






在《Linux实现的ARP缓存老化时间原理解析》一文中,我剖析了Linux协议栈IPv4的邻居子系统的转化,再次贴出那个状态机转化图,可是这个图更详细了些,因为它有一个外部输入,那就是confirm:
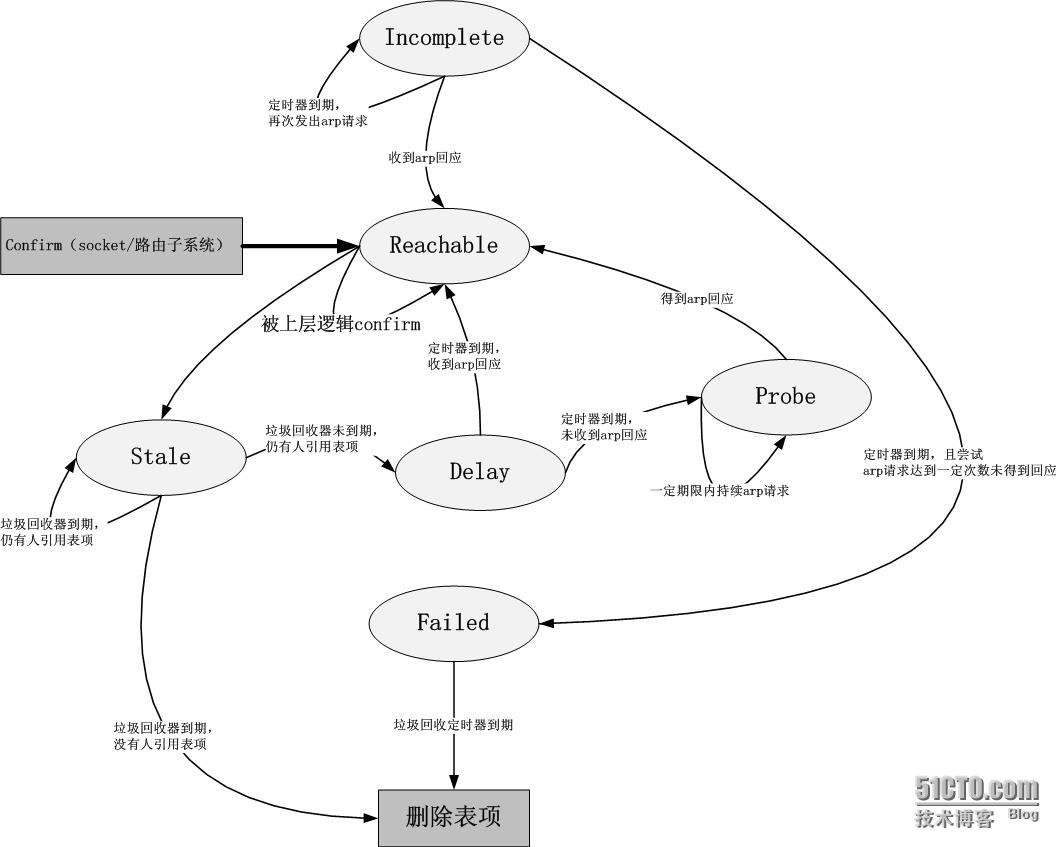
请注意,如果socket或者路由子系统在上层confirm了一个neighbour,那么该arp将持续留在reachable状态而可以不用转换到stale状态。这个特性是有意义的。请观察一个现象:
1.本机IP地址为192.168.1.10/24,直连的机器IP地址为192.168.1.20/24,从本机ping对端;
2.将本机的/proc/sys/net/ipv4/neigh/eth0/base_reachable_time设置为4秒,对端的对应值设置为8秒;
3.抓包发现每隔8秒左右会有一个一个arp request从对端发来,符合上述的图示;
4.抓包始终未见有本端到对端的arp request,按说应该每隔4秒左右发出一个的啊;
5.修改对端设备的IP地址为192.168.1.30/24,本端在间隔4秒左右后,马上发出了arp request;
以上现象有2个疑点:为何本端在reachable状态到期了仍然不切换状态,不重新解析对端IP地址?为何对端的IP地址修改掉或者删除掉之后,本端马上发现了这一事实,间隔reachable到期时间后发出了arp request?
