






一、概念:
RDD (Resilient Distributed Dataset)弹性分布式数据集
RDD并不存储真实的数据,存储数据的获取方式,以及分区的信息,还有数据的类型
(1) RDD 的 5 个主要属性(property)
1、A list of partitions
多个分区. 分区可以看成是数据集的基本组成单位.
对于 RDD 来说, 每个分区都会被一个计算任务处理, 并决定了并行计算的粒度.
用户可以在创建 RDD 时指定 RDD 的分区数, 如果没有指定, 那么就会采用默认值. 默认值就是程序所分配到的 CPU Coure 的数目.
每个分配的存储是由BlockManager实现的.每个分区都会被逻辑映射成BlockManager的一个Block, 而这个Block会被一个Task 负责计算
2、A function for computing each split
计算每个切片(分区)的函数.
Spark 中 RDD 的计算是以分片为单位的, 每个 RDD 都会实现 compute 函数以达到这个目的.
3、A list of dependencies on other RDD
与其他 RDD 之间的依赖关系
RDD 的每次转换都会生成一个新的 RDD, 所以 RDD 之间会形成类似于流水线一样的前后依赖关系. 在部分分区数据丢失时, Spark 可以通过这个依赖关系重新计算丢失的分区数据, 而不是对 RDD 的所有分区进行重新计算.
4、Optionally, a Partitioner for key-value RDD (e.g. to say that the RDD is hash-partitioned)
对存储键值对的 RDD, 还有一个可选的分区器.
只有对于 key-value的 RDD, 才会有 Partitioner, 非key-value的 RDD 的 Partitioner 的值是 None. Partitiner 不但决定了 RDD 的本区数量, 也决定了 parent RDD Shuffle 输出时的分区数量.
5、Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
存储每个切片优先(preferred location)位置的列表. 比如对于一个 HDFS 文件来说, 这个列表保存的就是每个 Partition 所在文件块的位置. 按照"移动数据不如移动计算"的理念, Spark 在进行任务调度的时候, 会尽可能地将计算任务分配到其所要处理数据块的存储位置.
(二)理解 RDD
一个 RDD 可以简单的理解为一个分布式的元素集合.
RDD 表示只读的分区的数据集,对 RDD 进行改动,只能通过 RDD 的转换操作, 然后得到新的 RDD, 并不会对原 RDD 有任何的影响
在 Spark 中, 所有的工作要么是创建 RDD, 要么是转换已经存在 RDD 成为新的 RDD, 要么在 RDD 上去执行一些操作来得到一些计算结果.
每个 RDD 被切分成多个分区(partition), 每个分区可能会在集群中不同的节点上进行计算.
分区是一个逻辑的结构,只存储当前分区需要处理的数据的相关元数据
二、RDD 特点
1、弹性
存储的弹性:内存与磁盘的自动切换;
容错的弹性:数据丢失可以自动恢复;
计算的弹性:计算出错重试机制;
分片的弹性:可根据需要重新分片。
2、分区
RDD 逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个compute函数得到每个分区的数据。
如果 RDD 是通过已有的文件系统构建,则compute函数是读取指定文件系统中的数据,如果 RDD 是通过其他 RDD 转换而来,则 compute函数是执行转换逻辑将其他 RDD 的数据进行转换。
3、只读
RDD 是只读的,要想改变 RDD 中的数据,只能在现有 RDD 基础上创建新的 RDD。
由一个 RDD 转换到另一个 RDD,可以通过丰富的转换算子实现,不再像 MapReduce 那样只能写map和reduce了。
RDD 的操作算子包括两类:一类叫做transformation,它是用来将 RDD 进行转化,构建 RDD 的血缘关系;另一类叫做action,它是用来触发 RDD 进行计算,得到 RDD 的相关计算结果或者 保存 RDD 数据到文件系统中.
4、依赖(血缘)
RDD 通过操作算子进行转换,转换得到的新 RDD 包含了从其他 RDD 衍生所必需的信息,RDD 之间维护着这种血缘关系,也称之为依赖。
如下图所示,依赖包括两种,
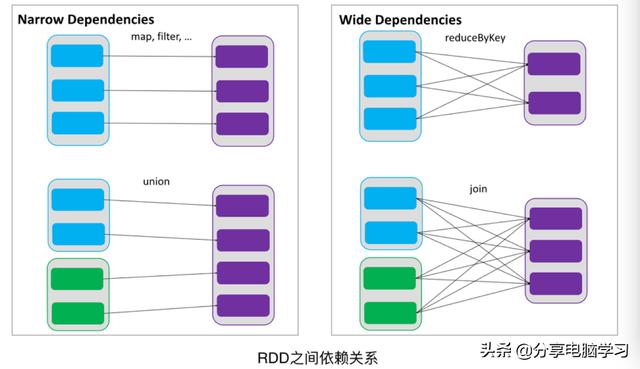
一种是窄依赖,RDD 之间分区是一一对应的,
窄依赖
NarrowDependency
(源码中可以看到OneToOneDependency,RangeDependency)
父RDD中的Partition最多被子RDD的一个Partition所使用(一对一)
常用的API:map、filter、flatMap、union、join(要求两个父RDD具有相同的Partitioner,并且父RDD的分区数一致,并且子RDD的分区器和分区数与父RDD的保持一致)
Sample.txt文件中的内容
aa bb cc aa aa aa dd dd ee ee ee ee
ff aa bb zks
ee kks
ee zz zks
另一种是宽依赖,下游 RDD 的每个分区与上游 RDD(也称之为父RDD)的每个分区都有关,是多对多的关系。
宽依赖ShuffleDependency
一个父RDD的partition都会被多个子RDD的partition使用
常用的API(整理一些常见的API):xxxByKey 、 join(除上述窄依赖情况的join之外的join)、xxxBy、repartition
宽依赖的话会产生shuffle,stage的划分就是看有没有shuffle,如果有的话就会一分为二个stage,否则的话就只有一个stage(运行截图查看stage的变化)
例如下图

