







VizML: 一种基于机器学习的可视化推荐方法
1 论文概述
本文发表于CHI 2019。 作者来自MIT Media Lab和MIT CSAIL。
1.1 摘要
可视化推荐系统的目标是通过自动生成结果让分析师进行搜索和选择,而不是手动指定,从而降低探索基本可视化的障碍。
在这里,我们演示了一种基于机器学习的可视化推荐新方法,该方法从大量的数据集和相关的可视化中学习可视化设计选择。首先,我们确定分析师在创建可视化时所做的五个关键设计选择,例如选择可视化类型和选择沿着X或y轴对列进行编码。我们使用从一个流行的在线可视化平台收集的100万个数据集可视化对来训练模型来预测这些设计选择。与基线模型相比,神经网络预测这些设计选择具有较高的准确性。我们从这些基线模型中报告并解释特性的重要性。
为了评估该方法的通用性和不确定性,我们使用一个众包测试集进行基准测试,结果表明,我们的模型在预测共识可视化类型时的性能与人类的性能相当,并超过了其他可视化推荐系统。
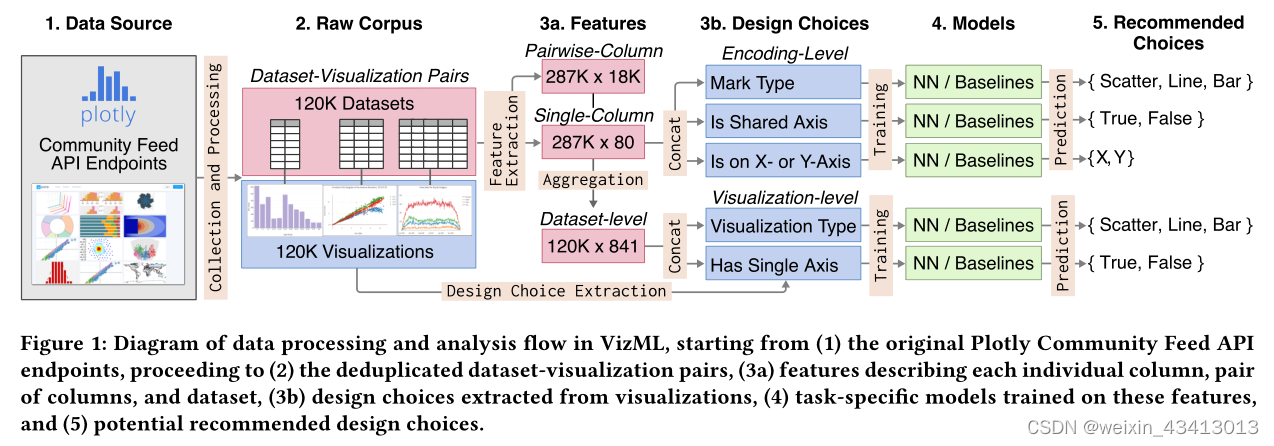
1.2 引言
背景:
跨领域的知识工作者——从商业到新闻到科学研究——越来越多地使用数据可视化来产生见解、交流发现和做出决策[9,26,58]。然而,许多可视化工具由于依赖于代码[7,68]或点击[2,62]的手动说明,学习曲线陡峭。因此,越来越多缺乏时间或背景来学习复杂工具的领域专家往往无法访问数据可视化。
虽然需要创建定制的可视化,但是对于许多常见的用例(如初步的数据探索和基本可视化的创建)来说,手工规范是不必要的。在这些用例中,搜索的速度和广度比可定制性更重要[63],为了支持这些用例,系统可以利用数据集的属性对可视化的影响。例如,先前的研究表明,视觉通道(如位置和颜色)编码数据的准确性取决于数据值的类型[5,15,67]和[28]分布.
