







分布表示(distributed representation)与深度神经网络(deep neural network)极大地推动了近几年自然语言处理研究的发展。我们知道,分布表示指的是对于一个客观描述对象的低维、稠密、连续向量表示。不同于符号表示(symbolic representation),分布表示可以自然地联结表现形式不同但语义空间相同(或相似)的对象,比如不同模态数据(图像、文本、语音)以及不同语言的数据等。近年来,很多研究致力于跨语言分布表示学习,即:将不同语言的词语嵌入至一个统一的向量空间之内,使得语义相似(单语及跨语言)的词在该向量空间内距离接近,如图1所示。跨语言分布表示为不同语言的数据资源之间建立了一座桥梁,为跨语言的迁移学习提供了一种有效的途径,进而为很多跨语言应用(比如对于资源稀缺语言的文本分类、句法分析,以及机器翻译等)带来显著的推动作用。
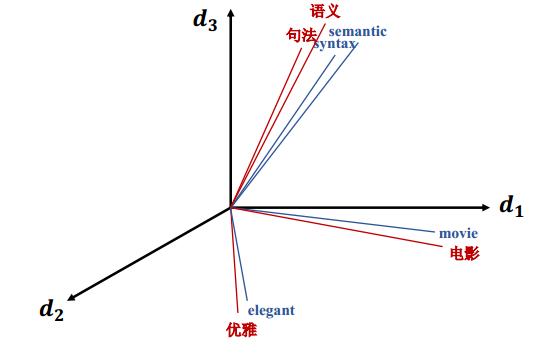
Figure 1: 跨语言词汇分布表示(三维空间下的示意)
本文首先描述典型的跨语言分布表示学习方法,再简单介绍其应用场景。
1 跨语言分布表示学习
根据学习方式的不同,可以将现有的跨语言分布表示学习分为两类,分别是:1. 基于线下处理的方法;2. 基于联合学习的方法。接下来我们对这两类方法中较为典型的模型进行介绍。
1.1 线下处理方法
线下处理方法的基本思路是先独立学习各个语言的词汇分布表示,然后对两者进行对齐。Mikolov等发现,使用word2vec学习得到的不同语言的分布表示之间存在一定程度上的线性映射关系(类似于同种语言下的word analogy性质)(见图2), 于是提出“翻译矩阵”学习的方法来实现跨语言分布表示的映射 (Mikolov et al., 2013)。
Figure 2: 英语与法语词表示示例(数字、动物)
具体地,给定一个翻译词对的集合
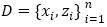
(即双语词典,其中i为源语言中第i个词,zi为目标语言中与xi互为翻译的词),D中词对所对应的分布表示矩阵分别记为

以及
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









