于其它的度量值默认使用的是 SUM 函数。
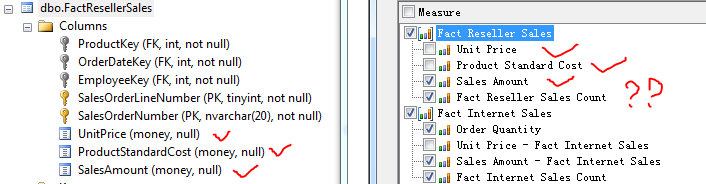
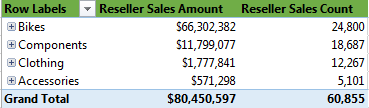
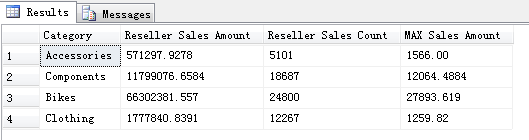
先来查看一下 Reseller Sales Amount 和 Reseller Sales Count 的在各个产品分类下的结果是多少。
然后再查询一下数据仓库的数据,看看在多维数据集中的聚合函数是如何完成计算的。
SELECT COUNT(DISTINCT SalesOrderNumber) AS SalesOrderCount,
COUNT(*) AS SalesOrderLineCount
FROM FactResellerSales
SELECT DISTINCT
dpc.EnglishProductCategoryName AS 'Category',
SUM(fact.SalesAmount) OVER(PARTITION BY dpc.ProductCategoryKey) AS 'Reseller Sales Amount',
COUNT(*) OVER(PARTITION BY dpc.ProductCategoryKey) AS 'Reseller Sales Count'
FROM FactResellerSales AS fact
LEFT JOIN DimProduct AS dp
ON fact.ProductKey = dp.ProductKey
INNER JOIN DimProductSubcategory AS dps
ON dp.ProductSubcategoryKey = dps.ProductSubcategoryKey
INNER JOIN DimProductCategory AS dpc
ON dps.ProductCategoryKey = dpc.ProductCategoryKey
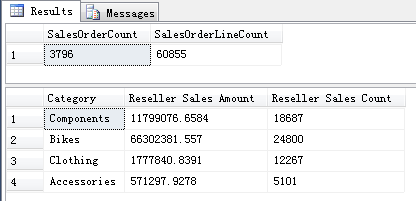
可以看到在 FactResellerSales 事实表中总共有 3796 个订单或者叫做交易,3796 中共有 60855 笔子订单业务。类似于在网店下了一个订单,这个订单上可能包含了不止一种购买的产品。 同时也可以看到 Category 下统计的 Reseller Sales Amount 和 Reseller Sales Count 的结果和在 Cube 中查询的结果是一致的。那么通过这种对比,就知道 SSAS 分析服务在创建多维数据集中是如何将我们的数据进行聚合的。 对于非 Key 类型的数值通常默认以 SUM 方式聚合,并且会额外创建一个度量值并以 COUNT 方式聚合表示事实的条数。
SSAS 中的聚合函数
实际上除了 SUM 和 COUNT 之外还有其它的一些聚合函数,在 SSAS 分析服务中我们可以大致将它们分为以下三类:累加性,半累加性和非累加性。
从这个小例子来理解这些聚合函数 -

累加性 - 累加性度量值主要是指父级层次结构中成员的值等于它所有子级成员值的总和。
- Sum - 父级成员值等于它所有子级成员值的总和,这是 SSAS 分析服务默认的聚合函数。
- Count - 计算事实表中特殊列非空值的函数,或者计算事实表的行数。父级成员也可以由它的所有子级成员值相加求得。
很显然交易金额是通过 SUM 聚合函数实现,交易笔数是通过 COUNT 聚合函数实现。

半累加性 - 半累加性度量值只是对某些子级得到进行聚合。
- Max - 父级成员值等于其所有子级中的最小值。
- Min - 父级成员值等于其所有子级中的最大值。
- FirstChild - 父级成员的值等于子级成员值的总和,但是如果在时间维度中,父级成员的值等于第一个子成员的值。
- LastChild - 父级成员的值等于子级成员值的总和,但是如果在时间维度中,父级成员的值等于最后一个子成员的值。
- FirstNonEmpty - 父级成员的值等于子级成员值的总和,但是如果在时间维度中,父级成员的值等于第一个非空子成员的值。
- LastNonEmpty - 父级成员的值等于子级成员值的总和,但是如果在时间维度中,父级成员的值等于最后一个非空子成员的值。
- AverageOfChildren - 对多维数据集时间维度中最低粒度级别的所有维度进行求和,然后再求平均值,即得所求值。(非空子成员)
- ByAccount - 当多维数据集包含一个账户类型的维度时,需要使用按账户聚合函数。度量值的按账户聚合函数是维度 Account 成员的一个属性。
比如在这里最大交易金额是通过 MAX 聚合的,最小交易金额是通过 MIN 聚合的,开始库存在时间维度上应该找第一个非空成员使用到了 FirstNonEmpty 聚合函数,而最后库存在时间维度上应该找最后一个非空成员的值。因为库存在实际业务中是不会进行累加操作的,每天开始的库存和每天结束的库存也是不一样的。

