






概念:
通常机器学习每一个算法中都会有一个目标函数,算法的求解过程是通过对这个目标函数优化的过程。在分类或者回归问题中,通常使用损失函数(代价函数)作为其目标函数。损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。
refer:https://blog.csdn.net/weixin_37933986/article/details/68488339
________________________________________________________________________________________________
以下的结果是针对模型(faster_rcnn_inception_resnet_v2_atrous_coco)训练多个分类且不同分类的样本集不均匀的实践
让loss快速下降方式
训练集:
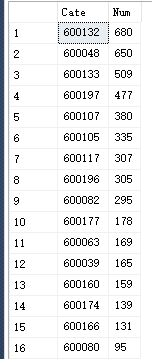
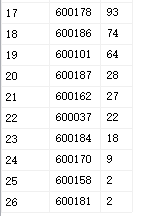
Config设置:
a、采用dropout
use_dropout: true #false
dropout_keep_probability: 0.6
b、多阶段学习率,开始设置很高且尽量让其迭代到loss足够的低
initial_learning_rate: 0.003
schedule {
step: 0
learning_rate: .003
}
schedule {
step: 30000
learning_rate: .0003
}
schedule {
step: 45000
learning_rate: .00003
}
......
c、为了发现更多的box,对IOC阈值进行调整(与loss没什么关系)
first_stage_nms_iou_threshold: 0.4
second_stage_post_processing {
batch_non_max_suppression {
score_threshold: 0.0
iou_threshold: 0.5
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SOFTMAX
}
效果:
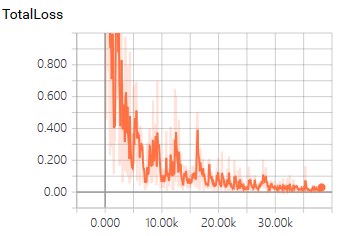
















 1163
1163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









