







点击上方蓝色字体,关注我们
之前一篇文章大致说了下最近正则优化的事,通过拆分超长正则让匹配效率提升近百倍,原文链接:用它匹配大数据长文本,让处理效率提升 100 倍 ~
链接文章中对 AC 多模匹配的方式只是简单的提了下,并没有做出详细的介绍,思路是理清楚了 但是 对于 AC自动机 还是有些模糊,只知道它的基础是 字典树 和 KMP字符串匹配算法,以后总不能一直把它当做黑盒去用吧,所以本文我们就看看 AC 自动机 到底是怎么回事,用它匹配长文本咋就这么快呢。
Q:什么是 KMP 字符串匹配算法呢 ?
A:KMP 字符串匹配算法的目的也是查找字符串,比如说 查找 'abc' 串中是否包含目标字符串 'ab',如果包含则返回包含的起始位置。
KMP 算法会设置一个 next 指针,它的核心思想就是比过的字符串就不比了,而不是简单的暴力循环遍历查找。
KMP 算法是单模式匹配,AC 自动机匹配是多模式匹配,可以说 AC 自动机匹配是 KMP 算法的升级,单模式匹配与多模式匹配的不同点在于单模式匹配是搜索一个关键字,多模式匹配是搜索多个关键字。
它们的共同之处 都有个 next 指针,AC 自动机 匹配效率高的原因除了它将字符做成字典树,由横向结构变为纵向之外,一个更重要的原因就是它的失败匹配机制,个人认为 AC 自动机匹配机制核心应该就是 匹配失败走失败指针匹配。
AC 多模匹配算法大致可以分为 3 个部分:
构建字典树
设置失败指针
多模匹配过程
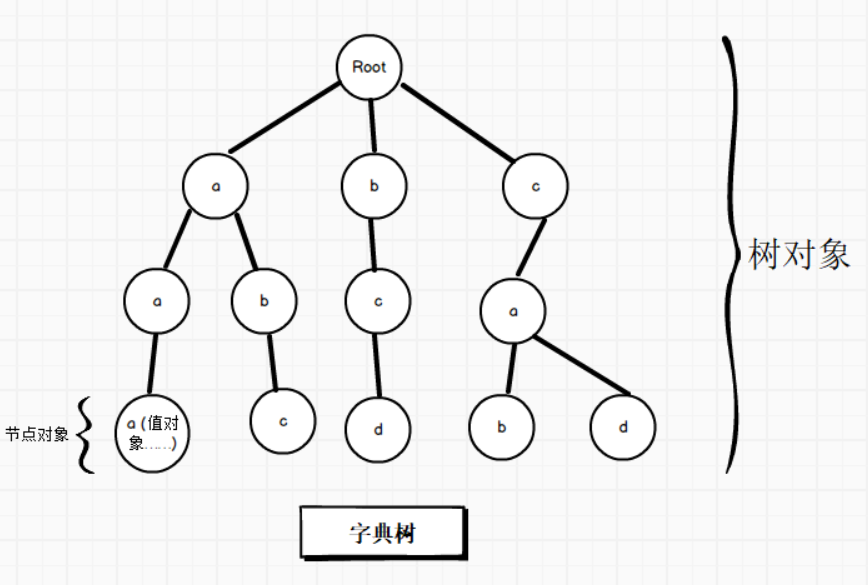
字典树的构建过程是是这样的:
当要往树中插入大量文本时,将文本按字符拆分计算,从前往后依次插入,当发现要插入的字符在其前一个字符的节点下没有节点与之相符,则需要创建新节点表示这个字符;如果发现其前节点下有与之相符的节点,则直接跳过,继续插入下一个节点。之后重复以上操作,直到遍历结束。
0 1字典树包含的对象
字典树的构建包括如下三个部分:
字典树对象,包含一个个的树节点
树节点对象,包含一个个的节点值对象
节点值对象,包含了值的起始、终止下标以及实际存储的值
以上三种对象有着明显的父子关系,树包含节点,节点包含值,构建出字典树,图示如下:
字典树构建参考代码
1 字典树对象,字典树对象是对外暴露的对象,后续所有 AC 匹配的方法都在此对象中声明:
添加模式串方法
设置失败指针方法
模式匹配方法
public class ACTrie { //是否建立了failure表 private Boolean failureStatesConstructed = false; //根结点 private Node root; public ACTrie() { this.root = new Node(true); } /** * 添加一个模式串 * @param keyword */ public void addKeyword(String keyword) {} /** * 建立失败指针方法 */ private void constructFailureStates() {} /** * 模式匹配方法 * * @param text 待匹配的文本 * @return 匹配到的模式串 */ public Collection parseText(String text) {} }2 树节点对象,树节点对象的方法主要有:
节点新增方法
跳转到下一个节点方法
private static class Node{ //构建字符与节点的关系 private Map map; //节点中存入的所有数值 private List emits; //失败指针指向的节点 private Node failure; //判断此节点是否为根结点 private Boolean isRoot = false; public Node(){ map = new HashMap<>(); emits = new ArrayList<>(); } public Node(Boolean isRoot) { this(); this.isRoot = isRoot; } //节点新增方法 public Node insert(Character character) { Node node = this.map.get(character); if (node == null) { node = new Node(); map.put(character, node); } return node; } //记录所有添加的值 配合节点新增方法使用 public void addEmit(String keyword) { emits.add(keyword); } public void addEmit(Collection keywords) { emits.addAll(keywords); } /** * success跳转 * @param character * @return */ public Node find(Character