






solr环境的搭建请参考:http://www.cnblogs.com/xiao-zhang-blogs/p/7327814.html
1.Solr不支持搜索中文,办法总会有的,添加中文分词器。中文分词器有:IKAnalyzer,mmseg4j等
a)中文分词指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
b)写个程序看一下效果。(IKAnalyzer)
代码:
packagedemo;importjava.io.IOException;importjava.io.StringReader;importjava.util.HashMap;importjava.util.Iterator;importjava.util.Map;importorg.wltea.analyzer.core.IKSegmenter;importorg.wltea.analyzer.core.Lexeme;public classTest {public static void main(String[] args) throwsIOException {
String text= "我爱你中国,厉害了,我的国。我爱你!";int topWordsCount=4;
Map wordsFrenMaps=getTextDef(text);
sortSegmentResult(wordsFrenMaps,topWordsCount);
}public static Map getTextDef(String text) throwsIOException {
Map wordsFren=new HashMap();
IKSegmenter ikSegmenter= new IKSegmenter(new StringReader(text), true);
Lexeme lexeme;while ((lexeme = ikSegmenter.next()) != null) {if(lexeme.getLexemeText().length()>1){if(wordsFren.containsKey(lexeme.getLexemeText())){
wordsFren.put(lexeme.getLexemeText(),wordsFren.get(lexeme.getLexemeText())+1);
}else{
wordsFren.put(lexeme.getLexemeText(),1);
}
}
}returnwordsFren;
}public static void sortSegmentResult(Map wordsFrenMaps,inttopWordsCount){
Iterator> wordsFrenMapsIterator=wordsFrenMaps.entrySet().iterator();while(wordsFrenMapsIterator.hasNext()){
Map.Entry wordsFrenEntry=wordsFrenMapsIterator.next();
System.out.println(wordsFrenEntry.getKey()+" 的次数为"+wordsFrenEntry.getValue());
}
}
}
效果:

在步骤1.2中教大家如何将中文分词器添加到solr中。
2.创建core数据来源一共有三种情况,分别是:1、通过java直接写入。2、直接配置数据源。
a)在E:\solrhome目录下创建一个文件夹helloworld,将solr-6.6.0\example\example-DIH\solr\db文件夹下的conf文件夹赋值到helloworld文件夹下,如下图:

b)在solr的管理界面点击Core Admin,点击Add Core,输入name值为helloworld,instanceDir值为helloworld,其他项不用改。注意:填写的值必须为我们创建的文件夹的名称,否则报错。最后Add Core。
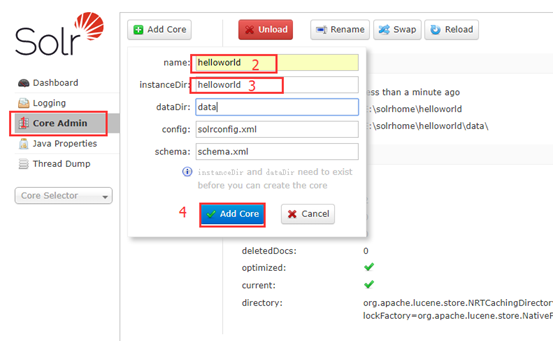
成功后:
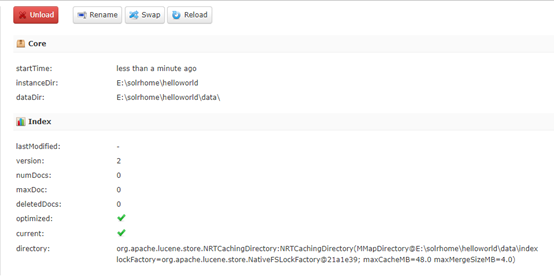
c)接下来,我们就在创建好的core中去写入数据。
i. 第一种,直接通过java程序写入。
代码如下:
packagetest;importjava.io.IOException;importjava.util.List;importorg.apache.solr.client.solrj.SolrQuery;importorg.apache.solr.client.solrj.SolrServerException;importorg.apache.solr.client.solrj.impl.HttpSolrClient;importorg.apache.solr.client.solrj.response.QueryResponse;importorg.apache.solr.common.SolrDocument;importorg.apache.solr.common.SolrDocumentList;importorg.apache.solr.common.SolrInputDocument;importorg.apache.solr.common.util.NamedList;public classTestSolr {//solr的服务器地址
private final static String SOLR_URL = "http://localhost:8080/solr/";/*** 往索引库添加文档
*@throwsIOException
*@throwsSolrServerException*/
public void addDoc() throwsSolrServerException, IOException{//获得一个solr服务端的请求,去提交 ,选择具体的某一个solr core//solr的服务器地址//private final static String SOLR_URL = "http://localhost:8080/solr/";
HttpSolrClient solr= new HttpSolrClient(SOLR_URL + "helloworld");try{//构造一篇文档
SolrInputDocument document = newSolrInputDocument();//往doc中添加字段,在客户端这边添加的字段必须在服务端中有过定义
document.addField("id", "1");
document.addField("name", "你好");
document.addField("description", "前进的中国你好");
solr.add(document);
solr.commit();
}finally{
solr.close();
}
}/*** 根据id从索引库删除文档*/
public void deleteDocumentById() throwsException {//选择具体的某一个solr core
HttpSolrClient server = new HttpSolrClient(SOLR_URL+"helloworld");//删除文档//server.deleteById("3");//删除所有的索引
server.deleteByQuery("*:*");//提交修改
server.commit();
server.close();
}/*** 查询
*@throwsException*/
public void querySolr() throwsException{
HttpSolrClient solrServer= new HttpSolrClient(SOLR_URL+"helloworld");
SolrQuery query= newSolrQuery();//String temp = "name:文 OR description:你";//query.setQuery(temp);//下面设置solr查询参数//query.set("q", "*:*");//参数q 查询所有
query.set("q","好");//相关查询,比如某条数据某个字段含有某个字 将会查询出来 ,这个作用适用于联想查询//参数fq, 给query增加过滤查询条件
query.addFilterQuery("id:[0 TO 9]");//id为0-9//参数df,给query设置默认搜索域
query.set("df", "name");//参数sort,设置返回结果的排序规则
query.setSort("id",SolrQuery.ORDER.desc);//设置分页参数
query.setStart(0);
query.setRows(10);//每一页多少值//参数hl,设置高亮
query.setHighlight(true);//设置高亮的字段
query.addHighlightField("name");//设置高亮的样式
query.setHighlightSimplePre("");
query.setHighlightSimplePost("");//获取查询结果
QueryResponse response =solrServer.query(query);//两种结果获取:得到文档集合或者实体对象//查询得到文档的集合
SolrDocumentList solrDocumentList =response.getResults();//NamedList,一个有序的name/value容器,NamedList不像Map
NamedList list = (NamedList) response.getResponse().get("highlighting");
System.out.println(list);
System.out.println("查询的结果");
System.out.println("总数量:" +solrDocumentList.getNumFound());//遍历列表
for(SolrDocument doc : solrDocumentList) {
System.out.println("id:"+doc.get("id")+" name:"+doc.get("name")+" description:"+doc.get("description"));
}
}
}
效果如下:

ii.直接配置数据源(结构化数据存储)
如何将中文分词器加入到solr中
先下载mmseg4j的jar包,一共有三个,分别是:mmseg4j-analysis-1.9.1.jar、mmseg4j-core-1.10.0.jar和mmseg4j-solr-2.4.0.jar。
将mmseg4j-core-1.10.0.jar和mmseg4j-solr-2.4.0.jar放在apache-tomcat-8.0.32\webapps\solr\WEB-INF\lib目录下。
(注意:不要将包mmseg4j-analysis-1.9.1.jar放到改目录下,否则会报:java.lang.NoSuchMethodError: com.chenlb.mmseg4j.analysis.MMSegTokenizer.(Lcom/chenlb/mmseg4j/Seg;)V错误信息,原因是:mmseg4j-solr已经包含了mmseg4j-analysis)