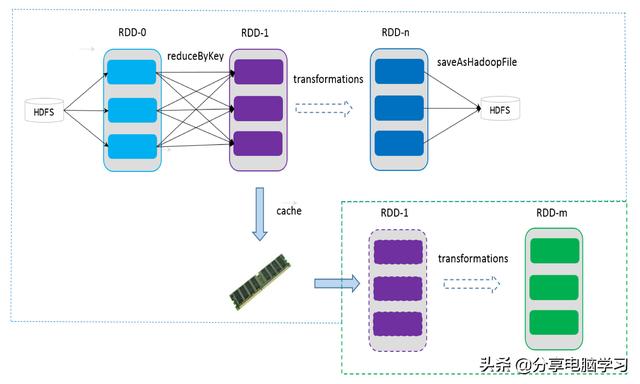
5、缓存
如果在应用程序中多次使用同一个 RDD,可以将该 RDD 缓存起来,该 RDD 只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该 RDD 的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。
如下图所示,RDD-1 经过一系列的转换后得到 RDD-n 并保存到 hdfs,RDD-1 在这一过程中会有个中间结果,如果将其缓存到内存,那么在随后的 RDD-1 转换到 RDD-m 这一过程中,就不会计算其之前的 RDD-0 了。
6、checkpoint
虽然 RDD 的血缘关系天然地可以实现容错,当 RDD 的某个分区数据计算失败或丢失,可以通过血缘关系重建。
但是对于长时间迭代型应用来说,随着迭代的进行,RDD 之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。
为此,RDD 支持checkpoint 将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint 后的 RDD 不需要知道它的父 RDD 了,它可以从 checkpoint 处拿到数据。
三. RDD的两种构建方式
1、将内存中的数据序列化为RDD
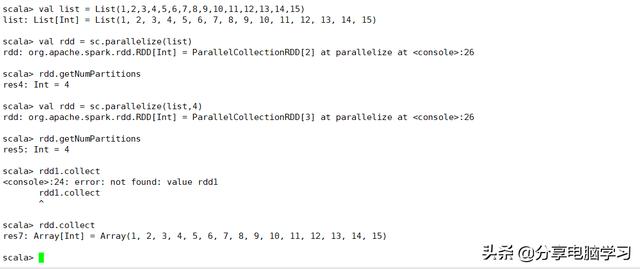
val list = List(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15)
val rdd = sc.parallelize(list)
rdd.getNumPartitions
val rdd = sc.parallelize(list,4)
rdd.getNumPartitions
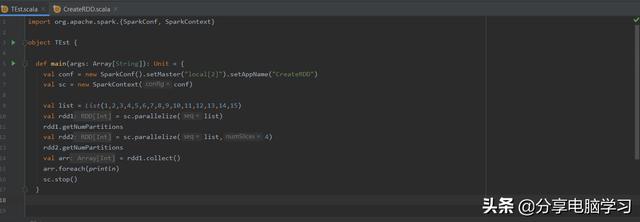
执行结果
在Shell中执行
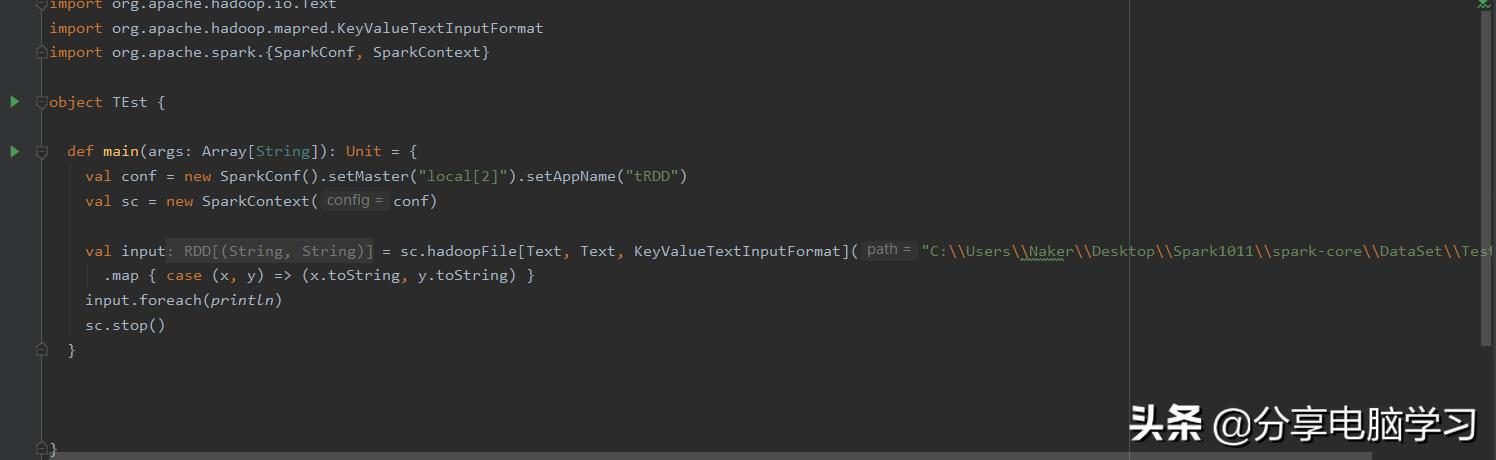
2、外部数据(非内存数据),基于某个给定的InputFormat来读取数据创建RDD
sc.textFile => 底层使用的是旧的mapredAPI,TextInputFormat来读取数据创建RDD