character) { return map.get(character); } /** * 跳转到下一个节点 * @param transition 接受字符 * @return 跳转结果 */ private Node nextState(Character transition) { Node state = this.find(transition); // 先按success跳转 if (state != null) { return state; } //如果跳转到根结点还是失败,则返回根结点 if (this.isRoot) { return this; } // 跳转失败的话,按failure跳转 return this.failure.nextState(transition); } public Collection children() { return this.map.values(); } //设置失败指针节点 public void setFailure(Node node) { failure = node; } //获取失败节点 public Node getFailure() { return failure; } //返回节点下所有记录键 public Set getTransitions() { return map.keySet(); } //返回节点下所有记录的值 public Collection emit() { return this.emits == null ? Collections.emptyList() : this.emits; } }3 节点值对象
public class Emit{ //匹配到的模式串 private final String keyword; //匹配到的模式串起始下标 private final int start; //匹配到的模式串终止下标 private final int end; /** * 构造一个模式串匹配结果 * @param start 起点 * @param end 终点 * @param keyword 模式串 */ public Emit(final int start, final int end, final String keyword) { this.start = start; this.end = end; this.keyword = keyword; } /** * 获取对应的模式串 * @return 模式串 */ public String getKeyword() { return this.keyword; } }设置失败指针可以分为两步 :
将深度为 1 的节点的失败指针直接指向父节点也就是根节点
这一步比较简单,因为深度为 1 的节点如果查找失败,只能往上一层找,也就是往根节点找。
为深度 > 1 的节点建立失败指针
深度大于1的节点失败指针的构建过程
深度大于1的节点构造失败指针的过程概况如下:
设一个节点的上的值为 c ,记为 start 节点 ,沿着它父节点的失败指针走,直到走到一个节点它的儿子节点中也有值为 c 的节点,将儿子节点记为 end 节点。然后把 start 节点的失败指针指向 end 节点即可。
如果一直走到 root 节点都没有找到,那就把 start 节点的失败指针指向 root 节点。
为了方便查看,我将上面链接文章的设置失败指针的图再拿下来,以深度3中的值为C的节点为例,走一下它的失败指针:
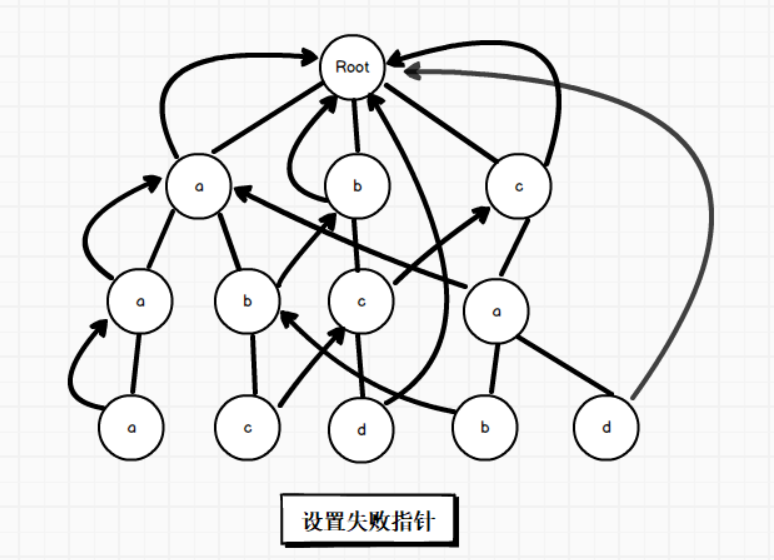
记 深度3中的值为C 的节点 为 start,沿着它父节点(深度为2的值为b的节点)的失败指针走,找到深度为1的值为b的节点,发现它的儿子节点中也有值为C的节点,儿子节点记为 end 节点,此时将 start 节点的失败指针指向 end 节点即可。
同理,深度3中的值为b的节点设置过程也是如此,沿着它父节点(深度为2的值为a的节点)的失败指针走,找到深度为1的值为a的节点,发现它的儿子节点中也有值为b的节点,儿子节点记为 end 节点,此时将 start 节点的失败指针指向 end 节点即可。
d 节点由于一直找到根节点都没有匹配,所以它的失败指针指向了根节点。
02设置失败指针参考代码
设置失败指针的方法在树对象中,设置失败指针应该在匹配文章内容之前进行,参考代码如下:
/** * 设置失败指针 */ private void constructFailureStates() { Queue queue = new LinkedList<>(); // 第一步,将深度为1的节点的failure设为根节点 //特殊处理:第二层要特殊处理,将这层中的节点的失败路径直接指向父节点(也就是根节点)。 for (Node depthOneState : this.root.children()) { depthOneState.setFailure(this.root); queue.add(depthOneState); } this.failureStatesConstructed = true; // 第二步,为深度 > 1 的节点建立failure表,这是一个bfs 广度优先遍历 /** * 构造失败指针的过程概括起来就一句话:设这个节点上的字母为C,沿着他父亲的失败指针走,直到走到一个节点,他的儿子中也有字母为C的节点。 * 然后把当前节点的失败指针指向那个字母也为C的儿子。如果一直走到了root都没找到,那就把失败指针指向root。 * 使用广度优先搜索BFS,层次遍历节点来处理,每一个节点的失败路径。 */ while (!queue.isEmpty()) { Node parentNode = queue.poll(); for (Character transition : parentNode.getTransitions()) { Node childNode = parentNode.find(transition); queue.add(childNode); Node failNode = parentNode.getFailure().nextState(transition); childNode.setFailure(failNode); childNode.addEmit(failNode.emit()); } } }AC 多模匹配过程
当AC自动机初始化完成并且设置好节点失败指针后,就可以使用 AC自动机 进行模式匹配了,模式匹配分为字符匹配和字符不匹配两种情况:
当前字符匹配
表示从当前节点沿着树边有一条路径可以到达目标字符,此时只需沿该路径走向下一个节点继续匹配即可,目标字符串指针移向下个字符继续匹配;
当前字符不匹配
如果当前字符不匹配则去当前节点的失败指针所指向的节点继续匹配,匹配过程随着失败指针的指向走,一直走到失败指针指向根节点结束。
使用自动机匹配模式串是,重复以上这 2 个过程中的任意一个,直到模式串走到结尾为止。
02模式匹配参考代码
/** * 模式匹配 * * @param text 待匹配的文本 * @return 匹配到的模式串 */public CollectionparseText(String text) { //检查是否进行了失败指针设置过程 checkForConstructedFailureStates(); Node currentState = this.root; //开始模式匹配 List collectedEmits = new ArrayList<>(); // 按字符拆分 for (int position = 0; position < text.length(); position++) { Character character = text.charAt(position); //通过字符查找下一个节点 currentState = currentState.nextState(character); Collection emits = currentState.emit(); if (emits == null || emits.isEmpty()) { continue; } for (String emit : emits) { collectedEmits.add(new Emit(position - emit.length() + 1, position, emit)); } } return collectedEmits;}/** * 检查是否建立了失败指针 */private void checkForConstructedFailureStates() { //树对象中会记录 失败指针是否设置 的标识,通过表示判断 if (!this.failureStatesConstructed) { constructFailureStates(); }}至此,AC 自动机的匹配机制我们了解完了,它的重点还是在于失败指针的设置过程。
了解了失败指针的设置与匹配的原理以后,现在再用是不是就感觉得心应手了呢,还不了解怎么实际使用的小伙伴,这里有个不错的入门案例,也是文章开始提到的 用它匹配大数据长文本,让处理效率提升 100 倍 ~ ,结合这篇文章再复盘一下,相信会对你有所帮助。
PS: 关注公众号, 后台回复 "正则优化",可领取文中代码资料。
— THE END —▼往期精彩回顾▼用它匹配大数据长文本,让处理效率提升 100 倍 ~大数据存储- Hbase 整合 Hdoop、Hive这些 Hive 基础知识,你还记得吗大数据存储- Hbase 基础Phoenix - sql on hbaseHadoop 压缩实战聊聊那些从没听说过的并发的名词-管程搞懂微服务和大数据,从捕捉一头野猪说起长按关注,解锁更多精彩内容
 公众号可以留言啦,所有的留言都在这里哦 ?
公众号可以留言啦,所有的留言都在这里哦 ? 点我写留言














 2702
2702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