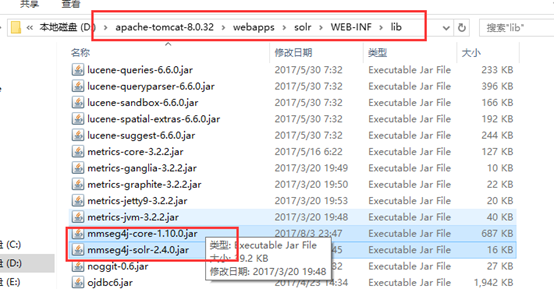
在core去配置。
没有加入中文分词器的效果,无论你选择哪种类型,得到的结果如下:
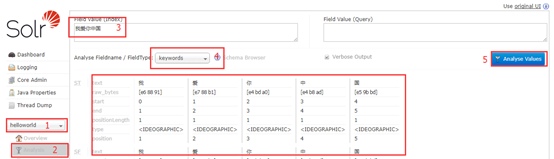
添加中文分词器:
首先mmseg4j有三种分词方式:
把这些添加到E:\solrhome\helloworld\conf的managed-schema文件的325行左右。
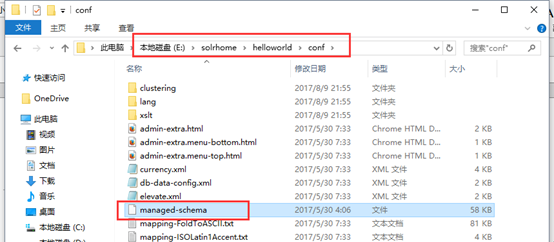

这个文件里面的field 标签里name存放的就是你所要分词的名称,type 放的是分词的类型。这里我把name=”title” 的type改为textComplex。(在148行)
重启tomcat,看一下效果(成功):
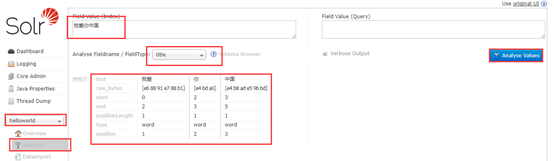
然后配置oracle数据源,这里我选用的表为books表
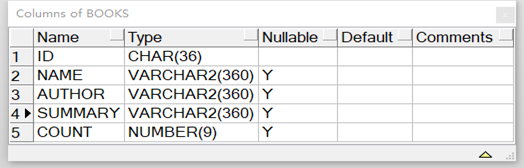
在managed-schema去添加字段类型和名称(author和name配置文件中有,修改一下type即可,id配置文件中也有,127行)
配置数据库映射:
首先,在E:\solrhome\helloworld\conf创建一个data-config.xml文件
文件内容:
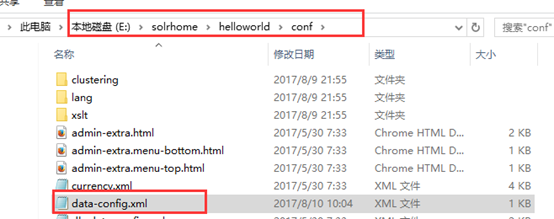
接着在E:\solrhome\helloworld\conf的solrconfig.xml配置文件中的(743行)上面添加
data-config.xml
将数据从数据库导入到helloworld的core中,如下图:
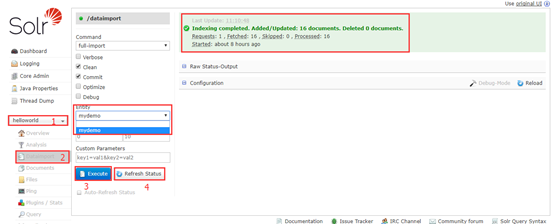
接着,查询全部:

数据成功导入。















 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









