






正因为生来什么都没有,因此我们能拥有一切。 --《游戏人生》
一、程序分析
1、读文件到缓冲区
1 def process_file(dst): # 读文件到缓冲区 2 try: # 打开文件 3 f = open(dst,'r') 4 except IOError,s: 5 print s 6 return None 7 try: # 读文件到缓冲区 8 bvffer = f.read() 9 except: 10 print "Read File Error!" 11 return None 12 f.close() 13 return bvffer
2、缓冲区处理
1 def process_buffer(bvffer): 2 if bvffer: 3 word_freq = {} 4 # 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq 5 bvffer.lower() # 把所有字母全部转化成小写 6 char={"~@#$%^&*()_-+=<>?/,.:;{}[]|\'“”"} 7 for ch in char : 8 bvffer=bvffer.replace(ch,' ') # 除去标点符号,注意别忘记去除中文标点 9 words=bvffer.strip().split() # 单词分散成列表 10 for word in words: 11 word_freq[word]=word_freq.get(word,0) + 1 12 return word_freq
3、打印TOP 10 词频单词
1 def output_result(word_freq): 2 if word_freq: 3 sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) 4 for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 5 print item
4、main 函数
1 if __name__ == "__main__": 2 import argparse 3 parser = argparse.ArgumentParser() 4 parser.add_argument('dst') 5 args = parser.parse_args() 6 dst = args.dst 7 bvffer = process_file(dst) 8 word_freq = process_buffer(bvffer) 9 output_result(word_freq)
二、代码风格说明
Python语句书写规则如下。
(1)使用换行符分隔,一般情况下,一行一条语句。
(2)从第一列开始,前面不能有任何空格,否则会产生语法错误。
(3)复合语句中,结构体语句块相对头部语句缩进4个空格。
例如:1、读取文件到缓冲区的第1行、第2行、第3行 有4个空格的缩进。
三、程序运行截图
环境:Centos 7.5 64位 python 2.7.5
命令:$ python word_freq.py Gone_with_the_wind.txt
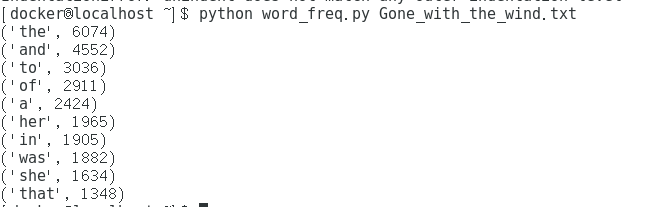
四、性能分析结果及改进
性能分析结果如下:
(点击图片查看大图)

执行时间最长的代码是:process_buffer 缓冲区处理模块
执行次数最多的代码是:output_result 中的 sort 排序代码
(若有误,请指出!)
使用Gprof2Dot进行性能分析的图形结果如下:
(点击图片查看大图)
执行代码:

输出图形结果:
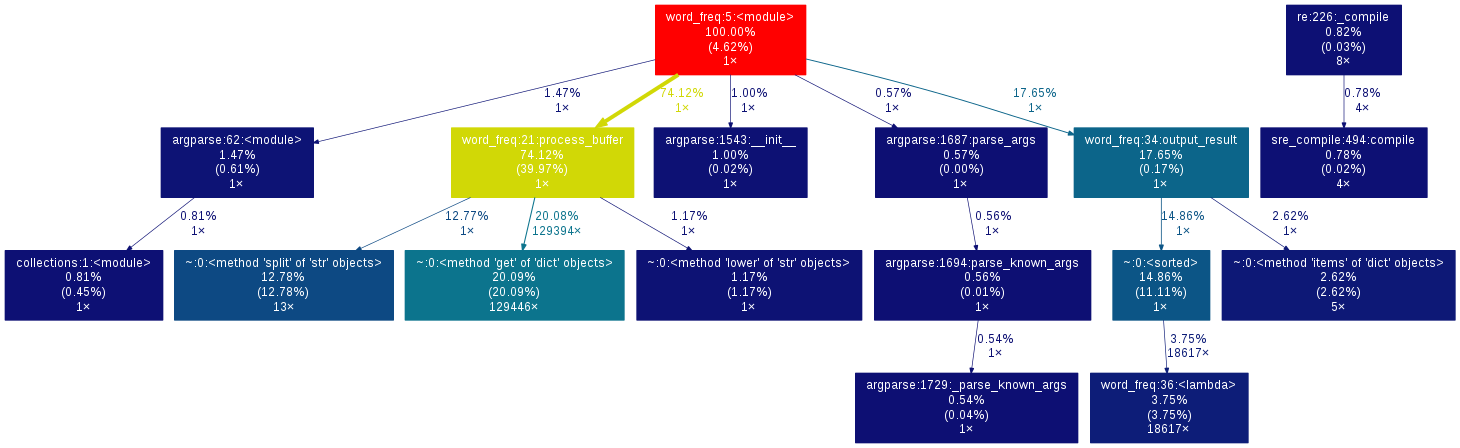
通过图形可以看到,split()方法 和 get()方法消耗了大量的时间。
改进思路,由于split()方法必须使用,所以不做改动。不使用get(),而是使用原始的判断方法来计数词频
原代码:
1 for word in words: 2 word_freq[word]=word_freq.get(word,0) + 1
修改后:
1 for word in words: 2 if word in word_freq: 3 word_freq[word] = word_freq[word] + 1 4 else: 5 word_freq[word] = 1
再次运行,查看性能分析:
(点击图片查看大图)

