






经过两天,不断的调试,不断的改bug,终于按照自己的思想把哈夫曼树的建立写出来了,说实话有点辛苦,但是感觉还不错,感觉挺有成就感的,在代码过程中发现了不少的问题,比如不知为何传递过去的是指针,是地址,但是他在主函数的值不会改变,需要使用返回值来改变主函数的值,还有使用递归无法直接传递最后一轮的值给主函数等等一系列问题。
附代码:
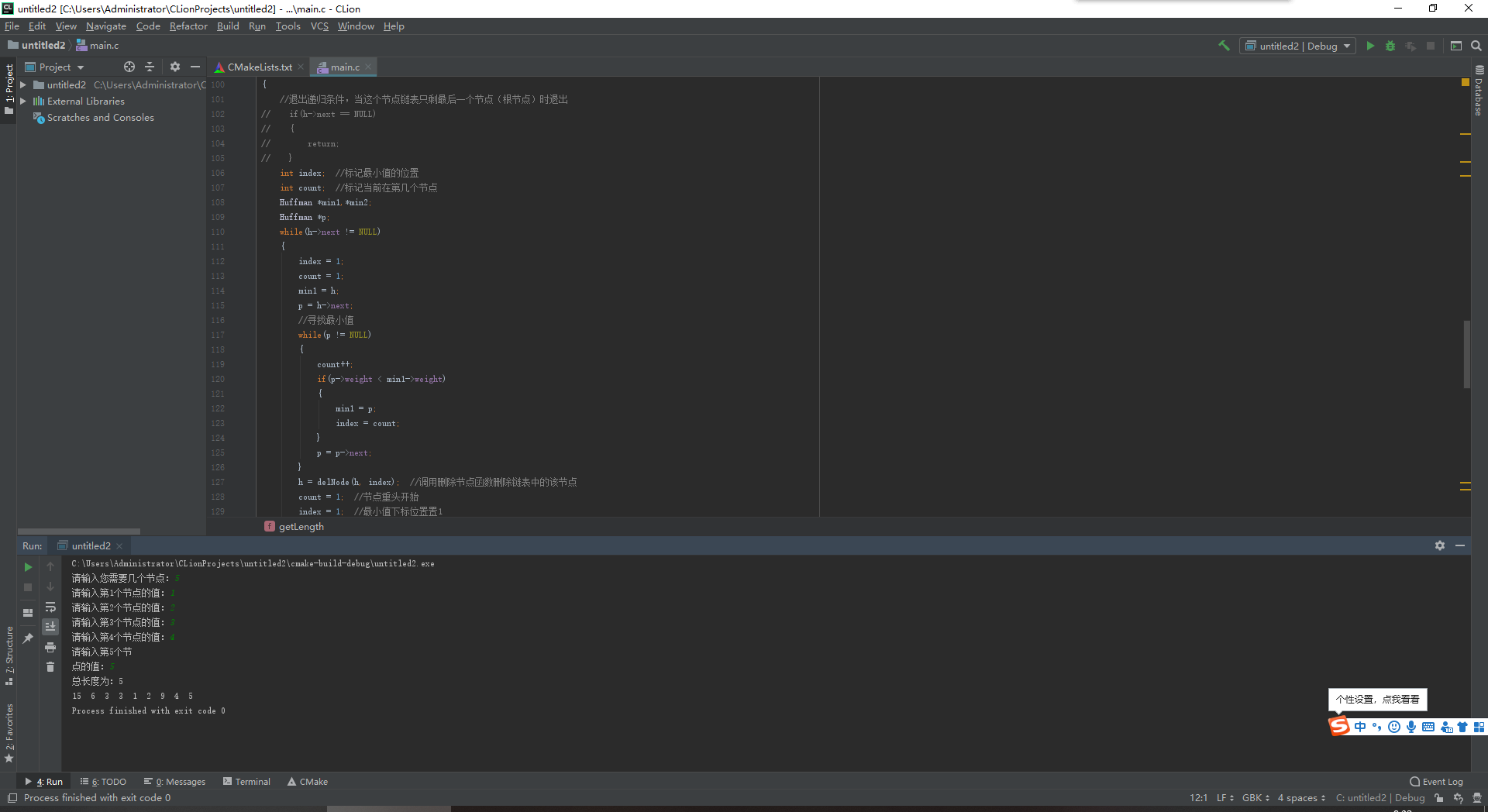
1 #include"stdio.h" 2 #include"stdlib.h" 3 //定义哈夫曼节点类型 4 typedef struct node{ 5 int weight; //权值 6 struct node *left; //左孩子 7 struct node *right; //右孩子 8 struct node *next; //下一个节点 9 }Huffman; 10 //初始化哈夫曼 11 int length = 0; 12 Huffman* creatHuffman() 13 { 14 int n; 15 Huffman *h; 16 Huffman *p; 17 Huffman *q; 18 h = q = (Huffman*)malloc(sizeof(Huffman)); 19 printf("请输入您需要几个节点:"); 20 scanf("%d",&n); 21 if(n <= 0 ) 22 { 23 printf("您输入的数值有错误!"); 24 return NULL; 25 } 26 else 27 { 28 for( int i = 0; i < n; i++) 29 { 30 p = (Huffman*)malloc(sizeof(Huffman)); 31 printf("请输入第%d个节点的值:",i+1); 32 scanf("%d",&p->weight); 33 p->left = NULL; 34 p->right = NULL; 35 q->next = p; 36 q = p; 37 } 38 p->next = NULL; 39 //返回h的下一个节点,h是哈夫曼节点链表的头结点,这里直接返回有值的节点就可以了; 40 return h->next; 41 } 42 } 43 //删除节点 44 Huffman *delNode(Huffman *h, int index) 45 { 46 Huffman *p = h; 47 Huffman *q; 48 if(index == 1) 49 { 50 h = h->next; 51 length--; 52 return h; 53 } 54 if(index == length) 55 { 56 for(int i = 1; i < index - 1; i++) //移动到要删除的节点的前一个 57 { 58 p = p->next; 59 } 60 p->next = NULL; //因为要删除的节点是链表中的最后一个,最后一个节点的next为NULL,删除后就由最后一个节点的前一个节点为结束 61 length--; 62 return h; 63 } 64 for(int i = 1; i < index -1; i++) //移动到要删除的节点的前一个 65 { 66 p = p->next; 67 } 68 q = p; //将q指向p的前一个节点 69 p = p->next; //p移动到了要删除的节点 70 q->next = p->next; //链表中该元素消除 71 length--; 72 return h; 73 } 74 //合并两个节点,成为一个新的节点,并将两个节点作为该节点的左右孩子 75 Huffman *mergeNode(Huffman *h ,Huffman *min1, Huffman *min2) 76 { 77 Huffman *newNode =(Huffman*)malloc(sizeof(Huffman)); //建立新的节点 78 Huffman *p = h; 79 newNode->weight = min1->weight + min2->weight; //合并两个节点的权值赋值给合并的节点 80 newNode->left = min1; 81 newNode->right = min2; 82 if(h ==NULL) 83 { 84 h = newNode; 85 } 86 else 87 { 88 while(p->next != NULL) 89 { 90 p = p->next; 91 } 92 p->next = newNode; //将新节点放入节点链表的最后一个,以便于后面比较大小 93 } 94 newNode->next = NULL; 95 length++; 96 return h; 97 } 98 //比较大小,找出两个最小的值的节点 99 Huffman *compareNode(Huffman *h) 100 { 101 //退出递归条件,当这个节点链表只剩最后一个节点(根节点)时退出 102 // if(h->next == NULL) 103 // { 104 // return; 105 // } 106 int index; //标记最小值的位置 107 int count; //标记当前在第几个节点 108 Huffman *min1,*min2; 109 Huffman *p; 110 while(h->next != NULL) 111 { 112 index = 1; 113 count = 1; 114 min1 = h; 115 p = h->next; 116 //寻找最小值 117 while(p != NULL) 118 { 119 count++; 120 if(p->weight < min1->weight) 121 { 122 min1 = p; 123 index = count; 124 } 125 p = p->next; 126 } 127 h = delNode(h, index); //调用删除节点函数删除链表中的该节点 128 count = 1; //节点重头开始 129 index = 1; //最小值下标位置置1 130 p = h->next; 131 min2 = h; 132 //寻找第二个最小值 133 while(p != NULL) 134 { 135 count++; 136 if(p->weight < min2->weight) 137 { 138 min2 = p; 139 index = count; 140 } 141 p = p->next; 142 } 143 h = delNode(h, index); //调用删除节点函数删除链表中的该节点 144 h = mergeNode(h , min1, min2);//调用合并节点函数构造一个新的节点 145 146 } 147 return h; 148 // h = compareNode(h); //递归调用自己 149 } 150 //计算总节点个数 151 void getLength(Huffman *h) 152 { 153 Huffman *p = h; 154 while(p != NULL) 155 { 156 length++; 157 p = p->next; 158 } 159 } 160 //输出二叉树 161 void printTree(Huffman *h) 162 { 163 if(h != NULL) 164 { 165 printf("%d ",h->weight); 166 printTree(h->left); 167 printTree(h->right); 168 } 169 } 170 main() 171 { 172 Huffman *h; 173 Huffman *p; 174 h = creatHuffman(); 175 getLength(h); 176 printf("总长度为:%d \n",length); 177 h = compareNode(h); 178 printTree(h); 179 }















 3413
3413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