前人方案:
基于规则的方法:
大多数推荐系统将这些可视化指南编码为“if-then”语句的集合,或规则[21],以自动生成可视化,供分析人员搜索和选择,而不是手动指定[64]。例如,APT[35]、BOZ[13]和SAGE[52]使用感知原则的规则生成可视化并排序。最近的系统如Voyager[72,73]、Show Me[34]和DIVE[23]扩展了这些方法,支持列选择。虽然对于某些用例[72]是有效的,但是这些基于规则的方法面临着限制,例如昂贵的规则创建和可能结果[1]的组合爆炸。
基于机器学习的方法:
相比之下,基于机器学习(ML)的系统通过对分析师交互的训练模型直接学习数据和可视化之间的关系。虽然最近的系统如DeepEye[33]、Data2Vis[17]和Draco-Learn[37]都很令人兴奋,但它们并没有像分析师那样学会如何选择可视化设计,这将影响到可解释性和集成到现有系统的方便性。此外,由于这些系统在受控设置中使用规则生成的可视化注释进行训练,它们受到数据数量和质量的限制。
本文方案:
我们引入了VizML,这是一种基于ml的方法,使用大量的数据集和相关的可视化来实现可视化推荐。首先,我们将可视化描述为一个做出设计选择的过程,使效率最大化,这取决于数据集、任务和上下文。然后,我们制定可视化建议作为一个开发模型的问题,学习做出设计选择。
我们使用来自Plotly Community Feed[46]的100万个独特的数据集可视化对来训练和测试机器学习模型。我们描述了收集和清理这个语料库的过程,从每个数据集提取特征,并从相应的可视化中提取五个关键的设计选择。我们的学习任务是优化模型,利用数据集的特征来预测这些选择。
结果与评估:
在60%的语料库上训练的神经网络在一个单独的20%测试集中预测设计选择的准确率达到了70 - 95%。这一性能超过了四个更简单的基线模型,它们本身的性能优于随机概率。我们从这些基线模型之一报告特征的重要性,解释特征对给定任务的贡献,并将它们与现有的研究联系起来。
我们通过对众包测试集进行基准测试来评估我们模型的可泛化性和不确定性。我们通过从Plotly中随机选择数据集来构建这个测试集,将每个数据集可视化为一个条形、直线和散点图,并测量机械土耳其工人的共识。使用一个根据共识程度调整的评分指标,我们发现VizML的表现与Plotly用户和Mechanical Turkers相当,并且优于两个基于规则和两个基于ml的可视化推荐系统。
最后,我们讨论了初始机器学习方法在可视化推荐中的解释、应用和局限性。我们还提出了未来研究的方向,例如聚合公共训练和基准语料,将单独的推荐模型集成到端到端系统中,以及细化可视化有效性的定义。
2 问题陈述
数据可视化通过用可视化元素表示数据来传递信息。这些表示是用从数据映射到实体属性的编码指定的:图形标记(例如点、线或矩形)的位置、长度或颜色[5,12]。
具体地说,考虑一个描述406辆汽车(行)的数据集,它有8个属性(列),比如每加仑行驶里程(MPG)、马力(Hp)和磅重(Wgt)[50]。为了创建显示mpg和hp之间关系的散点图,分析人员将每对数据点与二维平面上圆的位置进行编码,同时还指定其他属性,如大小和颜色:
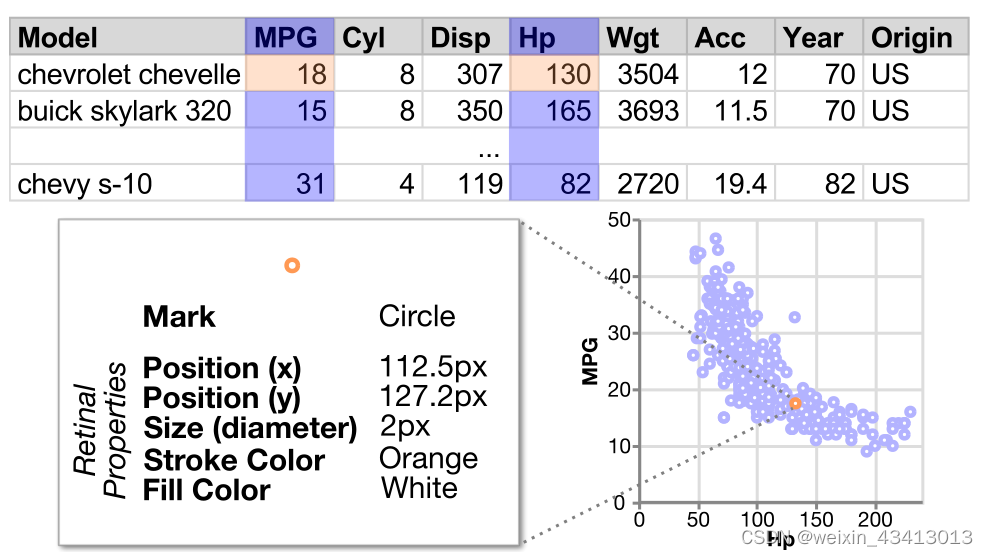
我们将数据集d的基本可视化表述为一组相互联系的设计选择 C ={c}。然而,并不是所有的设计选择都会产生有效的可视化效果——有些选择彼此不兼容。例如,使用线标记的Y轴位置编码分类列是无效的。因此,产生有效可视化结果的选择集是所有可能选择的空间的子集。
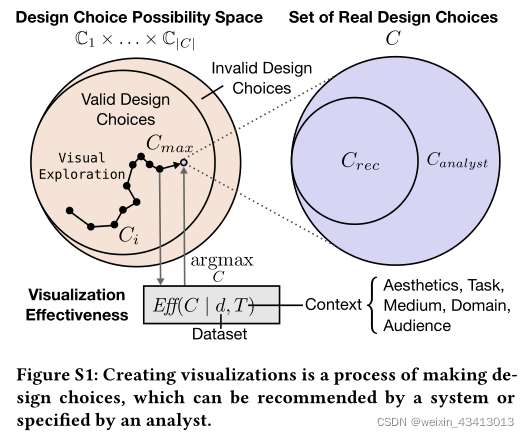
可视化的有效性可以通过信息度量,如效率、准确性和可记忆性(efficiency, accuracy, and memorability)[6,74],或情感度量,如参与度(engagement)[19,27]来定义。先前的研究还表明,除了任务[3,28,53]、美学[14]、领域[24]、受众[60]和媒介[36,57]等上下文因素外,有效性还受到低级感知原则[15,22,31,51]和数据集属性[28,54]的影响。
换句话说,在给定 数据集d 和 上下文因素T 的情况下,分析师做出的 设计选择C 可以使 可视化有效性EFF 最大化,此时的设计选择C_max定义为:
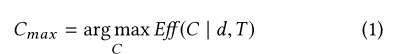
但是,做出设计选择可能是昂贵的。可视化推荐的一个目标是,通过自动建议一个子集的设计选择(C_rec⊆C)来降低创建可视化的成本,从而最大化效率。使用由数据集{d}和相应的设计选择{C}组成的语料库训练的基于ml的推荐系统,将推荐视为一个优化问题,如预测C_rec ~ C_max。
设计选择推荐建模:
给定 C’(除了设计选择c以外的其他选择)、数据集d 和 上下文因素T ,理想的设计决策推荐函数F_c输出最大化可视化有效性的设计选择c_max。
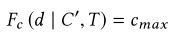
我们的目标是用函数G_c来近似F_c。现在假设一组数据集D={d}和相应的可视化V={V_d},每个可视化都可以用设计选项C_d={c_d}来描述。基于机器学习的推荐系统考虑G_C作为带有一组参数Θ_c的模型,可以通过最大化目标函数Obj的学习算法对该语料库进行训练:
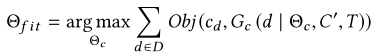
在不丧失一般性的情况下,假设目标函数使训练输出{C_d}的可能性最大化。即使分析师做出次优设计选择,集体优化所有观察到的设计选择的可能性仍然是最优的。这正是我们观察到的设计选择c_d=F_c(d|C′,T)+噪声+偏差的情况。因此,给定一个看不见的数据集d∗, 最大化这个目标函数可以合理地给出一个使可视化的效果最大化的推荐。
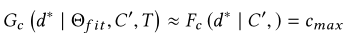
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 803
803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









