






机器学习:
自己的理解,机器学学习是一门多领域的交叉学科,专门研究计算机怎么模拟或者实现人类的学习方式和行为,以获取新的知识和技能,重新组织已有的知识结构和性能。
1.读《大数据工程师飞林沙的年终总结&算法数据的思考》
推荐系统:涉及到不懂的名词
1.1这个是一篇博客《一个简单的基于内容的推荐算法》(理解的比较透彻)http://www.cnblogs.com/qiuleo/p/4225594.html
讲的content-base(基于内容的推荐系统这个比较基础)方法比较简单易懂
这个内容的推荐算法思路大概分成3部
(1).为每一个物品建立一个物品的属性资料;
(2)为每一个用户构建一个用户的爱好资料;
(3)计算用户喜好资料与物品属性资料的相似度,相似度高意味着用户可能喜欢这个物品,相似度低往往意味着用户不喜欢这个物品。(这个比较好理解)。
也就是说选择一个想要推荐的用户“U”,针对用户U遍历一遍物品几何,计算出每个物品与用户U的相似度,选出相似度最高的k个物品,将他推荐给用户U。这样就可以了,但是个人觉得这种方法相率较低。
里面提到了几个名词Item Profiles(通俗的将就是被推荐物品的详细属性)、representing Item Profiles(将这些只有人类能读懂的名词转化成计算机能读懂的数据结构)、User Profiles(用户的详细信息)
拿电影的推荐来举例:对Item profiles建立模型构造一个1*n维矩阵,n表示全球主要影星的数量,每一个位置表示一个影星,0、1表示该电影中有无此明星。初始化这个矩阵,把矩阵的值都设为0;设此矩阵为I [0,0,0,0.....0];
对用户Users Profiles进行建模:
| 用户\电影 | 《尖峰时刻》 | 《红番区》 | 《黑客帝国》 |
| Alice | 4 | 5 | 3 |
| Bob | 1 | 4 |
举例给出两个用户对三个电影的评分
之后是一些基本概念由于前两个电影有一个共同特点就是都有成龙主演,推测出alice可能喜欢成龙
提取参数Avg = (4+5+4)/2=4
接下来算出有这些参数就可以算出来alice对成龙的喜好程度s=(Σ(x - avg))/n 这里x表示所有涉及到成龙,且alice评价过的电影,n为示所有涉及到成龙,且alice评价过的电影的数量。且User Profiles也建立一个1*n的矩阵,但是矩阵中的值不在为0或1,而是对这个演员的喜好程度s。设此矩阵为U。
利用余弦相似度公式计算给定的两个矩阵U和I的相似度。
最后遍历整个影库,计算用户和每一个影片的相似度选出k个影片推荐给alice,这样就可以了。
查询维基百科:余弦相似度公式
1.2.Collaborative Filering(协同过滤)
参考维基百科,与上述基于内容推荐系统不同,协同过滤分析用户的兴趣,在用户群中找到制定用户的相似(兴趣)用户,综合这些相似用户的某一信息的评价,形成系统对该指定用户的喜好程度的预测。这样做可以过滤掉难以进行机器自动基于内容分析的信息。(这句话本人不太好理解。。)自己理解就是一些音乐名字或者是艺术品的名字机器无法理解就这届过滤掉了。
系统过滤的缺点(当站点结构、内容的复杂性和用户人数的不断增加,协同过滤额缺点就暴露出来了)(1)稀疏性:通俗的将就是数据比较少:每个用户的信息量涉及相当有限,举个例子,比如说亚马逊网站中,用户的评论只有1%~2%(终于知道为什么网站都鼓励评价和晒单了。。。)这样导致了评估矩阵数据相当稀疏,难以找到用户集,导致推荐效果大大降低。
(2)扩展性:“最近邻居”算法的计算量随着用户和项的增加而大大增加,对于上百万之巨的数目,通常的算法将遭遇到严重的扩展性问题。
(3)精确性:通过寻找相近用户来产生推荐集,在数据量较大的时候可信度会随着降低。
回归刚刚的文章,在文章中作者提到了多种算法的混合,这样多个推荐算法的交际策略,这样可以最大化的满足用户的心理底线,从而吸引用户点击。这样就可以用少量的高质量item最大化满足了用户的心理底线,之后主要讨论了推荐系统的作用,捡钱的例子特别有深意。
3.深度学习:
是机器学习领域中试图使用多重重线性变换对数据进行多层抽象的算法。多种深度学习框架、深度神经网络。卷积神经网络和深度信念网络。
深度神经网络(deep neuron networks, DNN)是一种判别模型,可以使用反向传播算法进行训练。权重更新可以使用下式进行随机梯度下降求解:
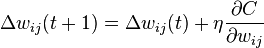
其中,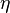 为学习率,
为学习率, 为代价函数。这一函数的选择与学习的类型(例如监督学习、无监督学习、增强学习)以及激活函数相关。例如,为了在一个多分类问题上进行监督学习,通常的选择是使用Softmax函数作为激活函数,而使用交叉熵作为代价函数。Softmax函数定义为
为代价函数。这一函数的选择与学习的类型(例如监督学习、无监督学习、增强学习)以及激活函数相关。例如,为了在一个多分类问题上进行监督学习,通常的选择是使用Softmax函数作为激活函数,而使用交叉熵作为代价函数。Softmax函数定义为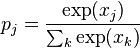 ,其中
,其中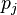 代表类别
代表类别 的概率,而
的概率,而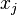 和
和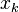 分别代表对单元和
分别代表对单元和 的输入。交叉熵定义为
的输入。交叉熵定义为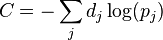 ,其中
,其中 代表输出单元的目标概率,代表应用了激活函数后对单元的概率输出[32]。这个方法有点没看懂,还要好好理解一下。
代表输出单元的目标概率,代表应用了激活函数后对单元的概率输出[32]。这个方法有点没看懂,还要好好理解一下。
文章提到了在推荐系统中,深度学习的局限和不足、由于实际中存在大部分的缺失值,如果你希望用深度学习来对该矩阵做特征重组。
大数据:指所涉及的数据规模巨大到无法通过人工,在合理时间内达到截取、管理、处理、并整理成人类所能解读的信息。在总数据量相同的情况下,与个别分析独立的小型数据集相比,将各个小型数据集合并进行分析可以的到许多额外的信息和数据关系性。
稳重提到大数据的反思,其中说明很多公司对大数据去噪,其实对其中的异常点观察才是个性化的极致!!!
任何系统都不能脱离产品而独立存在。不要无视数据也不要神话迷信数据。这篇文章之后写的一个数据工程师的发展和对一些公司和这个行业的看法,个人感觉很受用!!















 3763
3763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