非累加性 - 父级成员的值不能由自己的值得到。
- DistinctCount - 非重复计算,对事实表中无重复的列进行计数,成员值是通过对该成员的无重复技术而确定的。
- NONE - 不进行任何聚合。
如果在订单上进行 DistinctCount,那么订单就是4笔,因为 D001 算一笔订单,在这笔订单里有两条订单明细信息。
那么有了这些基础知识之后,我们可以添加或者修改多维数据集中的度量值并提供合适的聚合函数了。
接着上面的项目,在多维数据集设计中选择 Reseller Sales 右键添加新的度量值。
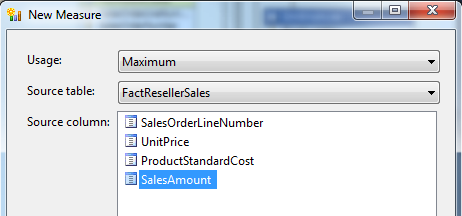
创建一个度量值 Maximum Sales Amount -
非空订单总数量 - Product Key Count

在 Usage 中有 Count of non-empty values (非空值计数) 和 Count of rows (行计数),它们的区别是行计数应用到事实表各行,而非空值技术应用到事实表各列。
Sales Order Number Distinct Count 非重复的订单号
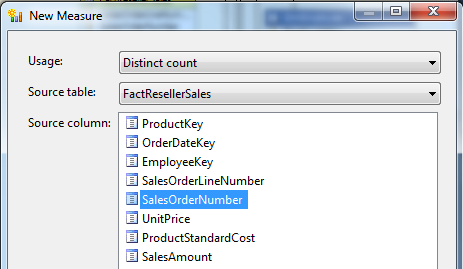
注意在使用非重复计数 Distinct Count 聚合函数的时候,SSAS 会创建一个单独的度量值组。这是因为 SSAS 分析服务处理非重复计数度量值组时,从事实表中选择数据的 SQL 查询会按照非重复计数列来进行排序,以便为非重复计数度量值而进行度量值组的物理数据存储实现优化。 因此,每一个非重复技术度量值都应该被放在单独的度量值组中。
保存并部署处理多维数据集,在 Excel 中浏览这些数据。(Reseller Sales Count 是 SSAS 自动创建的, Product Key Count 是我们在这里手动创建的)

使用 SQL 语句在数据仓库中直接查询。
SELECT DISTINCT
dpc.EnglishProductCategoryName AS 'Category',
SUM(fact.SalesAmount) OVER(PARTITION BY dpc.ProductCategoryKey) AS 'Reseller Sales Amount',
COUNT(*) OVER(PARTITION BY dpc.ProductCategoryKey) AS 'Reseller Sales Count',
MAX(fact.SalesAmount) OVER(PARTITION BY dpc.ProductCategoryKey) AS 'MAX Sales Amount'
FROM FactResellerSales AS fact
LEFT JOIN DimProduct AS dp
ON fact.ProductKey = dp.ProductKey
INNER JOIN DimProductSubcategory AS dps
ON dp.ProductSubcategoryKey = dps.ProductSubcategoryKey
INNER JOIN DimProductCategory AS dpc
ON dps.ProductCategoryKey = dpc.ProductCategoryKey
结果是一样的。
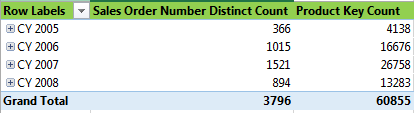
再来按年浏览一下订单数量和订单明细的数量,例如 CY2005 年共有366个订单,366个订单共计 4138 个订单明细。
在数据仓库中直接查询 Fact 表和 Dimension 表的结果也是一样的。
SELECT DISTINCT
dt.CalendarYearKey,
(
SELECT COUNT(DISTINCT f.SalesOrderNumber) AS OrderCountByYear
FROM FactResellerSales AS f
LEFT JOIN DimDate AS d
ON f.OrderDateKey = d.DateKey
WHERE d.CalendarYearKey = dt.CalendarYearKey
GROUP BY d.CalendarYearKey
)AS OrderNumberCount,
COUNT(*) OVER(PARTITION BY CalendarYearKey) AS OrderDetailCount
FROM FactResellerSales AS fact
LEFT JOIN DimDate AS dt
ON fact.OrderDateKey = dt.DateKey
ORDER BY dt.CalendarYearKey

另外,要补充一点。像 BI 项目的测试与其它项目的测试不太一样,因为更多的关于数据方面的清理,整理与转换。但是在数据仓库级别和 Cube 级别的数据比较,从我的这篇文章中应该可以看到一些方法与技巧。也就是无论是数据仓库还是多维分析数据库它们都是数据的一个容器,因此可以通过 SQL 语句直接在数据仓库中查询最原始的数据,然后与从 Cube 中无论从 MDX 还是 Excel 中出来的维度关联事实数据进行对比就可以了。
原因很简单,一种是基于数据仓库的 SQL 查询 (数据仓库 - Select 查询结果集) , 一种是基于数据仓库的多维数据集 (数据仓库 - Cube - Excel 或者 MDX),基于的都是同一个数据源,那么就比较它们各自的查询结果就知道数据是否是预期的了。
以后有时间专门再写一篇有关 BI 项目的测试过程,阶段分解以及测试的方法等。
更多 BI 文章请参看 BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server) 如果觉得这篇文章看了对您有帮助,请帮助推荐,以方便他人在 BIWORK 博客推荐栏中快速看到这些文章。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