sc.hadoopFile => 底层使用的是旧的mapredAPI来读取数据
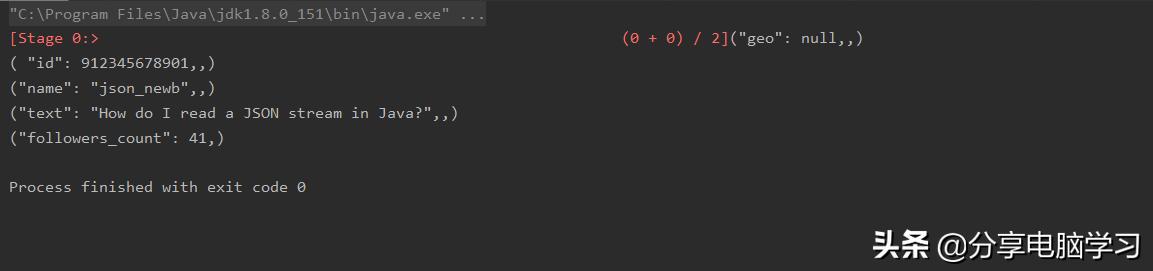
执行结果
sc.newAPIHadoopFile => 底层使用的是新的mapreduceAPI来读取数据
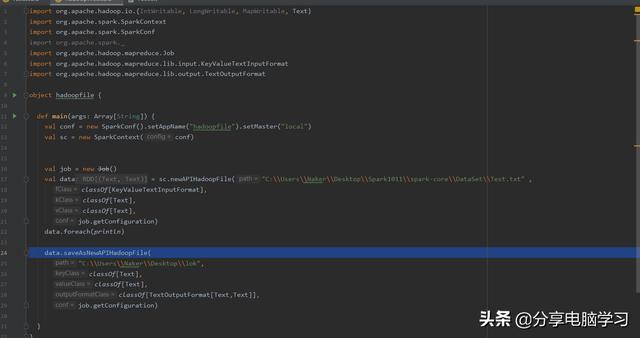
执行结果
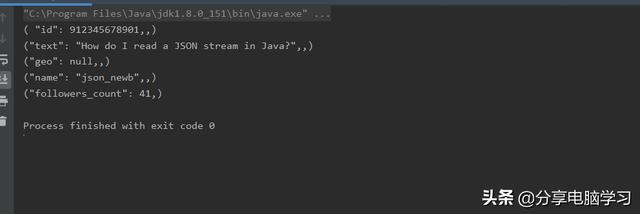
硬盘上的位置