要澄清上述两个疑点,就要从下向上来逐步定位,当我设置了iptables规则在INPUT上禁止ping
reply接收时,和修改删除对端IP的效果一样,ping马上发现了这一点,间隔4秒左右发出了arp
request。因此问题就在ping本身,对ping进行strace,发现其sendmsg的最后一个参数为MSG_CONFIRM,查阅man手
册,发现:
MSG_CONFIRM (Since Linux 2.3.15)
Tell the link layer that forward progress happened: you got a successful reply from the other side. If the link
layer doesn't get this it will regularly reprobe the neighbor (e.g., via a unicast ARP). Only valid on SOCK_DGRAM
and SOCK_RAW sockets and currently only implemented for IPv4 and IPv6. See arp(7) for details.
由
于对端只是接收ping request,进而直接在协议栈中回应ping
reply,因此不会涉及socket,并且也没有涉及路由子系统中关于redirect等关联的confirm,因此对端严格按照IPv4邻居子系统的
状态图转换,而本端则每每收到ping reply,就会confirm,进而使arp表项维持在reachable状态,一旦收不到ping
reply,便不会再confirm,等到reachable状态到期,便进入短暂的stale,delay状态了,进而进入probe发出arp
request。
说了这么多关于arp的一个细节,旨在解释一个tap模式的Open×××运行在multi模式,即server模式时的MAC地址学习的问题。
我们知道,Open×××在tap模式下可以看作一个虚拟的交换机,而且是学习型的,它学习的内容为:为每一个multi_instance关联一个
MAC地址链表,凡是来自该multi_instance的以太帧的源MAC地址都会进入这个链表。这个链表的作用在于为从Open×××服务端返回到客
户端的数据包关联一个multi_instance。对于一个从Open×××服务端发往客户端方向的数据包,其目的MAC地址肯定在某一个
Open×××客户端后面或者是Open×××客户端的tap网卡本身。Open×××服务端用这个MAC地址作为键值检查MAC/instance表,
最终找出一个multi_instance发送出去。
现在考虑一个主动从Open×××服务端发送的数据包,当它到Open×××进程的时候,由于事先没有从Open×××客户端过来的任何数据包供
Open×××服务端学习,因此数据包必须丢弃,因为它无法对应到任何一个multi_instance。是这样吗?NO!因为你没有考虑到arp。在以
太网发送任何数据包之前,都要经过arp解析对端的IP地址,而arp请求是广播,将发送到所有的multi_instance,只有有来自某个
Open×××客户端方向的arp回应,Open×××服务端将会学习到一条MAC/instance表项。因此不存在数据包被drop的可能。
但是,如果Open×××服务端后面的机器发送数据包的时候,IP/MAC地址映射已经存在了,那么就不会发送arp请求了,也就没有机会让
Open×××服务端从arp回应中学习了,此时数据包将会被丢弃。是这样吗?是的,但是如果你看懂了IPv4邻居子系统的状态转换图,就会等待
reachable到期时间后再次重试。由于根本不可能有数据从Open×××客户端发来,因此就没有机会被confirm,所有最久的等待时间就是
reachable+stale+delay的定时器时间和。然而有一种情况,如果服务端这边设置了一条永久的arp表项,那就完蛋了。
Open×××运行在tap模式时,可以通过arp来自动学习MAC/instance映射,那么运行在tun模式下呢?由于IPv4除了DHCP等不具
备任何自动配置机制,且DHCP又不是必须使用的,因此只能手工配置,这个在Open×××中就是iroute选项,即Internal route。
自动学习比较不易,那么如果你仅仅只是为了使用Open×××连接两个远程网络,那么就别用server模式了,使用p2p,即pointopoint模式比较好,它只是进行简单的tun-link-link-tun的转发而已。















 1378
1378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