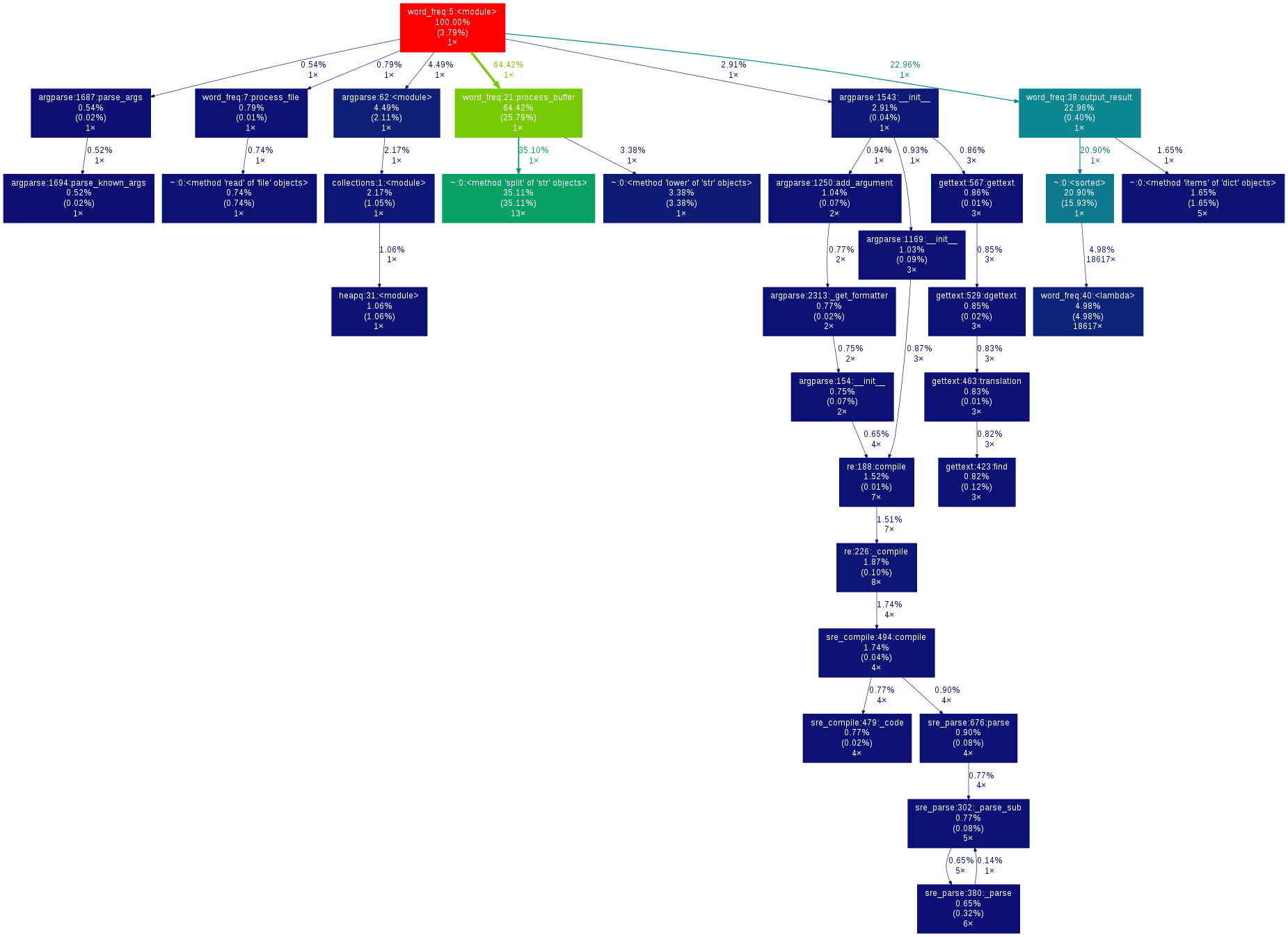
缓冲区处理模块的运行时间有所减少。















 1104
1104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