sc.hadoopRDD => 底层使用的是旧的mapredAPI来读取数据
sc.newAPIHadoopRDD ==>底层使用的是新的mapreduceAPI来读取数据
执行结果

四、RDD的API的类型 (3种类型)
(1) transformation算子:转换操作
功能:将一个RDD转换成另一个RDD,这类操作的给定的函数不会立即执行,并且调用这种类型的API不会触发job的执行
在调用这类API的时候,实质上是基于RDD的依赖关系构建了一个DAG依赖图(有向无环图)
该类算子的具体代码是lazy的,只有当job运行的时候,才会提交到executor运行
(2) action算子:动作、操作
功能:触发RDD的job的提交,并且将对应的RDD的DAG图划分为stage,提交到executor进行操作,并且将最终执行的结果返回driver
常用API:collect,take,first。。。
(3) persist(RDD的缓存或者持久化的操作)
功能:将RDD数据缓存到内存或者本地磁盘,清空缓存操作
result.cache
result.persist()
result.unpersist()--清空缓存
五、RDD的数据输出
1. 输出数据到Driver中
相关API: rdd.collect,rdd.take,rdd.count。
底层执行原理:首先得到各个分区的执行结果,然后对各个分区的执行结果进行聚合合并成为最终结果。假设rdd有3个分区,首先会得到每个分区的top10,然后进行聚合,得到三个分区里的总的top10。例如rdd.top(10)的执行
2. 输出到外部系统(HDFS)
rdd.saveAsTextFile
底层调用旧的mapred的TextOutputFormat进行数据的输出
rdd.saveAsHadoopFile
底层调用旧的mapred的OutputFormat进行数据的输出,可以指定具体的OutputFormat

查看一下

3. 输出到数据库














 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









